Internet 3.0: Architecture for a Web-of-Agents with it's Algorithm for Ranking Agents
作者: Rajesh Tembarai Krishnamachari, Srividya Rajesh
分类: cs.AI
发布日期: 2025-09-05
💡 一句话要点
提出DOVIS协议和AgentRank-UC算法,实现Web of Agents中Agent的动态、可信排序。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent排序 Web of Agents 大型语言模型 隐私保护 信任机制
📋 核心要点
- 现有Agent排序方法缺乏全局视角,无法有效利用分散且私有的使用信号,导致排序不准确。
- 论文提出DOVIS协议,旨在收集保护隐私的使用和性能数据,并设计AgentRank-UC算法进行动态排序。
- 仿真结果表明,该方法在收敛性、鲁棒性和抗Sybil攻击方面具有理论保证,验证了其可行性。
📝 摘要(中文)
人工智能Agent,由具备推理能力的大型语言模型(LLM)驱动,并与工具、数据和网络搜索集成,有望将互联网转变为一个“Agent网络”:一个机器原生的生态系统,其中自主Agent大规模地交互、协作和执行任务。实现这一愿景需要“Agent排序”——不仅根据声明的能力选择Agent,还要根据已证实的、最近的表现选择。与Web 1.0的PageRank不同,Agent交互的全局、透明网络并不存在;使用信号是分散和私有的,使得在没有协调的情况下进行排序是不可行的。我们提出了DOVIS,一个五层操作协议(发现、编排、验证、激励、语义),它能够收集整个生态系统中最小的、保护隐私的使用和性能聚合。在此基础上,我们实现了AgentRank-UC,一种动态的、信任感知的算法,它将“使用”(选择频率)和“能力”(结果质量、成本、安全性、延迟)结合成一个统一的排名。我们展示了仿真结果和关于收敛性、鲁棒性和Sybil攻击抵抗的理论保证,证明了协调协议和性能感知排名在实现可扩展、可信的Agent网络中的可行性。
🔬 方法详解
问题定义:论文旨在解决Web of Agents中Agent排序的问题。现有方法无法有效利用分散且私有的使用信号,导致排序结果不准确,无法反映Agent的真实能力和表现。此外,缺乏全局视角和协调机制,使得构建可信的Agent网络面临挑战。
核心思路:论文的核心思路是通过设计一个协调协议(DOVIS)来收集必要的Agent使用和性能数据,并在保护隐私的前提下,利用这些数据进行动态的、信任感知的Agent排序。AgentRank-UC算法则将使用频率和能力指标(质量、成本、安全、延迟)相结合,从而更全面地评估Agent的价值。
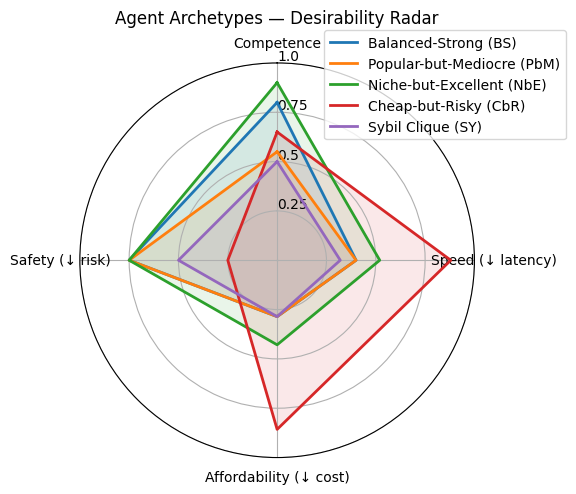
技术框架:整体框架包含五个层次,即DOVIS协议的五个层:1) Discovery(发现):Agent的注册和发现机制;2) Orchestration(编排):Agent任务的分配和协调;3) Verification(验证):Agent执行结果的验证和评估;4) Incentives(激励):激励Agent提供高质量服务的机制;5) Semantics(语义):Agent之间进行语义理解和交互的协议。AgentRank-UC算法则基于DOVIS协议收集的数据,动态计算Agent的排名。
关键创新:关键创新在于DOVIS协议的设计,它能够在保护隐私的前提下,收集Agent的使用和性能数据,为Agent排序提供依据。AgentRank-UC算法则将使用频率和能力指标相结合,从而更全面地评估Agent的价值,并引入信任机制,提高排序的鲁棒性。
关键设计:DOVIS协议的关键设计在于其隐私保护机制,例如使用差分隐私等技术来保护Agent的敏感数据。AgentRank-UC算法的关键设计在于如何平衡使用频率和能力指标,以及如何动态调整信任参数,以适应Agent网络的变化。具体的参数设置和损失函数等细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
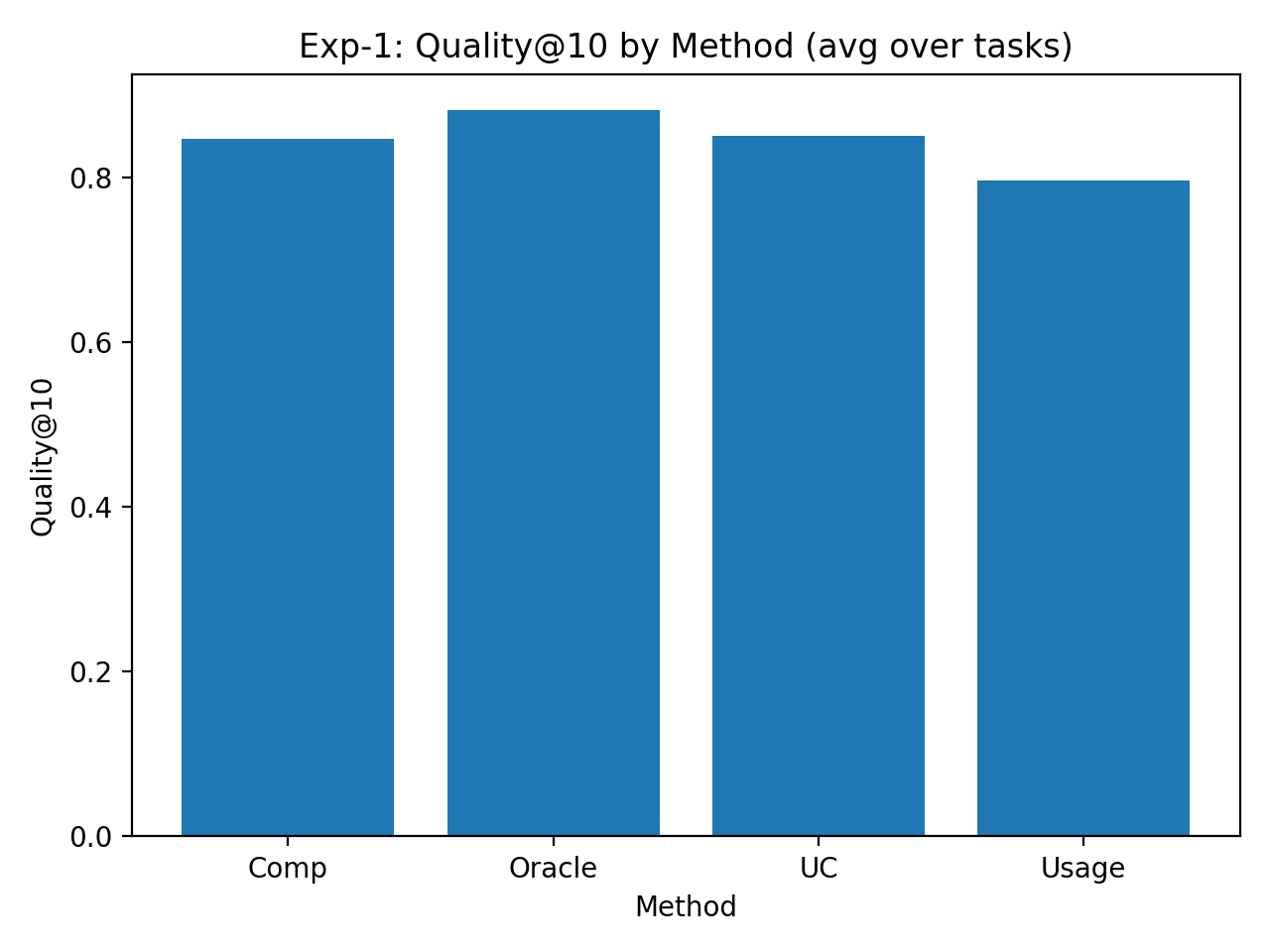
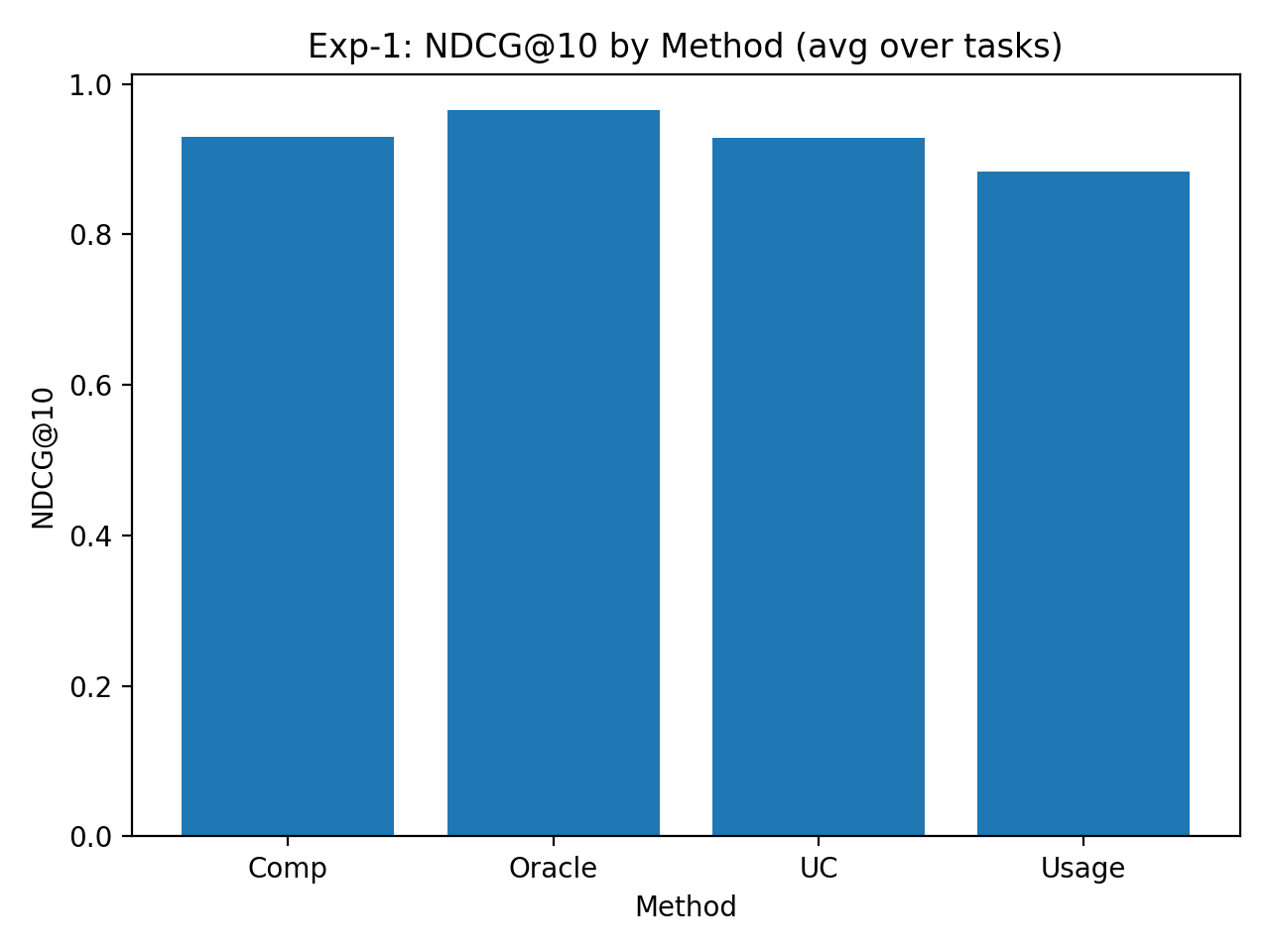
论文通过仿真实验验证了DOVIS协议和AgentRank-UC算法的有效性。实验结果表明,该方法在收敛性、鲁棒性和抗Sybil攻击方面具有理论保证,能够有效地对Agent进行排序,并提高Agent网络的整体性能。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于构建可信赖的Agent网络,例如智能客服、自动化任务处理、智能推荐等领域。通过对Agent进行有效排序,可以提高任务完成的效率和质量,降低成本,并增强用户对Agent网络的信任。未来,该技术有望推动人工智能在各个领域的广泛应用。
📄 摘要(原文)
AI agents -- powered by reasoning-capable large language models (LLMs) and integrated with tools, data, and web search -- are poised to transform the internet into a \emph{Web of Agents}: a machine-native ecosystem where autonomous agents interact, collaborate, and execute tasks at scale. Realizing this vision requires \emph{Agent Ranking} -- selecting agents not only by declared capabilities but by proven, recent performance. Unlike Web~1.0's PageRank, a global, transparent network of agent interactions does not exist; usage signals are fragmented and private, making ranking infeasible without coordination. We propose \textbf{DOVIS}, a five-layer operational protocol (\emph{Discovery, Orchestration, Verification, Incentives, Semantics}) that enables the collection of minimal, privacy-preserving aggregates of usage and performance across the ecosystem. On this substrate, we implement \textbf{AgentRank-UC}, a dynamic, trust-aware algorithm that combines \emph{usage} (selection frequency) and \emph{competence} (outcome quality, cost, safety, latency) into a unified ranking. We present simulation results and theoretical guarantees on convergence, robustness, and Sybil resistance, demonstrating the viability of coordinated protocols and performance-aware ranking in enabling a scalable, trustworthy Agentic Web.