Flowing Straighter with Conditional Flow Matching for Accurate Speech Enhancement
作者: Mattias Cross, Anton Ragni
分类: cs.SD, cs.AI, cs.LG
发布日期: 2025-08-28
备注: preprint, accepted
💡 一句话要点
提出基于条件流匹配的语音增强方法,优化概率路径提升性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音增强 条件流匹配 生成模型 概率路径 直线路径
📋 核心要点
- 现有基于流的语音增强方法依赖弯曲概率路径,其影响尚不明确,可能影响训练效率和泛化能力。
- 论文提出基于条件流匹配的语音增强方法,旨在建模噪声语音和干净语音之间的直线路径,简化训练过程。
- 实验表明,时间无关的方差对样本质量影响更大,且一步推理解决方案可有效提升条件流匹配的效率。
📝 摘要(中文)
目前基于流的生成式语音增强方法学习弯曲的概率路径,用于建模干净语音和噪声语音之间的映射。尽管性能令人印象深刻,但弯曲概率路径的影响尚不清楚。诸如薛定谔桥之类的方法侧重于弯曲路径,其中时间相关的梯度和方差不利于直线路径。机器学习研究的发现表明,直线路径(例如条件流匹配)更容易训练并且提供更好的泛化。在本文中,我们量化了路径直线度对语音增强质量的影响。我们报告了薛定谔桥的实验,表明某些配置会导致更直的路径。相反,我们提出了用于语音增强的独立条件流匹配,该方法对噪声语音和干净语音之间的直线路径进行建模。我们通过实验证明,时间无关的方差比梯度对样本质量有更大的影响。虽然条件流匹配改善了多个语音质量指标,但它需要多个推理步骤。我们通过将训练后的基于流的模型推断为直接预测来纠正这一点,从而提供了一步解决方案。我们的工作表明,与弯曲的时间相关路径相比,更直的时间无关概率路径可以改善生成式语音增强。
🔬 方法详解
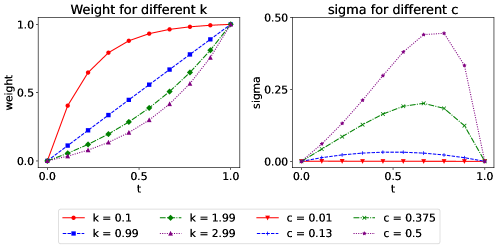
问题定义:现有的基于流的生成式语音增强方法,通过学习弯曲的概率路径来建模噪声语音到干净语音的映射。这种弯曲路径的潜在影响,例如训练难度和泛化能力,尚未被充分研究。此外,一些方法(如薛定谔桥)虽然关注弯曲路径,但其时间相关的梯度和方差可能不利于学习更优的映射关系。
核心思路:论文的核心思路是探索使用直线概率路径进行语音增强的可能性。作者认为,借鉴机器学习领域的研究成果,直线路径(如条件流匹配)可能更容易训练,并具有更好的泛化能力。因此,论文提出使用条件流匹配来建模噪声语音和干净语音之间的直接映射,从而简化学习过程并提升性能。
技术框架:论文提出的方法主要基于条件流匹配(Conditional Flow Matching, CFM)。CFM的核心思想是学习一个时间相关的向量场,使得从噪声语音到干净语音的转换路径尽可能接近直线。具体而言,给定噪声语音和干净语音,CFM的目标是学习一个向量场,该向量场在时间维度上引导噪声语音逐渐演变为干净语音。该框架包含训练和推理两个阶段。在训练阶段,模型学习时间相关的向量场。在推理阶段,模型利用学习到的向量场将噪声语音逐步转换为干净语音。为了加速推理过程,论文还提出了一种一步推理的解决方案。
关键创新:论文的关键创新在于将条件流匹配应用于语音增强任务,并探索了直线概率路径对性能的影响。与传统的基于流的方法不同,该方法直接建模噪声语音和干净语音之间的直线映射,避免了学习复杂的弯曲路径。此外,论文还发现时间无关的方差比梯度对样本质量有更大的影响,这为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:1) 使用条件流匹配来建模噪声语音和干净语音之间的映射;2) 探索时间无关的方差对样本质量的影响;3) 提出一步推理的解决方案,以加速推理过程。在损失函数方面,论文采用了标准的条件流匹配损失函数,该损失函数旨在最小化预测的向量场与真实向量场之间的差异。在网络结构方面,论文使用了标准的神经网络结构来学习时间相关的向量场。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于条件流匹配的语音增强方法在多个语音质量指标上优于基线方法。特别地,论文发现时间无关的方差对样本质量有更大的影响。此外,一步推理解决方案在保证性能的同时,显著降低了推理时间,使其更适用于实际应用。
🎯 应用场景
该研究成果可应用于各种语音增强场景,例如移动通信、语音识别前端处理、助听设备等。通过提升语音质量,改善用户体验,并提高语音识别系统的准确率。未来,该方法有望扩展到其他音频处理任务,如语音分离、语音合成等。
📄 摘要(原文)
Current flow-based generative speech enhancement methods learn curved probability paths which model a mapping between clean and noisy speech. Despite impressive performance, the implications of curved probability paths are unknown. Methods such as Schrodinger bridges focus on curved paths, where time-dependent gradients and variance do not promote straight paths. Findings in machine learning research suggest that straight paths, such as conditional flow matching, are easier to train and offer better generalisation. In this paper we quantify the effect of path straightness on speech enhancement quality. We report experiments with the Schrodinger bridge, where we show that certain configurations lead to straighter paths. Conversely, we propose independent conditional flow-matching for speech enhancement, which models straight paths between noisy and clean speech. We demonstrate empirically that a time-independent variance has a greater effect on sample quality than the gradient. Although conditional flow matching improves several speech quality metrics, it requires multiple inference steps. We rectify this with a one-step solution by inferring the trained flow-based model as if it was directly predictive. Our work suggests that straighter time-independent probability paths improve generative speech enhancement over curved time-dependent paths.