Scaling Performance of Large Language Model Pretraining
作者: Alexander Interrante-Grant, Carla Varela-Rosa, Suhaas Narayan, Chris Connelly, Albert Reuther
分类: cs.DC, cs.AI
发布日期: 2025-09-05 (更新: 2025-10-09)
期刊: Proc. IEEE High Performance Extreme Computing Conference (HPEC), 2025
💡 一句话要点
揭秘LLM预训练:大规模分布式训练与数据并行性能优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练 分布式训练 数据并行 GPU优化 性能扩展 计算效率
📋 核心要点
- 现有LLM训练缺乏公开的性能扩展信息,阻碍了研究人员和工程师优化训练过程。
- 本文旨在通过分析分布式训练和数据并行,揭示LLM预训练流水线的关键要素。
- 研究重点在于大规模数据集管理和GPU计算资源的充分利用,为LLM训练提供实用指导。
📝 摘要(中文)
大型语言模型(LLM)在各种自然语言处理应用中表现出卓越的性能。训练这些模型需要极高的计算成本;领先的人工智能研究公司正在投入数十亿美元用于超级计算基础设施,以便在日益庞大的数据集上训练越来越大的模型。然而,关于这些大型训练流水线的扩展性能和训练考虑因素的公开信息非常少。处理超大数据集和模型可能非常复杂,并且在公开文献中,关于调整训练性能以扩展大型语言模型的实用建议很少。本文旨在揭示大型语言模型预训练流水线的一些神秘之处——特别是关于分布式训练、跨数百个节点管理大型数据集以及扩展数据并行性,重点是充分利用可用的GPU计算能力。
🔬 方法详解
问题定义:大规模语言模型(LLM)的预训练需要巨大的计算资源和海量的数据集。现有的公开文献缺乏关于如何有效扩展训练过程,充分利用分布式计算资源,以及优化数据并行策略的详细指导,导致研究人员和工程师难以高效地训练大型模型。
核心思路:本文的核心思路是通过深入分析LLM预训练过程中的关键瓶颈,例如分布式训练中的通信开销和数据并行中的资源利用率,从而提出优化策略。重点关注如何有效地管理大规模数据集,以及如何最大限度地利用可用的GPU计算资源。
技术框架:本文主要关注LLM预训练的分布式训练和数据并行部分。具体的技术框架包括:数据加载和预处理模块,负责将大规模数据集高效地分发到各个计算节点;模型并行和数据并行模块,负责将模型和数据分割到不同的GPU上进行并行计算;通信模块,负责在不同的计算节点之间进行梯度同步和参数更新。
关键创新:本文的关键创新在于对LLM预训练过程中的性能瓶颈进行了深入分析,并提出了相应的优化策略。例如,通过优化数据加载和预处理流程,减少数据I/O的开销;通过调整数据并行策略,提高GPU的利用率;通过优化通信协议,减少分布式训练中的通信开销。
关键设计:本文的关键设计包括:针对大规模数据集的数据分片策略,确保每个计算节点都能高效地访问数据;针对不同模型结构的并行策略,例如模型并行和数据并行的组合使用;针对不同硬件环境的通信优化策略,例如使用RDMA等技术减少通信延迟。
🖼️ 关键图片
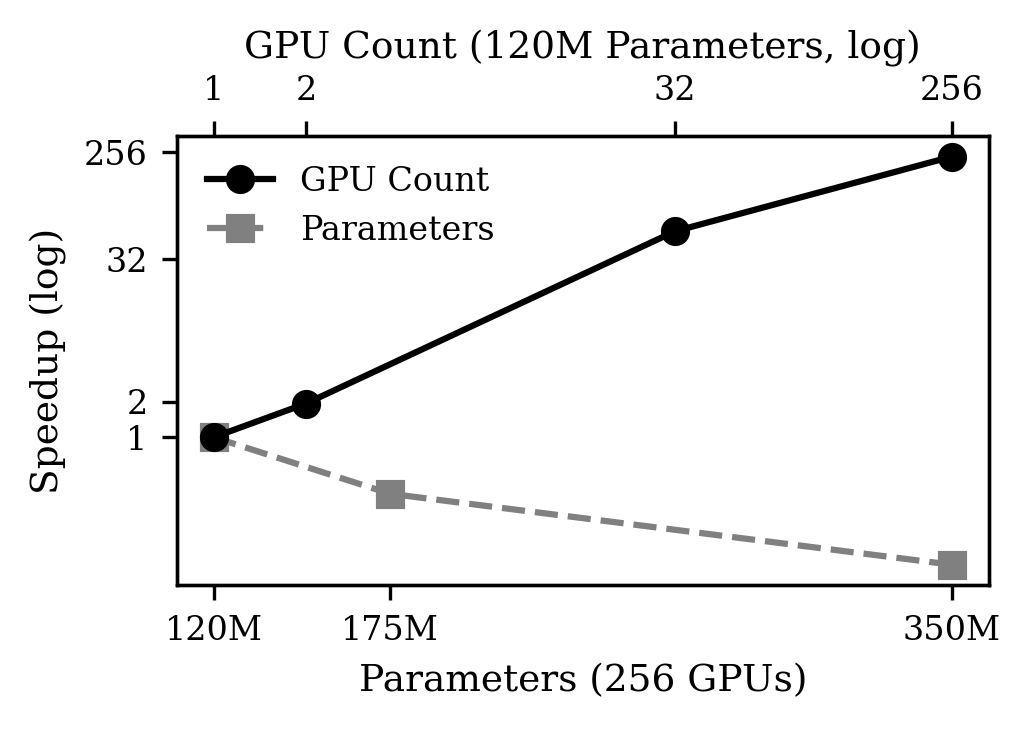
📊 实验亮点
本文重点在于对大规模LLM预训练的分析和优化,虽然没有提供具体的性能数据,但强调了分布式训练、数据并行和GPU资源利用率的重要性。研究结果为优化LLM训练流水线提供了有价值的指导,有助于研究人员和工程师更有效地训练大型模型。
🎯 应用场景
该研究成果可应用于大规模语言模型的预训练,例如GPT系列、BERT系列等。通过优化训练过程,可以降低训练成本,缩短训练时间,并提高模型的性能。此外,该研究还可以为其他需要大规模分布式训练的机器学习任务提供参考。
📄 摘要(原文)
Large language models (LLMs) show best-in-class performance across a wide range of natural language processing applications. Training these models is an extremely computationally expensive task; frontier Artificial Intelligence (AI) research companies are investing billions of dollars into supercomputing infrastructure to train progressively larger models on increasingly massive datasets. Unfortunately, very little information about the scaling performance and training considerations of these large training pipelines is released publicly. Working with very large datasets and models can be complex and practical recommendations are scarce in the public literature for tuning training performance when scaling up large language models. In this paper, we aim to demystify the large language model pretraining pipeline somewhat - in particular with respect to distributed training, managing large datasets across hundreds of nodes, and scaling up data parallelism with an emphasis on fully leveraging available GPU compute capacity.