TinyServe: Query-Aware Cache Selection for Efficient LLM Serving
作者: Dong Liu, Yanxuan Yu
分类: cs.DC, cs.AI
发布日期: 2025-08-28
备注: Accepted to ACM MM as Oral Paper, also accepted to ICML MOSS workshop, publicly available as https://openreview.net/forum?id=sOdtl4jLci
💡 一句话要点
TinyServe:面向高效LLM服务的查询感知缓存选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM服务 KV缓存 查询感知 页面选择 稀疏性 CUDA内核 资源受限设备
📋 核心要点
- 现有LLM服务面临KV缓存访问带来的高内存和延迟开销,限制了在资源受限设备上的部署。
- TinyServe通过查询感知的页面选择机制,估计查询与KV缓存块的相关性,实现选择性KV加载,降低解码成本。
- 实验表明,TinyServe在精度损失可忽略不计的情况下,实现了高达3.4倍的加速和超过2倍的内存节省。
📝 摘要(中文)
高效地服务大型语言模型(LLM)仍然具有挑战性,这主要是由于自回归解码期间键值(KV)缓存访问的高内存和延迟开销。我们提出了TinyServe,一个轻量级且可扩展的服务系统,用于部署小型LLM(例如,TinyLLaMA,GPT2-345M),支持结构化KV稀疏性、基于插件的token选择和硬件高效的注意力内核。与之前的仿真框架不同,TinyServe通过可配置的稀疏策略和细粒度的工具,执行实时解码。为了降低解码成本,我们引入了一种查询感知的页面选择机制,该机制利用边界框元数据来估计查询和KV缓存块之间的注意力相关性。这使得选择性KV加载成为可能,且具有最小的开销,无需模型修改。我们融合的CUDA内核在单个过程中集成了页面评分、稀疏内存访问和掩码注意力。实验表明,TinyServe实现了高达3.4倍的加速和超过2倍的内存节省,而精度下降可忽略不计。对缓存重用、页面命中率和多GPU扩展的额外分析证实了其作为一种高效的系统级设计的实用性,适用于资源受限硬件上的LLM训练和推理研究。
🔬 方法详解
问题定义:现有LLM服务在自回归解码过程中,需要频繁访问KV缓存,导致高内存占用和延迟,尤其是在资源受限的硬件上部署小型LLM时,效率问题更加突出。现有的方法通常采用模型压缩或硬件加速等手段,但缺乏针对KV缓存访问的优化策略。
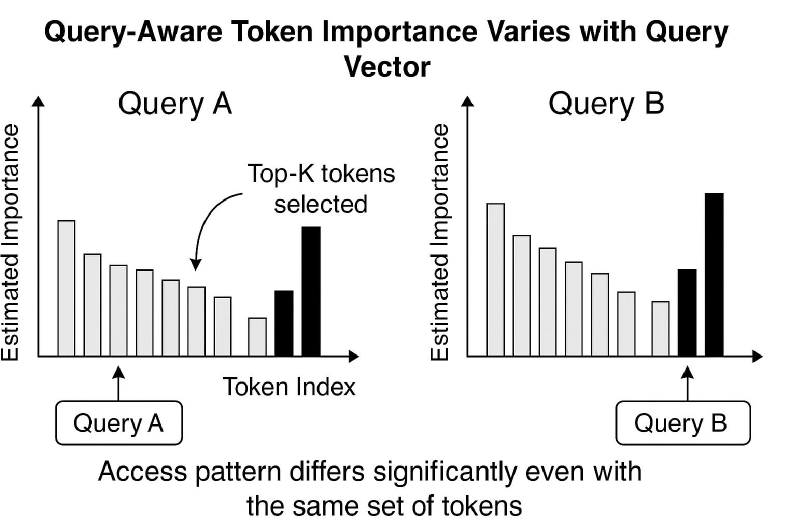
核心思路:TinyServe的核心思路是利用查询感知的页面选择机制,仅加载与当前查询相关的KV缓存块,从而减少内存占用和访问延迟。通过估计查询和KV缓存块之间的注意力相关性,可以避免不必要的KV缓存访问,提高解码效率。
技术框架:TinyServe包含以下主要模块:1) 结构化KV稀疏性支持,允许对KV缓存进行稀疏化存储;2) 基于插件的token选择,支持灵活的token选择策略;3) 硬件高效的注意力内核,优化注意力计算过程;4) 查询感知的页面选择机制,根据查询内容选择性加载KV缓存块。整体流程是:接收查询 -> 页面评分 -> 选择KV缓存块 -> 执行注意力计算 -> 生成token。
关键创新:TinyServe的关键创新在于查询感知的页面选择机制。与现有方法不同,TinyServe不是无差别地访问所有KV缓存,而是根据查询内容动态地选择相关的KV缓存块。这种方法能够显著减少内存占用和访问延迟,提高解码效率。此外,融合的CUDA内核将页面评分、稀疏内存访问和掩码注意力集成在单个过程中,进一步提高了计算效率。
关键设计:查询感知的页面选择机制使用边界框元数据来估计查询和KV缓存块之间的注意力相关性。具体来说,每个KV缓存块都关联一个边界框,表示该块所包含的信息范围。在解码过程中,TinyServe首先计算查询与每个KV缓存块的边界框之间的相似度,然后选择相似度最高的KV缓存块进行加载。页面评分函数的设计是关键,需要平衡计算复杂度和准确性。此外,稀疏内存访问的实现也需要考虑硬件特性,以实现最佳性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TinyServe在TinyLLaMA和GPT2-345M等小型LLM上实现了显著的性能提升。与基线系统相比,TinyServe实现了高达3.4倍的加速和超过2倍的内存节省,而精度下降可忽略不计。此外,对缓存重用、页面命中率和多GPU扩展的分析证实了TinyServe的实用性和可扩展性。
🎯 应用场景
TinyServe适用于资源受限设备上的LLM部署,例如移动设备、嵌入式系统和边缘服务器。它可以加速LLM在这些设备上的推理速度,并降低内存占用,从而实现更广泛的应用,例如智能助手、自然语言处理和机器翻译等。该研究对于推动LLM在资源受限环境下的应用具有重要意义。
📄 摘要(原文)
Serving large language models (LLMs) efficiently remains challenging due to the high memory and latency overhead of key-value (KV) cache access during autoregressive decoding. We present \textbf{TinyServe}, a lightweight and extensible serving system for deploying tiny LLMs (e.g., TinyLLaMA, GPT2-345M) with support for structured KV sparsity, plugin-based token selection, and hardware-efficient attention kernels. Unlike prior simulation frameworks, TinyServe executes real-time decoding with configurable sparsity strategies and fine-grained instrumentation. To reduce decoding cost, we introduce a \textit{query-aware page selection} mechanism that leverages bounding-box metadata to estimate attention relevance between the query and KV cache blocks. This enables selective KV loading with minimal overhead and no model modifications. Our fused CUDA kernel integrates page scoring, sparse memory access, and masked attention in a single pass. Experiments show that TinyServe achieves up to \textbf{3.4x} speedup and over \textbf{2x} memory savings with negligible accuracy drop. Additional analysis of cache reuse, page hit rate, and multi-GPU scaling confirms its practicality as an efficient system-level design for LLM training and inference research on resource-constrained hardware.