NER Retriever: Zero-Shot Named Entity Retrieval with Type-Aware Embeddings
作者: Or Shachar, Uri Katz, Yoav Goldberg, Oren Glickman
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-09-04
备注: Findings of EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出NER Retriever,利用类型感知嵌入实现零样本命名实体检索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体检索 零样本学习 大型语言模型 对比学习 类型感知嵌入
📋 核心要点
- 现有命名实体检索方法依赖固定模式或微调模型,难以适应开放域和用户自定义类型。
- NER Retriever利用LLM中间层表示,通过对比学习对齐类型兼容实体,构建类型感知嵌入。
- 实验表明,NER Retriever在三个基准测试中显著优于现有词汇和密集检索方法。
📝 摘要(中文)
本文提出NER Retriever,一个用于特定命名实体检索的零样本检索框架。该框架针对的是一种命名实体识别(NER)的变体,其中感兴趣的类型不是预先提供的,而是使用用户定义的类型描述来检索提及该类型实体的文档。我们的方法不依赖于固定的模式或微调的模型,而是构建在大型语言模型(LLM)的内部表示之上,将实体提及和用户提供的开放式类型描述嵌入到一个共享的语义空间中。我们发现,内部表示,特别是来自中间层Transformer块的值向量,比常用的顶层嵌入更有效地编码细粒度的类型信息。为了改进这些表示,我们训练了一个轻量级的对比投影网络,该网络对齐类型兼容的实体,同时分离不相关的类型。由此产生的实体嵌入是紧凑的、类型感知的,并且非常适合最近邻搜索。在三个基准测试中进行的评估表明,NER Retriever显著优于词汇和密集句子级别的检索基线。我们的发现为LLM中表示选择提供了经验支持,并展示了可扩展的、无模式实体检索的实用解决方案。NER Retriever的代码库已公开。
🔬 方法详解
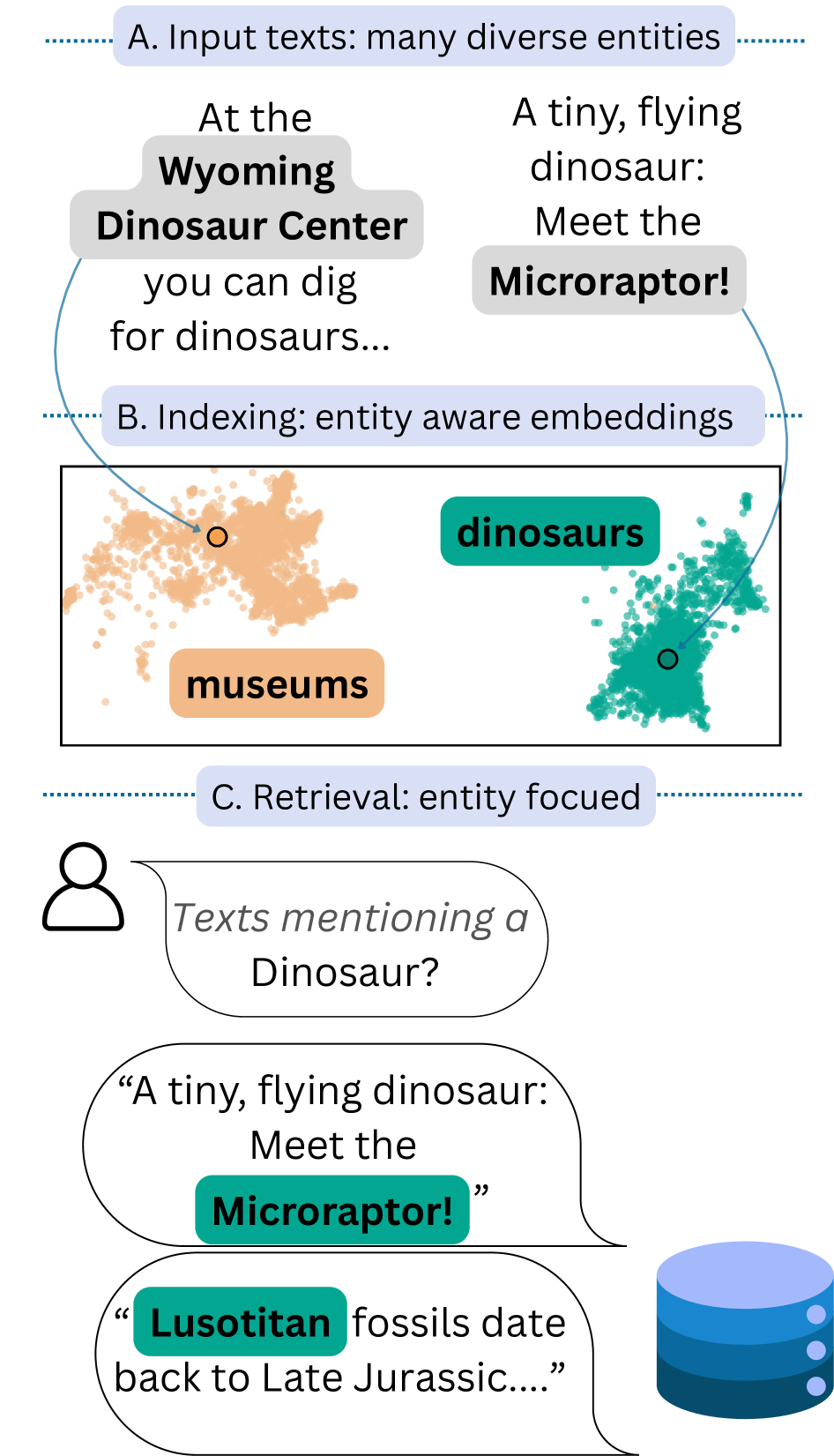
问题定义:论文旨在解决ad-hoc命名实体检索问题,即在没有预定义实体类型模式的情况下,根据用户提供的类型描述检索文档中提及的相应实体。现有方法通常依赖于固定的模式或需要针对特定类型进行微调的模型,这限制了它们在开放域和用户自定义类型场景下的应用。
核心思路:核心思路是利用大型语言模型(LLM)的内部表示来编码实体提及和类型描述,并将它们嵌入到一个共享的语义空间中。通过这种方式,可以利用LLM的语义理解能力,实现基于类型描述的实体检索,而无需预定义的模式或微调。
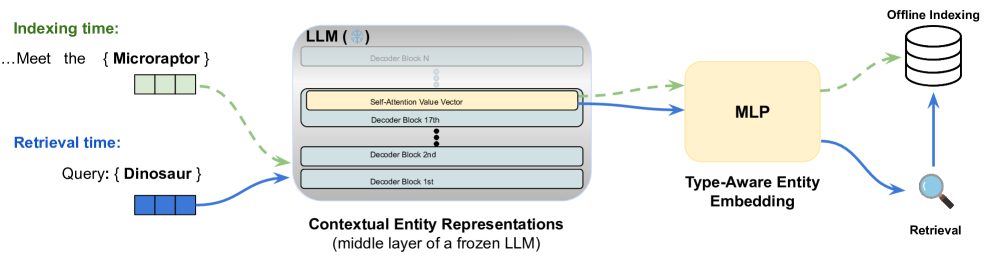
技术框架:NER Retriever框架主要包含以下几个阶段:1) 使用LLM(例如BERT)对文档中的实体提及和用户提供的类型描述进行编码。2) 从LLM的中间层Transformer块中提取值向量作为实体和类型的初始表示。3) 使用对比投影网络对这些表示进行细化,目标是拉近类型兼容的实体,同时推远不相关的类型。4) 使用最近邻搜索在嵌入空间中检索与给定类型描述最相关的实体。
关键创新:关键创新在于利用LLM的中间层表示来编码实体和类型信息。论文发现,相比于常用的顶层嵌入,中间层的值向量能够更有效地编码细粒度的类型信息。此外,对比投影网络的设计也至关重要,它能够有效地对齐类型兼容的实体,从而提高检索的准确性。
关键设计:对比投影网络使用对比损失函数进行训练,该损失函数的目标是最小化类型兼容实体之间的距离,同时最大化不相关类型实体之间的距离。具体的损失函数形式为InfoNCE loss的变体。此外,论文还探索了不同的LLM架构和中间层选择策略,以找到最佳的表示编码方式。投影网络的结构是一个简单的多层感知机(MLP)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NER Retriever在三个基准测试中显著优于现有的词汇和密集句子级别的检索基线。例如,在某个数据集上,NER Retriever的性能比最佳基线提高了超过10%。这些结果验证了利用LLM中间层表示和对比学习进行零样本命名实体检索的有效性。
🎯 应用场景
NER Retriever可应用于信息抽取、知识图谱构建、问答系统等领域。它能够根据用户自定义的类型描述,从海量文本数据中检索相关实体,无需预定义模式或进行模型微调,具有很高的灵活性和可扩展性。未来可应用于更广泛的开放域信息检索和知识发现任务。
📄 摘要(原文)
We present NER Retriever, a zero-shot retrieval framework for ad-hoc Named Entity Retrieval, a variant of Named Entity Recognition (NER), where the types of interest are not provided in advance, and a user-defined type description is used to retrieve documents mentioning entities of that type. Instead of relying on fixed schemas or fine-tuned models, our method builds on internal representations of large language models (LLMs) to embed both entity mentions and user-provided open-ended type descriptions into a shared semantic space. We show that internal representations, specifically the value vectors from mid-layer transformer blocks, encode fine-grained type information more effectively than commonly used top-layer embeddings. To refine these representations, we train a lightweight contrastive projection network that aligns type-compatible entities while separating unrelated types. The resulting entity embeddings are compact, type-aware, and well-suited for nearest-neighbor search. Evaluated on three benchmarks, NER Retriever significantly outperforms both lexical and dense sentence-level retrieval baselines. Our findings provide empirical support for representation selection within LLMs and demonstrate a practical solution for scalable, schema-free entity retrieval. The NER Retriever Codebase is publicly available at https://github.com/ShacharOr100/ner_retriever