NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
作者: Chuhan Zhang, Ye Zhang, Bowen Shi, Yuyou Gan, Tianyu Du, Shouling Ji, Dazhan Deng, Yingcai Wu
分类: cs.CR, cs.AI
发布日期: 2025-09-04
备注: 12 pages, 9 figures
💡 一句话要点
NeuroBreak:揭示大型语言模型内部的越狱机制,助力防御策略升级。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 安全分析 神经元分析 对抗性攻击 安全防御 表示学习
📋 核心要点
- 现有大型语言模型(LLMs)的安全防御面临越狱攻击的严峻挑战,但由于模型复杂性,内部安全机制难以分析。
- NeuroBreak系统通过神经元层面的分析,揭示LLMs在面对越狱攻击时的决策过程,从而发现潜在的安全漏洞。
- 通过定量评估和案例研究,验证了NeuroBreak系统的有效性,为开发更强大的LLM防御策略提供了新的思路。
📝 摘要(中文)
大型语言模型(LLMs)在部署和应用中通常会进行安全对齐,以防止非法和不道德的输出。然而,越狱攻击技术的不断进步,旨在通过对抗性提示绕过安全机制,给LLMs的安全防御带来了越来越大的压力。加强对越狱攻击的抵抗能力需要深入了解LLMs的安全机制和漏洞。然而,LLMs庞大的参数量和复杂的结构使得从内部角度分析安全弱点成为一项具有挑战性的任务。本文提出了NeuroBreak,一个自顶向下的越狱分析系统,旨在分析神经元级别的安全机制并缓解漏洞。我们通过与三位人工智能安全领域专家的合作,精心设计了系统需求。该系统提供了对各种越狱攻击方法的全面分析。通过结合分层表示探测分析,NeuroBreak为模型在生成步骤中的决策过程提供了一个新的视角。此外,该系统支持从语义和功能角度分析关键神经元,从而促进对安全机制的更深入探索。我们进行了定量评估和案例研究,以验证我们系统的有效性,为开发下一代防御策略提供了机制性见解,以应对不断演变的越狱攻击。
🔬 方法详解
问题定义:大型语言模型在部署后需要进行安全对齐,以避免产生有害或不道德的输出。然而,现有的越狱攻击技术不断发展,能够绕过这些安全机制。由于LLMs的参数众多且结构复杂,从内部视角理解其安全弱点非常困难,这阻碍了防御策略的有效提升。现有方法缺乏对模型内部决策过程的深入理解,难以针对性地进行防御。
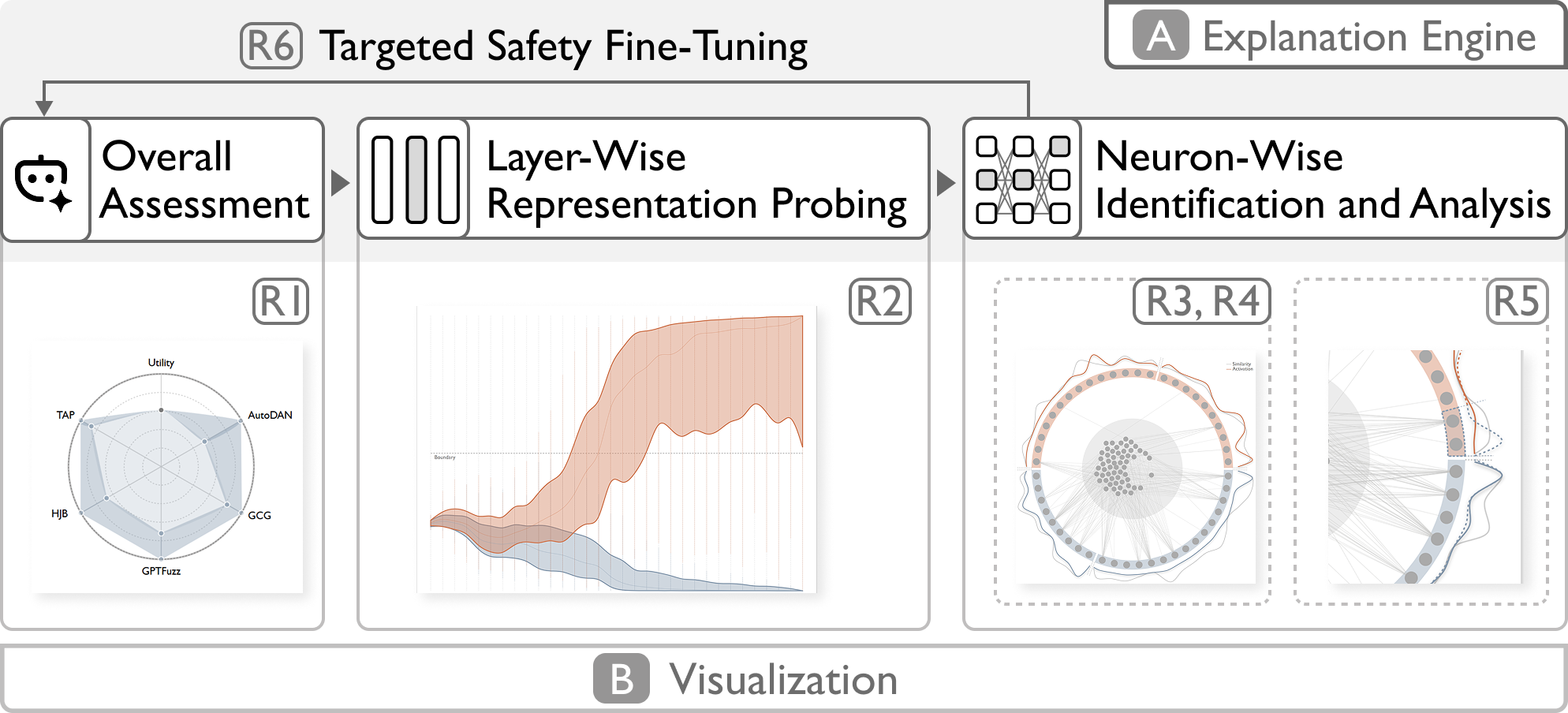
核心思路:NeuroBreak的核心思路是从神经元层面入手,分析LLMs在面对越狱攻击时的行为。通过探测不同层的表示,理解模型在生成过程中的决策逻辑,从而识别出对越狱攻击敏感的关键神经元。这种自顶向下的分析方法能够揭示模型内部的安全机制和潜在漏洞。
技术框架:NeuroBreak系统包含以下主要模块:1) 越狱攻击方法分析模块,用于收集和分析各种越狱攻击技术。2) 分层表示探测分析模块,用于提取模型不同层的表示,并分析其与越狱攻击的关系。3) 关键神经元分析模块,用于从语义和功能角度分析对越狱攻击响应显著的神经元。整个流程旨在从神经元层面理解模型的安全机制,并识别潜在的漏洞。
关键创新:NeuroBreak的关键创新在于其神经元级别的分析方法。与以往主要关注输入输出的黑盒方法不同,NeuroBreak深入模型内部,通过分析神经元的激活模式来理解模型的决策过程。这种方法能够更精确地定位安全漏洞,并为开发更有效的防御策略提供指导。
关键设计:NeuroBreak的关键设计包括:1) 精心设计的探测方法,用于提取模型不同层的表示,并尽可能保留关键信息。2) 基于语义和功能的神经元分析方法,用于理解神经元的作用和对越狱攻击的响应。3) 可视化界面,方便用户交互和分析结果。具体的参数设置、损失函数和网络结构等细节可能因不同的LLM而异,但整体框架保持不变。
🖼️ 关键图片


📊 实验亮点
NeuroBreak通过定量评估和案例研究验证了其有效性。该系统能够识别出对越狱攻击敏感的关键神经元,并揭示模型内部的决策过程。与现有方法相比,NeuroBreak能够更深入地理解LLMs的安全机制,为开发下一代防御策略提供了机制性见解。具体性能数据和提升幅度在论文中进行了详细展示。
🎯 应用场景
NeuroBreak可应用于评估和提升大型语言模型的安全性,帮助开发者发现和修复潜在的安全漏洞。该研究的成果可以促进更安全、更可靠的LLM的开发和部署,降低LLM被恶意利用的风险,例如生成有害信息或进行欺诈活动。未来,该技术可以扩展到其他类型的AI模型,提高整体AI系统的安全性。
📄 摘要(原文)
In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.