The Physical Basis of Prediction: World Model Formation in Neural Organoids via an LLM-Generated Curriculum
作者: Brennen Hill
分类: cs.NE, cs.AI, cs.LG, q-bio.NC
发布日期: 2025-09-04 (更新: 2025-11-04)
备注: Published in the proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: Scaling Environments for Agents (SEA). Additionally accepted for presentation in NeurIPS 2025 Workshop: Embodied World Models for Decision Making
💡 一句话要点
利用LLM生成课程,在神经类器官中构建世界模型的物理基础研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经类器官 世界模型 大型语言模型 强化学习 具身智能 计算神经科学 突触可塑性
📋 核心要点
- 现有具身智能体缺乏在生物基质中构建和适应世界模型的研究,难以理解智能的物理基础。
- 利用大型语言模型自动生成课程,在神经类器官中训练世界模型,并探究学习的突触机制。
- 设计了三个难度递增的虚拟环境,并提出多模态评估策略,以量化学习到的世界模型的物理相关性。
📝 摘要(中文)
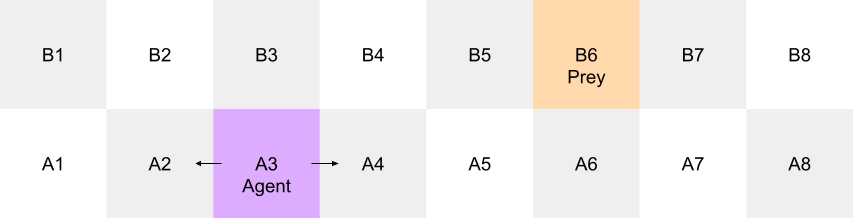
本文介绍了一种新颖的框架,用于研究生物基质(人类神经类器官)中世界模型的形成和适应。我们提出了一个由三个可扩展的闭环虚拟环境组成的课程,旨在训练这些生物智能体,并探索学习的潜在突触机制,如长期增强(LTP)和长期抑制(LTD)。我们详细设计了三个不同的任务环境,这些环境需要越来越复杂的世界模型才能成功决策:(1)用于学习静态状态-动作条件的条件回避任务;(2)用于目标导向交互的一维捕食者-猎物场景;(3)用于建模动态、连续时间系统的经典Pong游戏。对于每个环境,我们形式化了状态和动作空间、感觉编码和运动解码机制,以及基于可预测(奖励)和不可预测(惩罚)刺激的反馈协议,这些协议用于驱动模型改进。作为一项重要的方法学进展,我们提出了一种元学习方法,其中大型语言模型自动执行实验协议的生成设计和优化,从而扩展了环境和课程设计的过程。最后,我们概述了一种多模态评估策略,该策略超越了任务性能,通过量化电生理、细胞和分子水平的突触可塑性,直接测量学习到的世界模型的物理相关性。这项工作弥合了基于模型的强化学习和计算神经科学之间的差距,为研究具身认知、决策和智能的物理基础提供了一个独特的平台。
🔬 方法详解
问题定义:论文旨在研究如何在生物基质(人类神经类器官)中构建和适应世界模型,从而理解智能的物理基础。现有方法缺乏在生物系统中研究世界模型形成和适应的有效手段,难以揭示智能的生物学机制。
核心思路:论文的核心思路是利用闭环虚拟环境训练神经类器官,使其学习预测和交互,从而构建世界模型。通过设计不同难度的任务,逐步提升类器官的学习能力。同时,利用大型语言模型(LLM)自动化生成和优化实验协议,提高实验效率和可扩展性。
技术框架:整体框架包含三个主要模块:1) 虚拟环境设计:设计三个难度递增的虚拟环境,包括条件回避任务、捕食者-猎物场景和Pong游戏。2) 感觉编码和运动解码:建立虚拟环境与神经类器官之间的接口,实现感觉信息的编码和动作的解码。3) 训练和评估:利用奖励和惩罚机制训练神经类器官,并通过多模态评估策略量化学习到的世界模型的物理相关性。
关键创新:最重要的技术创新点在于利用大型语言模型(LLM)自动化生成和优化实验协议。这使得环境和课程设计过程更加高效和可扩展,能够快速探索不同的训练策略和环境配置。此外,多模态评估策略能够直接测量学习到的世界模型的物理相关性,为理解智能的生物学机制提供了新的视角。
关键设计:在虚拟环境设计方面,三个任务难度递增,逐步引导神经类器官学习更复杂的世界模型。感觉编码和运动解码机制的设计需要考虑生物系统的特性,例如神经元放电模式和突触连接。奖励和惩罚机制的设计需要能够有效地驱动类器官的学习过程。LLM在生成实验协议时,需要考虑任务目标、环境参数和类器官的特性。
🖼️ 关键图片


📊 实验亮点
论文提出了一个利用LLM自动生成课程来训练神经类器官的新框架。通过三个难度递增的虚拟环境,成功地训练了神经类器官,并利用多模态评估策略量化了学习到的世界模型的物理相关性。该研究为理解智能的生物学机制提供了新的视角。
🎯 应用场景
该研究成果可应用于类器官智能、生物计算和神经科学等领域。通过理解神经类器官中世界模型的形成和适应机制,可以为开发新型生物计算机和人工智能系统提供新的思路。此外,该研究还有助于深入理解人类智能的生物学基础,为治疗神经系统疾病提供新的方法。
📄 摘要(原文)
The capacity of an embodied agent to understand, predict, and interact with its environment is fundamentally contingent on an internal world model. This paper introduces a novel framework for investigating the formation and adaptation of such world models within a biological substrate: human neural organoids. We present a curriculum of three scalable, closed-loop virtual environments designed to train these biological agents and probe the underlying synaptic mechanisms of learning, such as long-term potentiation (LTP) and long-term depression (LTD). We detail the design of three distinct task environments that demand progressively more sophisticated world models for successful decision-making: (1) a conditional avoidance task for learning static state-action contingencies, (2) a one-dimensional predator-prey scenario for goal-directed interaction, and (3) a replication of the classic Pong game for modeling dynamic, continuous-time systems. For each environment, we formalize the state and action spaces, the sensory encoding and motor decoding mechanisms, and the feedback protocols based on predictable (reward) and unpredictable (punishment) stimulation, which serve to drive model refinement. In a significant methodological advance, we propose a meta-learning approach where a Large Language Model automates the generative design and optimization of experimental protocols, thereby scaling the process of environment and curriculum design. Finally, we outline a multi-modal evaluation strategy that moves beyond task performance to directly measure the physical correlates of the learned world model by quantifying synaptic plasticity at electrophysiological, cellular, and molecular levels. This work bridges the gap between model-based reinforcement learning and computational neuroscience, offering a unique platform for studying embodiment, decision-making, and the physical basis of intelligence.