The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
作者: Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, R. Michael Alvarez
分类: cs.AI, cs.CL, cs.CY, cs.LG, stat.ML
发布日期: 2025-09-03 (更新: 2025-09-05)
备注: We make public all code and source data at https://github.com/psychology-of-AI/Personality-Illusion for full reproducibility
💡 一句话要点
揭示LLM人格幻觉:自述与行为的解离现象研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格特质 行为验证 自我报告 角色扮演
📋 核心要点
- 现有研究主要依赖LLM的自我报告来评估其人格特质,缺乏行为层面的验证,难以判断LLM人格的真实性。
- 该论文通过系统性实验,对比LLM在自我报告和实际行为中的人格表现,揭示两者之间的差异。
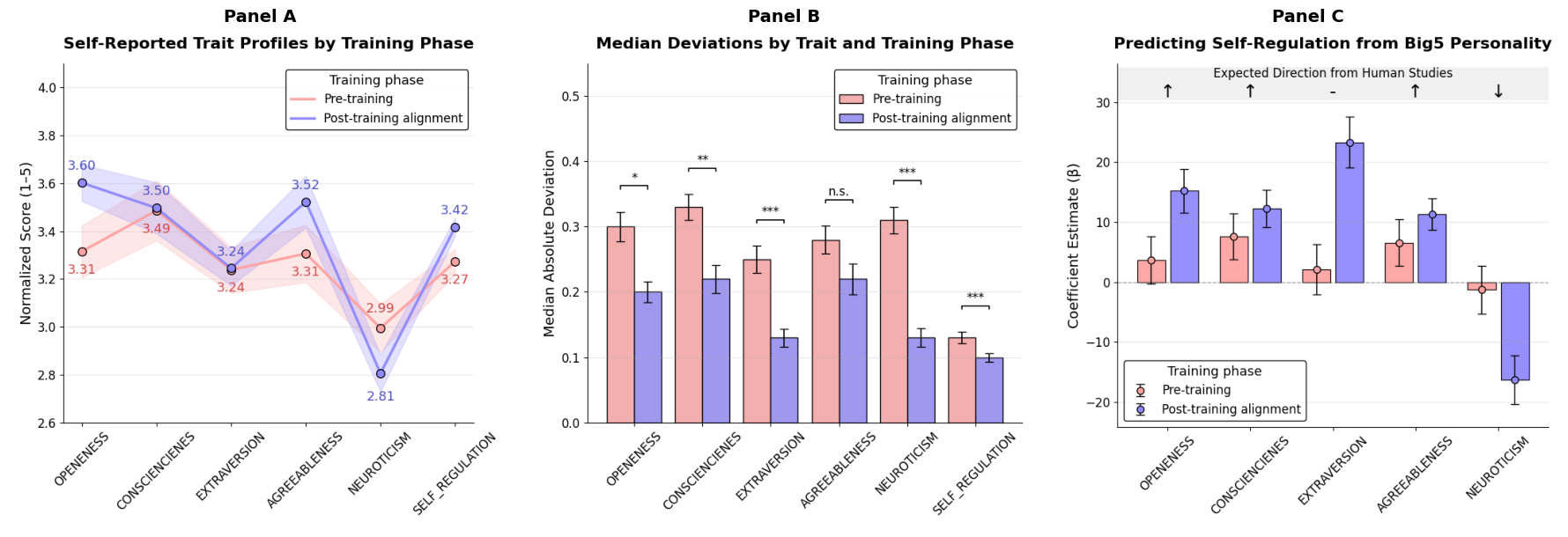
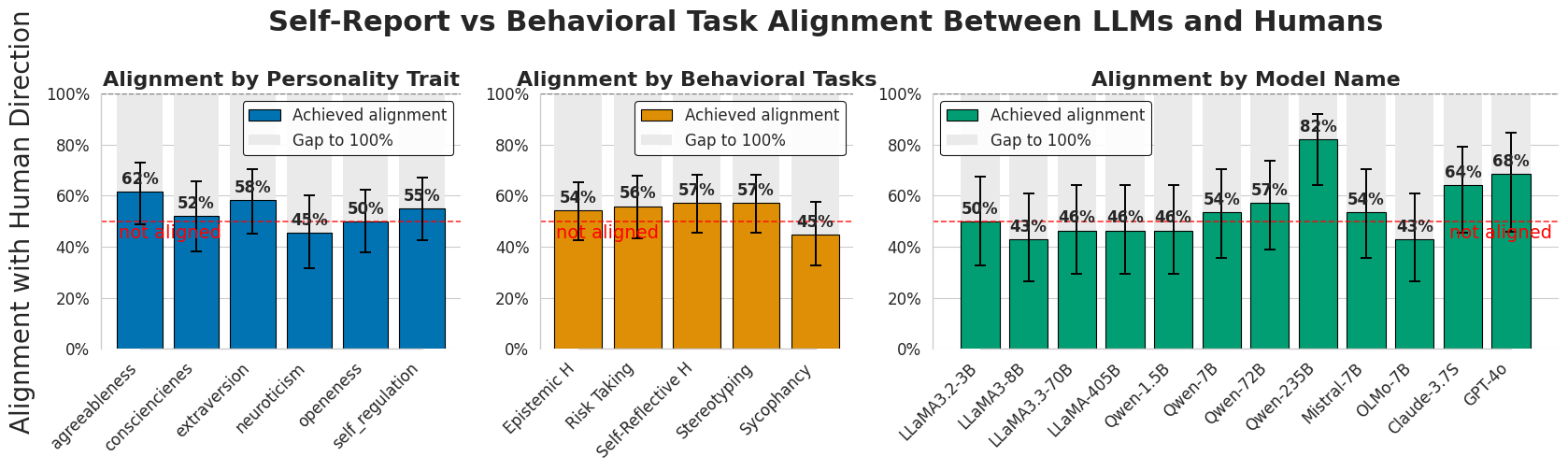
- 实验表明,指令对齐能稳定LLM的特质表达,但自我报告的特质并不能可靠预测行为,角色注入对行为影响有限。
📝 摘要(中文)
人格特质长期以来被认为是人类行为的预测指标。大型语言模型(LLM)的最新进展表明,类似模式可能出现在人工智能系统中,高级LLM表现出与人类特质(如宜人性和自我调节)相似的一致行为倾向。理解这些模式至关重要,但先前的工作主要依赖于简化的自我报告和启发式提示,缺乏行为验证。本研究系统地描述了LLM人格的三个维度:(1)在训练阶段中特质特征的动态出现和演变;(2)自我报告特质在行为任务中的预测有效性;(3)目标干预(如角色注入)对自我报告和行为的影响。研究结果表明,指令对齐(例如,RLHF,指令微调)显著稳定了特质表达并加强了特质相关性,这与人类数据相似。然而,这些自我报告的特质不能可靠地预测行为,并且观察到的关联通常与人类模式不同。虽然角色注入成功地将自我报告引导到预期方向,但它对实际行为的影响很小或不一致。通过区分表面层面的特质表达与行为一致性,我们的研究结果挑战了关于LLM人格的假设,并强调需要在对齐和可解释性方面进行更深入的评估。
🔬 方法详解
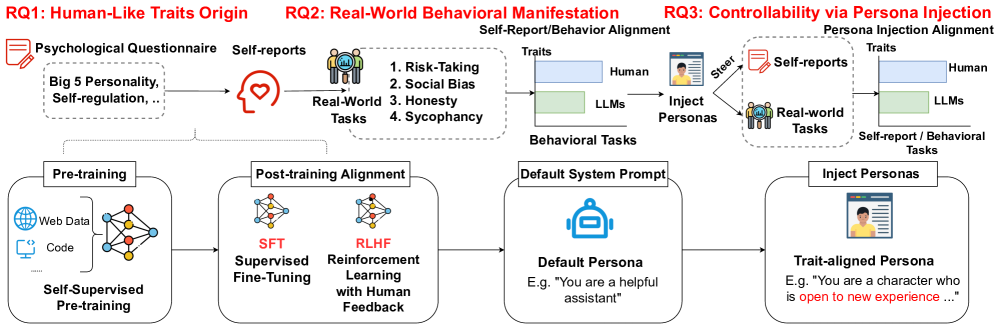
问题定义:现有研究主要通过LLM的自我报告来推断其人格特质,但这种方法缺乏行为验证,无法确定LLM的“人格”是否真实反映了其行为模式。因此,该论文旨在研究LLM的自我报告人格特质与实际行为之间是否存在一致性,以及外部干预(如角色扮演)对两者影响的差异。
核心思路:该论文的核心思路是通过设计一系列行为任务,观察LLM在不同情境下的行为表现,并将其与LLM的自我报告人格特质进行对比分析。同时,通过角色注入等干预手段,观察这些干预对LLM的自我报告和行为的影响,从而揭示LLM人格的本质。
技术框架:该研究的技术框架主要包括以下几个部分: 1. 人格评估:使用标准的人格评估问卷(如Big Five Inventory)评估LLM的自我报告人格特质。 2. 行为任务设计:设计一系列行为任务,模拟真实世界中的情境,例如合作、竞争、风险决策等,用于观察LLM的行为表现。 3. 角色注入:通过在prompt中加入特定角色信息,引导LLM扮演特定人格的角色。 4. 数据分析:对比分析LLM的自我报告人格特质、行为表现以及角色注入的影响,评估两者之间的一致性。
关键创新:该论文的关键创新在于: 1. 行为验证:首次系统性地通过行为任务验证LLM的自我报告人格特质,弥补了现有研究的不足。 2. 解离现象揭示:揭示了LLM的自我报告人格特质与实际行为之间存在解离现象,挑战了关于LLM人格的传统认知。 3. 干预效果评估:评估了角色注入等干预手段对LLM自我报告和行为的影响,为LLM的对齐和可解释性研究提供了新的视角。
关键设计: 1. 行为任务设计:精心设计行为任务,确保能够有效区分不同人格特质的行为表现。 2. 角色注入策略:采用多种角色注入策略,例如直接描述角色特征、提供角色背景故事等,以评估不同策略的效果。 3. 统计分析方法:采用合适的统计分析方法,例如相关性分析、回归分析等,评估LLM的自我报告和行为之间的一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,指令对齐能显著稳定LLM的特质表达,并加强特质相关性,但自我报告的特质并不能可靠预测行为。角色注入虽然能影响LLM的自我报告,但对实际行为的影响很小或不一致。这些发现挑战了关于LLM人格的假设。
🎯 应用场景
该研究成果可应用于提升LLM的对齐和可解释性。通过理解LLM人格的本质,可以更好地控制LLM的行为,避免其产生不符合人类价值观的行为。此外,该研究还可以为开发更具个性化和适应性的LLM应用提供指导,例如个性化推荐系统、智能助手等。
📄 摘要(原文)
Personality traits have long been studied as predictors of human behavior. Recent advances in Large Language Models (LLMs) suggest similar patterns may emerge in artificial systems, with advanced LLMs displaying consistent behavioral tendencies resembling human traits like agreeableness and self-regulation. Understanding these patterns is crucial, yet prior work primarily relied on simplified self-reports and heuristic prompting, with little behavioral validation. In this study, we systematically characterize LLM personality across three dimensions: (1) the dynamic emergence and evolution of trait profiles throughout training stages; (2) the predictive validity of self-reported traits in behavioral tasks; and (3) the impact of targeted interventions, such as persona injection, on both self-reports and behavior. Our findings reveal that instructional alignment (e.g., RLHF, instruction tuning) significantly stabilizes trait expression and strengthens trait correlations in ways that mirror human data. However, these self-reported traits do not reliably predict behavior, and observed associations often diverge from human patterns. While persona injection successfully steers self-reports in the intended direction, it exerts little or inconsistent effect on actual behavior. By distinguishing surface-level trait expression from behavioral consistency, our findings challenge assumptions about LLM personality and underscore the need for deeper evaluation in alignment and interpretability.