Single Agent Robust Deep Reinforcement Learning for Bus Fleet Control
作者: Yifan Zhang
分类: cs.AI
发布日期: 2025-08-28
💡 一句话要点
提出基于单智能体强化学习的公交车队控制方法,解决复杂场景下的公交车拥堵问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 单智能体强化学习 公交车队控制 公交车拥堵 软演员-评论家算法 智能交通 多智能体系统 类别编码 奖励函数设计
📋 核心要点
- 传统多智能体强化学习方法在处理具有异构路线、时刻表和动态需求的真实公交运营场景时存在局限性。
- 通过将多智能体问题转化为单智能体问题,并结合类别标识符和结构化奖励函数,提升了策略学习的效率和稳定性。
- 实验结果表明,改进的单智能体强化学习方法在公交车队控制方面优于传统的多智能体方法,性能更佳。
📝 摘要(中文)
本文提出了一种新颖的单智能体强化学习(RL)框架,用于公交车保持控制,以应对随机交通和乘客需求引起的公交车拥堵问题。该方法避免了近乎真实的模拟下多智能体强化学习(MARL)的数据不平衡和收敛问题。构建了一个具有动态乘客需求的双向时刻表网络。关键创新在于通过使用类别标识符(车辆ID、站点ID、时间段)以及数值特征(车头时距、占用率、速度)来扩充状态空间,从而将多智能体问题重新表述为单智能体问题。这种高维编码使单智能体策略能够捕获智能体间的依赖关系。此外,设计了一个与运营目标相一致的结构化奖励函数。实验表明,改进的软演员-评论家(SAC)算法比包括MADDPG在内的基准算法实现了更稳定和卓越的性能(例如,在随机条件下,-430k vs. -530k)。这些结果表明,当通过类别结构化和时间表感知奖励进行增强时,单智能体深度RL可以有效地管理非循环、真实世界环境中的公交车保持。这种范例为MARL框架提供了一种稳健、可扩展的替代方案,尤其是在智能体特定经验不平衡的情况下。
🔬 方法详解
问题定义:论文旨在解决城市公交系统中由于随机交通和乘客需求波动导致的公交车拥堵问题。现有基于多智能体强化学习(MARL)的解决方案在处理具有异构路线、时刻表和动态需求的真实运营场景时,面临数据不平衡和收敛困难等问题。
核心思路:论文的核心思路是将多智能体问题转化为单智能体问题,通过扩展状态空间,使单智能体能够感知到其他智能体的信息,从而学习到协调控制策略。同时,设计与运营目标对齐的奖励函数,引导智能体学习更符合实际需求的控制策略。
技术框架:该方法构建了一个双向时刻表网络,模拟公交线路的运营环境。整体框架包括以下几个主要部分:状态空间构建(包含数值特征和类别标识符)、单智能体强化学习算法(改进的SAC算法)、结构化奖励函数设计。智能体根据当前状态选择动作(公交车保持),并根据环境反馈获得奖励,通过不断学习优化策略。
关键创新:最重要的技术创新点在于将多智能体问题转化为单智能体问题,并通过类别标识符(车辆ID、站点ID、时间段)来编码智能体间的依赖关系。这种方法避免了多智能体强化学习中的复杂性和不稳定性,提高了学习效率。与现有方法相比,该方法更适用于处理具有异构性和动态性的真实公交运营场景。
关键设计:状态空间的关键设计在于引入类别标识符,将车辆ID、站点ID和时间段等信息编码到状态中,使智能体能够区分不同的车辆和站点,并感知到时间信息。奖励函数的关键设计在于采用岭状奖励,平衡均匀车头时距和时刻表遵守,避免了传统指数惩罚带来的问题。算法方面,采用了改进的软演员-评论家(SAC)算法,以提高学习的稳定性和性能。
🖼️ 关键图片
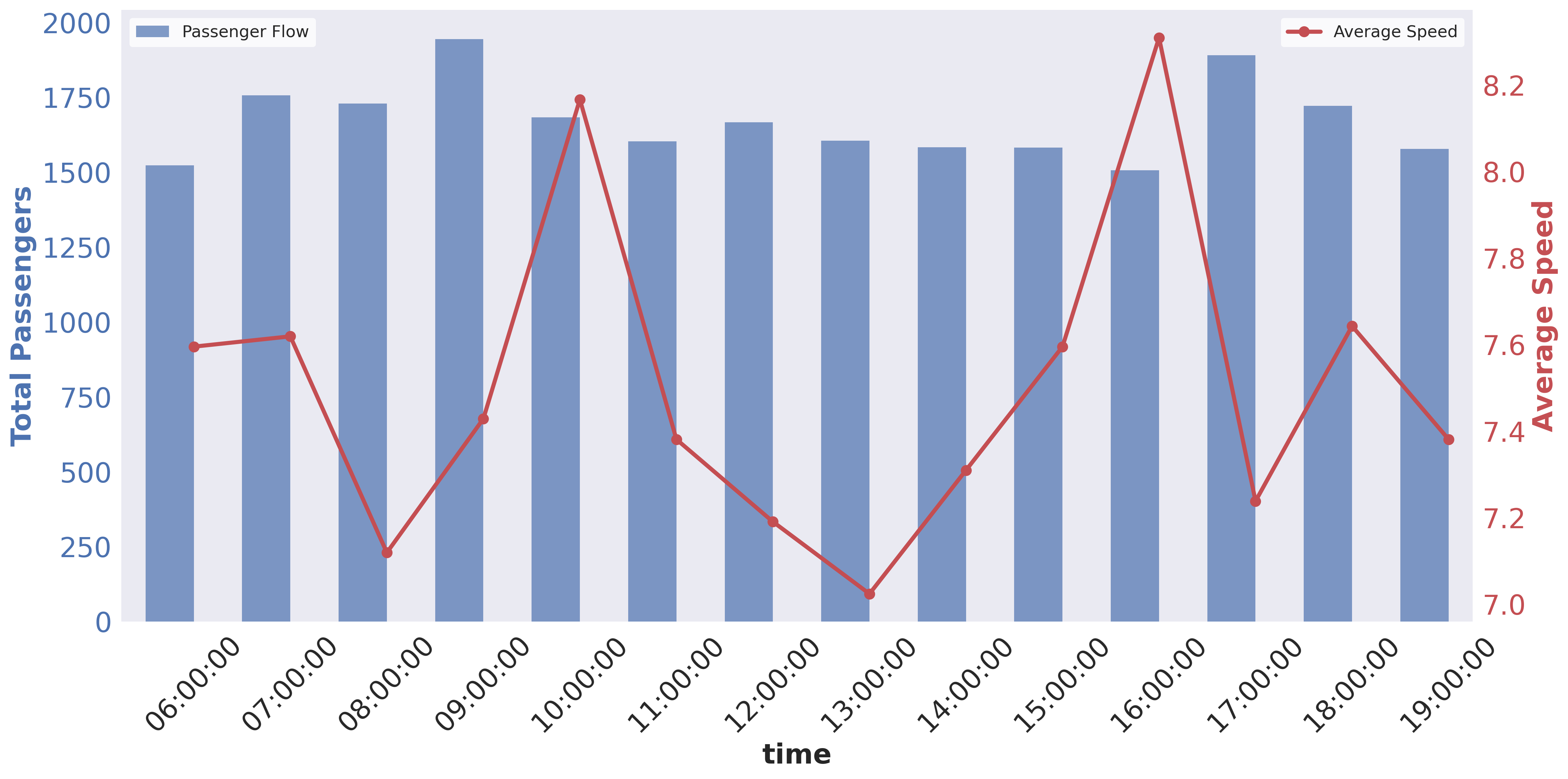

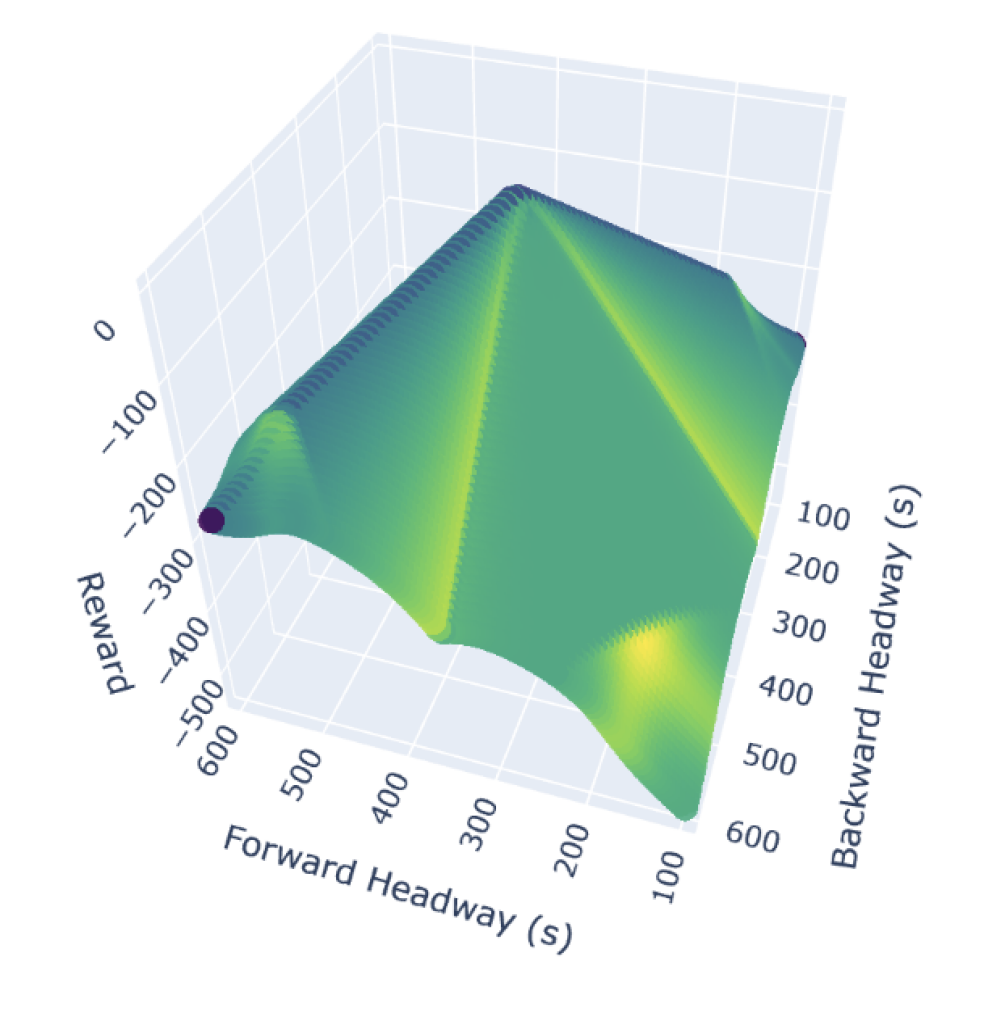
📊 实验亮点
实验结果表明,该方法在随机条件下,改进的SAC算法比MADDPG算法性能提升显著(-430k vs. -530k),证明了单智能体深度强化学习在公交车队控制方面的有效性和优越性。该方法在稳定性和性能方面均优于基准算法,为解决复杂公交运营场景下的车队控制问题提供了一种新的思路。
🎯 应用场景
该研究成果可应用于城市智能交通管理系统,优化公交车队的运营调度,减少公交车拥堵,提高公交服务质量和乘客满意度。此外,该方法也可推广到其他多智能体控制问题,如交通信号灯控制、无人机集群控制等,具有广泛的应用前景。
📄 摘要(原文)
Bus bunching remains a challenge for urban transit due to stochastic traffic and passenger demand. Traditional solutions rely on multi-agent reinforcement learning (MARL) in loop-line settings, which overlook realistic operations characterized by heterogeneous routes, timetables, fluctuating demand, and varying fleet sizes. We propose a novel single-agent reinforcement learning (RL) framework for bus holding control that avoids the data imbalance and convergence issues of MARL under near-realistic simulation. A bidirectional timetabled network with dynamic passenger demand is constructed. The key innovation is reformulating the multi-agent problem into a single-agent one by augmenting the state space with categorical identifiers (vehicle ID, station ID, time period) in addition to numerical features (headway, occupancy, velocity). This high-dimensional encoding enables single-agent policies to capture inter-agent dependencies, analogous to projecting non-separable inputs into a higher-dimensional space. We further design a structured reward function aligned with operational goals: instead of exponential penalties on headway deviations, a ridge-shaped reward balances uniform headways and schedule adherence. Experiments show that our modified soft actor-critic (SAC) achieves more stable and superior performance than benchmarks, including MADDPG (e.g., -430k vs. -530k under stochastic conditions). These results demonstrate that single-agent deep RL, when enhanced with categorical structuring and schedule-aware rewards, can effectively manage bus holding in non-loop, real-world contexts. This paradigm offers a robust, scalable alternative to MARL frameworks, particularly where agent-specific experiences are imbalanced.