The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
作者: Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Francisco Piedrahita-Velez, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Jun Wang, Shuicheng Yan, Philip Torr, Lei Bai
分类: cs.AI, cs.CL
发布日期: 2025-09-02 (更新: 2026-01-24)
备注: Published on Transactions on Machine Learning Research: https://openreview.net/forum?id=RY19y2RI1O
💡 一句话要点
Agentic RL综述:将LLM从序列生成器转变为自主决策智能体,并提供能力、应用、环境基准的全面分析。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic强化学习 大型语言模型 自主决策 强化学习 智能体 环境交互 工具使用
📋 核心要点
- 传统LLM-RL将LLM视为被动序列生成器,缺乏在复杂动态环境中自主决策的能力。
- Agentic RL将LLM重塑为自主智能体,通过强化学习赋予其规划、工具使用、记忆等核心能力。
- 论文整理了Agentic RL的开源环境、基准和框架,为未来研究提供了实用指南,并分析了领域机遇与挑战。
📝 摘要(中文)
Agentic强化学习(Agentic RL)的出现标志着从应用于大型语言模型(LLM RL)的传统强化学习的范式转变,它将LLM从被动的序列生成器重新定义为嵌入在复杂、动态世界中的自主决策智能体。本综述通过对比LLM-RL的退化单步马尔可夫决策过程(MDP)与定义Agentic RL的时序扩展、部分可观察马尔可夫决策过程(POMDP),正式化了这一概念转变。在此基础上,我们提出了一个全面的双重分类法:一个围绕核心智能体能力组织,包括规划、工具使用、记忆、推理、自我改进和感知,另一个围绕它们在不同任务领域的应用。我们的核心论点是,强化学习是使这些能力从静态的、启发式模块转变为自适应、鲁棒的智能体行为的关键机制。为了支持和加速未来的研究,我们将开源环境、基准和框架整合到一个实用的纲要中。通过综合五百多篇最新著作,本综述描绘了这一快速发展领域的轮廓,并强调了将塑造可扩展的通用人工智能智能体发展的机遇和挑战。
🔬 方法详解
问题定义:现有的大型语言模型强化学习(LLM-RL)方法通常将LLM视为被动的序列生成器,缺乏在复杂、动态环境中进行自主决策的能力。这些方法通常基于简化的单步马尔可夫决策过程(MDP),无法处理需要长期规划和与环境交互的任务。因此,如何将LLM转变为能够自主行动、解决复杂问题的智能体是一个关键挑战。
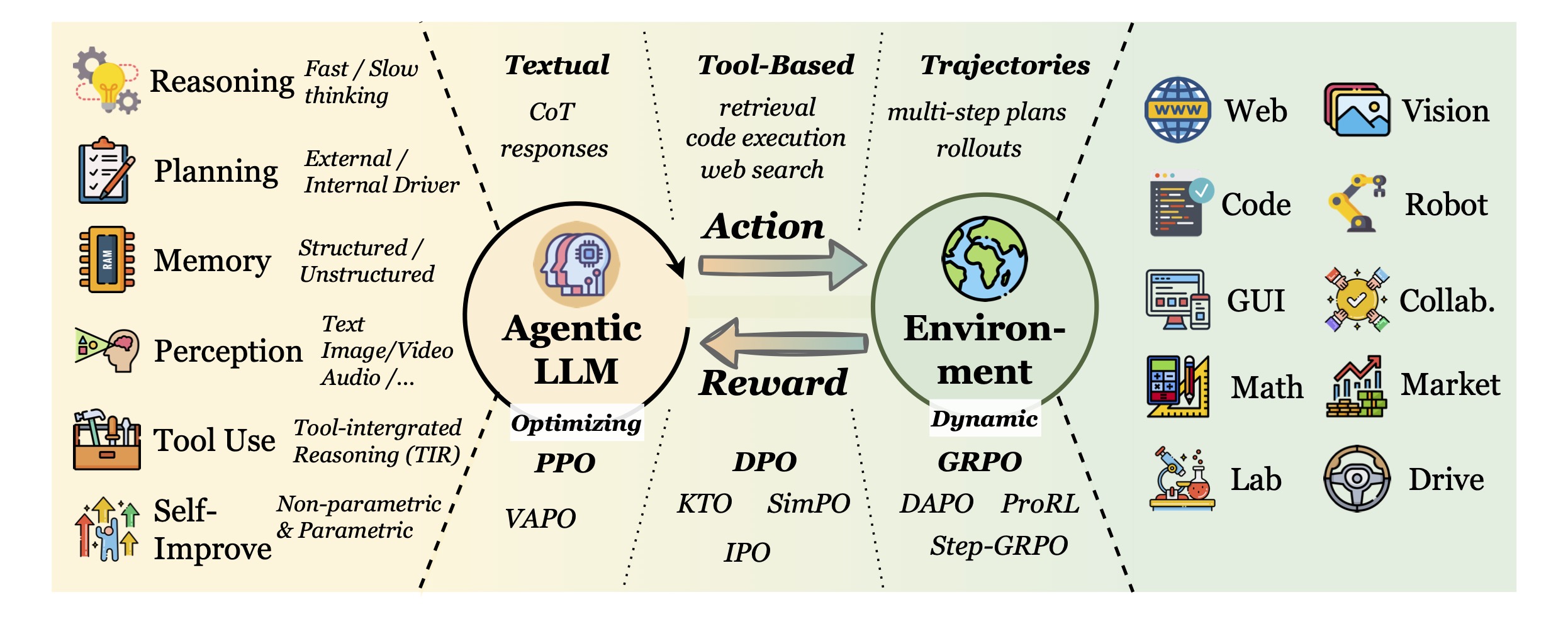
核心思路:本论文的核心思路是将LLM视为Agentic RL中的智能体,通过强化学习赋予其核心能力,例如规划、工具使用、记忆、推理、自我改进和感知。通过将LLM嵌入到部分可观察马尔可夫决策过程(POMDP)中,使其能够与环境进行交互,并根据环境反馈进行学习和改进。这种方法旨在将LLM从静态的序列生成器转变为能够自主决策和解决复杂问题的智能体。
技术框架:Agentic RL的技术框架通常包括以下几个主要模块:1) LLM作为智能体的大脑,负责决策和行动;2) 环境模拟器,用于模拟智能体所处的复杂环境;3) 强化学习算法,用于训练智能体并优化其策略;4) 核心能力模块,包括规划、工具使用、记忆、推理、自我改进和感知等。智能体通过与环境交互,观察环境状态,并根据当前状态选择行动。环境根据智能体的行动更新状态,并向智能体提供奖励信号。强化学习算法根据奖励信号调整智能体的策略,使其能够更好地完成任务。
关键创新:本论文的关键创新在于提出了一个全面的Agentic RL框架,该框架将LLM与强化学习相结合,赋予LLM自主决策和解决复杂问题的能力。此外,论文还提出了一个双重分类法,用于组织和分析Agentic RL领域的研究工作。该分类法从核心智能体能力和应用领域两个维度对Agentic RL进行了全面的梳理和总结。
关键设计:Agentic RL的关键设计包括:1) 如何设计有效的奖励函数,以引导智能体学习期望的行为;2) 如何选择合适的强化学习算法,以优化智能体的策略;3) 如何设计核心能力模块,以提高智能体的决策能力;4) 如何构建逼真的环境模拟器,以支持智能体的训练和评估。此外,如何处理部分可观察性问题,以及如何提高智能体的泛化能力也是Agentic RL的关键设计考虑因素。
🖼️ 关键图片
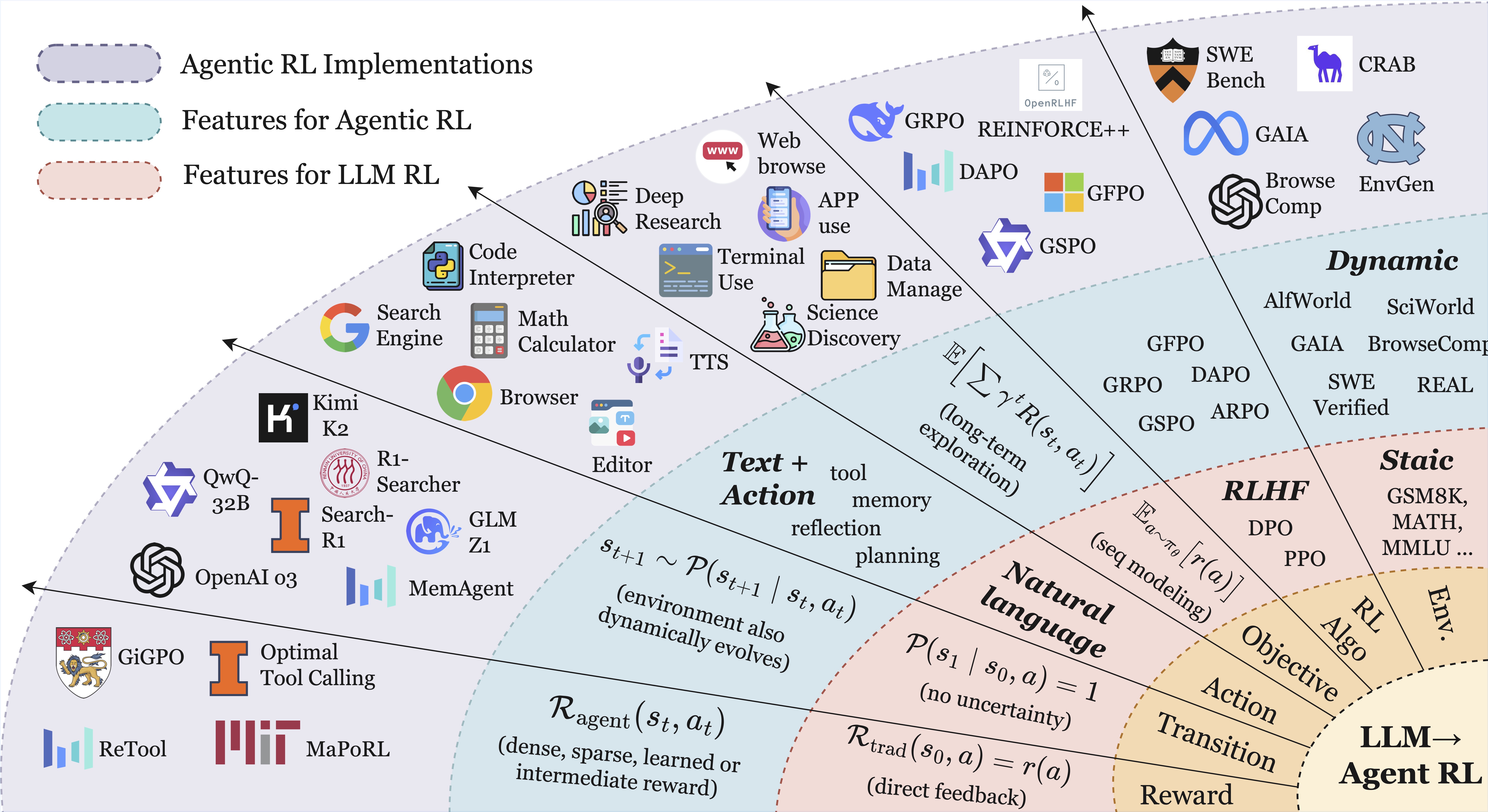

📊 实验亮点
该综述总结了超过五百篇相关论文,并对Agentic RL的开源环境、基准和框架进行了整合,为未来的研究提供了有价值的资源。论文还强调了Agentic RL领域面临的机遇和挑战,例如如何提高智能体的可扩展性和通用性,以及如何解决长期规划和探索问题。这些分析为未来的研究方向提供了重要的指导。
🎯 应用场景
Agentic RL具有广泛的应用前景,包括机器人控制、游戏AI、对话系统、自动化任务执行等领域。通过赋予LLM自主决策能力,可以使其在复杂环境中完成各种任务,例如自动驾驶、智能家居、客户服务等。未来的发展方向包括提高智能体的泛化能力、鲁棒性和可解释性,以及探索更有效的强化学习算法和核心能力模块。
📄 摘要(原文)
The emergence of agentic reinforcement learning (Agentic RL) marks a paradigm shift from conventional reinforcement learning applied to large language models (LLM RL), reframing LLMs from passive sequence generators into autonomous, decision-making agents embedded in complex, dynamic worlds. This survey formalizes this conceptual shift by contrasting the degenerate single-step Markov Decision Processes (MDPs) of LLM-RL with the temporally extended, partially observable Markov decision processes (POMDPs) that define Agentic RL. Building on this foundation, we propose a comprehensive twofold taxonomy: one organized around core agentic capabilities, including planning, tool use, memory, reasoning, self-improvement, and perception, and the other around their applications across diverse task domains. Central to our thesis is that reinforcement learning serves as the critical mechanism for transforming these capabilities from static, heuristic modules into adaptive, robust agentic behavior. To support and accelerate future research, we consolidate the landscape of open-source environments, benchmarks, and frameworks into a practical compendium. By synthesizing over five hundred recent works, this survey charts the contours of this rapidly evolving field and highlights the opportunities and challenges that will shape the development of scalable, general-purpose AI agents.