Learning to Generate Unit Test via Adversarial Reinforcement Learning
作者: Dongjun Lee, Changho Hwang, Kimin Lee
分类: cs.SE, cs.AI
发布日期: 2025-08-28 (更新: 2025-09-30)
备注: Code is available at: https://github.com/dgjun32/UTRL
💡 一句话要点
提出UTRL框架,通过对抗强化学习提升LLM生成高质量单元测试的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单元测试生成 强化学习 对抗学习 大型语言模型 代码质量 自动化测试 Qwen3-4B
📋 核心要点
- 编写全面的单元测试具有挑战性,现有方法难以训练LLM生成高质量测试。
- UTRL框架通过对抗强化学习,迭代训练单元测试生成器和代码生成器。
- 实验表明,UTRL训练的Qwen3-4B优于监督微调和GPT-4.1,生成更高质量的单元测试。
📝 摘要(中文)
本文提出了一种新颖的强化学习框架UTRL,用于训练大型语言模型(LLM)生成高质量的单元测试,以评估人类开发者或LLM生成的程序。UTRL的核心思想是通过对抗的方式迭代训练两个LLM:单元测试生成器和代码生成器。单元测试生成器被训练以最大化判别奖励,该奖励反映了其生成能够暴露代码生成器解决方案中错误的测试的能力。代码生成器则被训练以最大化代码奖励,该奖励反映了其生成能够通过测试生成器生成的单元测试的解决方案的能力。实验结果表明,通过UTRL训练的Qwen3-4B生成的单元测试比通过监督微调在人工编写的真实单元测试上训练的同一模型表现出更高的质量,产生的代码评估结果与真实测试更一致。此外,使用UTRL训练的Qwen3-4B在生成高质量单元测试方面优于GPT-4.1等前沿模型,突出了UTRL在训练LLM执行此任务方面的有效性。
🔬 方法详解
问题定义:论文旨在解决如何训练大型语言模型(LLM)生成高质量单元测试的问题。现有的方法,例如监督微调,依赖于人工编写的单元测试数据,这既昂贵又难以覆盖所有可能的代码错误。因此,需要一种更有效的方法来训练LLM,使其能够自动生成能够有效检测代码错误的单元测试。
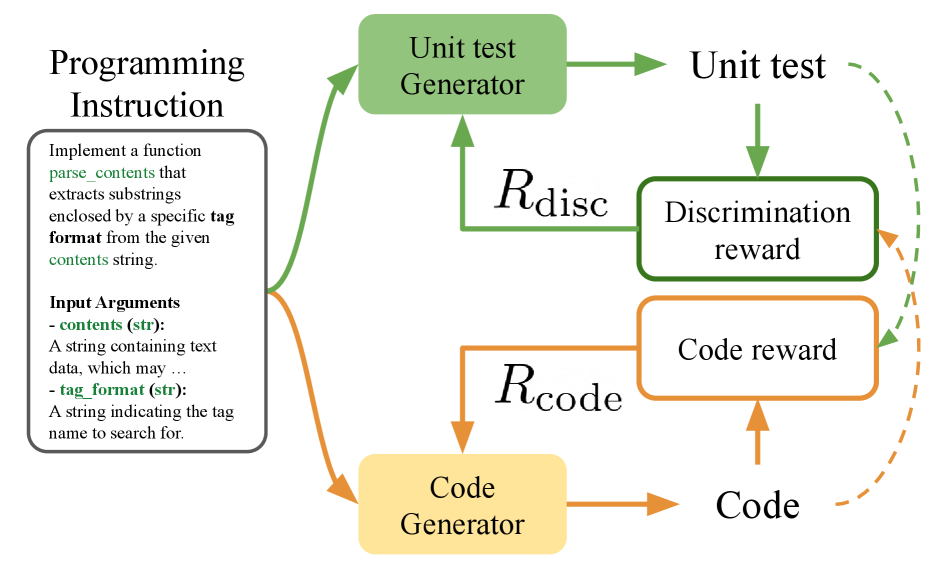
核心思路:论文的核心思路是通过对抗强化学习,迭代地训练两个LLM:一个单元测试生成器和一个代码生成器。单元测试生成器的目标是生成能够暴露代码生成器错误的测试用例,而代码生成器的目标是生成能够通过单元测试生成器生成的测试用例的代码。这种对抗训练过程能够促使单元测试生成器不断提高其测试质量,从而提高代码生成器的代码质量。
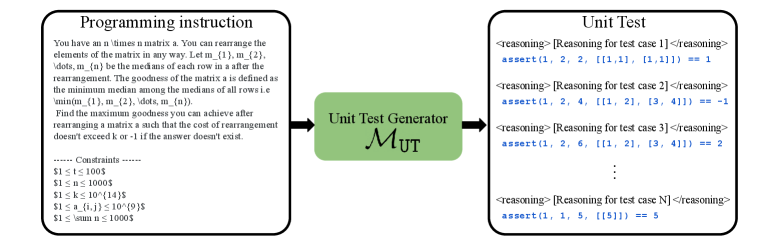
技术框架:UTRL框架包含两个主要模块:单元测试生成器和代码生成器。首先,给定一个编程指令,代码生成器生成一段代码。然后,单元测试生成器根据编程指令和生成的代码,生成一组单元测试。接下来,使用生成的单元测试来评估生成的代码,并计算代码奖励。同时,根据单元测试是否能够暴露代码中的错误,计算判别奖励。最后,使用代码奖励和判别奖励分别训练代码生成器和单元测试生成器。这个过程迭代进行,直到两个模型都达到一个稳定的状态。
关键创新:UTRL的关键创新在于使用对抗强化学习来训练LLM生成单元测试。与传统的监督微调方法相比,UTRL不需要人工编写的单元测试数据,而是通过自我博弈的方式来提高单元测试的质量。此外,UTRL使用判别奖励来鼓励单元测试生成器生成能够暴露代码错误的测试用例,这有助于提高单元测试的有效性。
关键设计:UTRL使用Qwen3-4B作为单元测试生成器和代码生成器的基础模型。代码奖励可以基于代码是否通过单元测试来设计,例如,通过的测试越多,奖励越高。判别奖励可以基于单元测试是否能够暴露代码中的错误来设计,例如,如果单元测试能够导致代码崩溃或产生错误的输出,则奖励越高。具体奖励函数的设计和超参数的调整需要根据具体的任务进行实验和优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过UTRL训练的Qwen3-4B生成的单元测试在代码评估方面与人工编写的真实测试更加一致。更重要的是,UTRL训练的Qwen3-4B在生成高质量单元测试方面优于GPT-4.1等前沿模型,证明了UTRL框架的有效性。具体性能提升数据未知,但结论表明UTRL具有显著优势。
🎯 应用场景
UTRL框架可应用于软件开发流程的自动化测试环节,帮助开发者快速生成高质量的单元测试,提高代码质量和可靠性。此外,该方法还可以用于评估和改进大型语言模型生成的代码,确保其满足预期的功能和性能要求。未来,该技术有望扩展到更广泛的软件测试领域,例如集成测试和系统测试。
📄 摘要(原文)
Unit testing is a core practice in programming, enabling systematic evaluation of programs produced by human developers or large language models (LLMs). Given the challenges in writing comprehensive unit tests, LLMs have been employed to automate test generation, yet methods for training LLMs to produce high-quality tests remain underexplored. In this work, we propose UTRL, a novel reinforcement learning framework that trains an LLM to generate high-quality unit tests given a programming instruction. Our key idea is to iteratively train two LLMs, the unit test generator and the code generator, in an adversarial manner via reinforcement learning. The unit test generator is trained to maximize a discrimination reward, which reflects its ability to produce tests that expose faults in the code generator's solutions, and the code generator is trained to maximize a code reward, which reflects its ability to produce solutions that pass the unit tests generated by the test generator. In our experiments, we demonstrate that unit tests generated by Qwen3-4B trained via UTRL show higher quality compared to unit tests generated by the same model trained via supervised fine-tuning on human-written ground-truth unit tests, yielding code evaluations that more closely align with those induced by the ground-truth tests. Moreover, Qwen3-4B trained with UTRL outperforms frontier models such as GPT-4.1 in generating high-quality unit tests, highlighting the effectiveness of UTRL in training LLMs for this task.