Uncertainty Under the Curve: A Sequence-Level Entropy Area Metric for Reasoning LLM
作者: Yongfu Zhu, Lin Sun, Guangxiang Zhao, Weihong Lin, Xiangzheng Zhang
分类: cs.AI
发布日期: 2025-08-28
备注: Under review for AAAI 2026
💡 一句话要点
提出熵面积分数(EAS),用于量化推理LLM生成过程中的不确定性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 熵面积分数 数据选择 模型评估
📋 核心要点
- 现有方法缺乏有效量化LLM推理过程中不确定性的指标,限制了数据选择和模型优化。
- 提出熵面积分数(EAS),利用模型自身token级别的预测熵来捕捉生成过程中的不确定性演变。
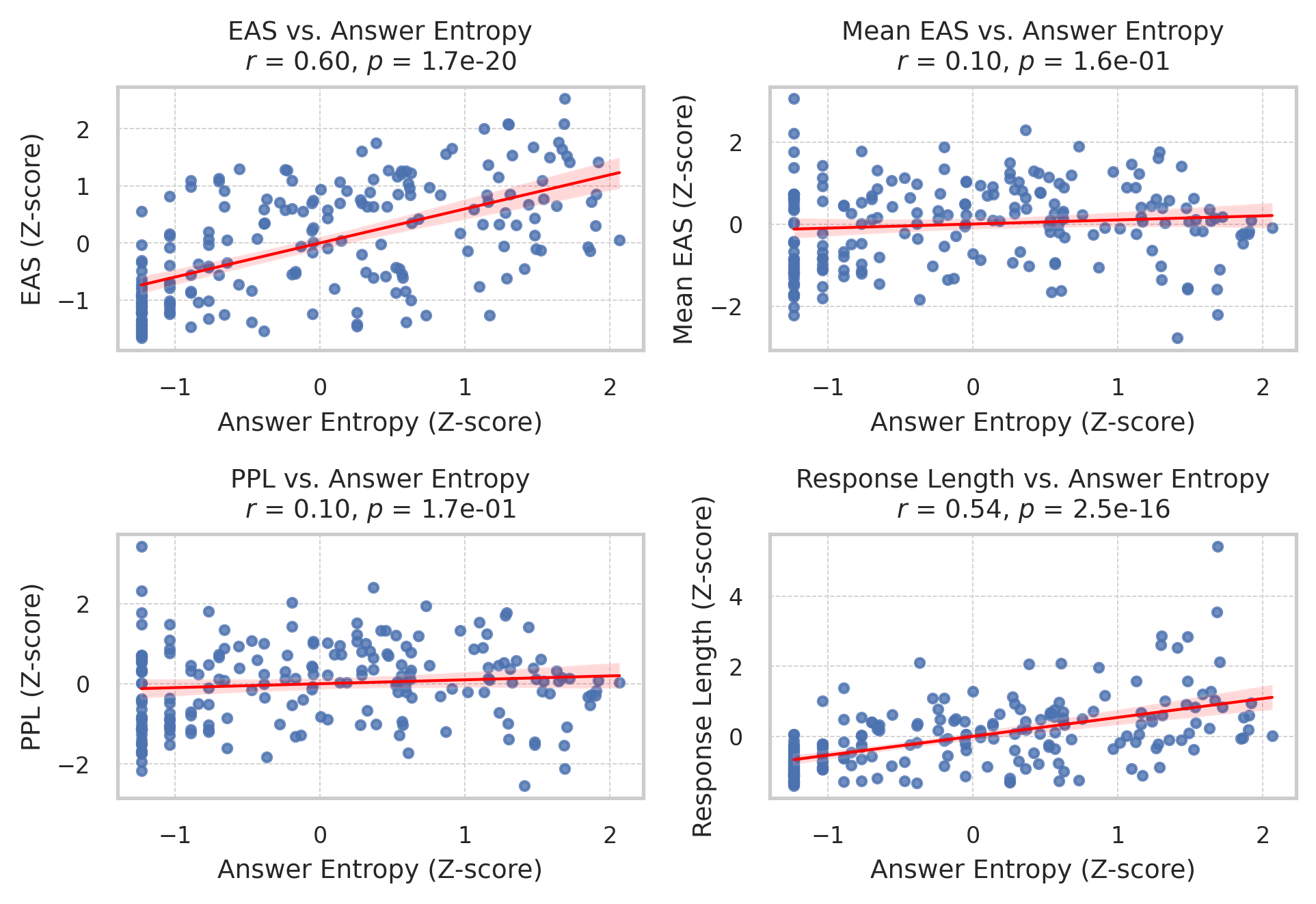
- 实验表明EAS与答案熵高度相关,且在训练数据选择中优于Pass Rate过滤,提升学生模型准确率。
📝 摘要(中文)
本文提出了一种简单而有效的指标——熵面积分数(EAS),用于量化推理大型语言模型(LLM)在答案生成过程中的不确定性。EAS不需要外部模型或重复采样,它整合了模型自身的token级别预测熵,以捕捉生成过程中不确定性的演变。实验结果表明,EAS与跨模型和数据集的答案熵密切相关。在训练数据选择方面,EAS能够识别高潜力样本,并在相同的样本预算下始终优于通过Pass Rate进行过滤的方法,从而提高学生模型在数学基准测试中的准确性。EAS既高效又具有可解释性,为LLM训练中的不确定性建模和数据质量评估提供了一种实用的工具。
🔬 方法详解
问题定义:现有的大型语言模型在推理过程中,其生成答案的不确定性难以有效量化。传统的Pass Rate等方法无法准确评估数据质量,而重复采样的方法效率低下。因此,如何高效且准确地量化LLM生成过程中的不确定性,成为一个亟待解决的问题。
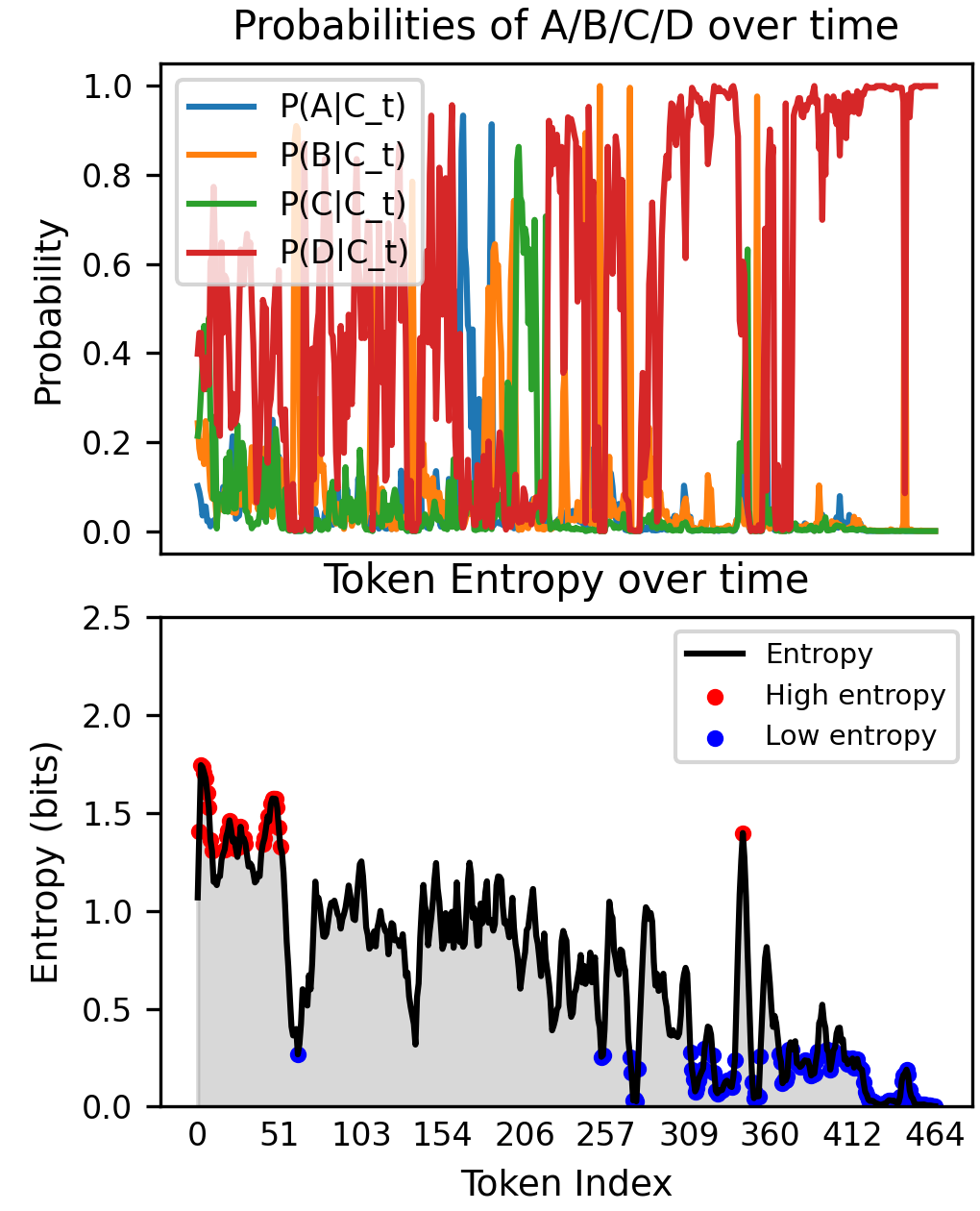
核心思路:论文的核心思路是利用LLM自身在生成token时的预测熵来反映其不确定性。具体来说,模型在生成每个token时都会给出一个概率分布,熵可以衡量这个分布的混乱程度,熵越高表示模型越不确定。通过整合整个生成序列的token级别熵,可以得到一个序列级别的整体不确定性度量。
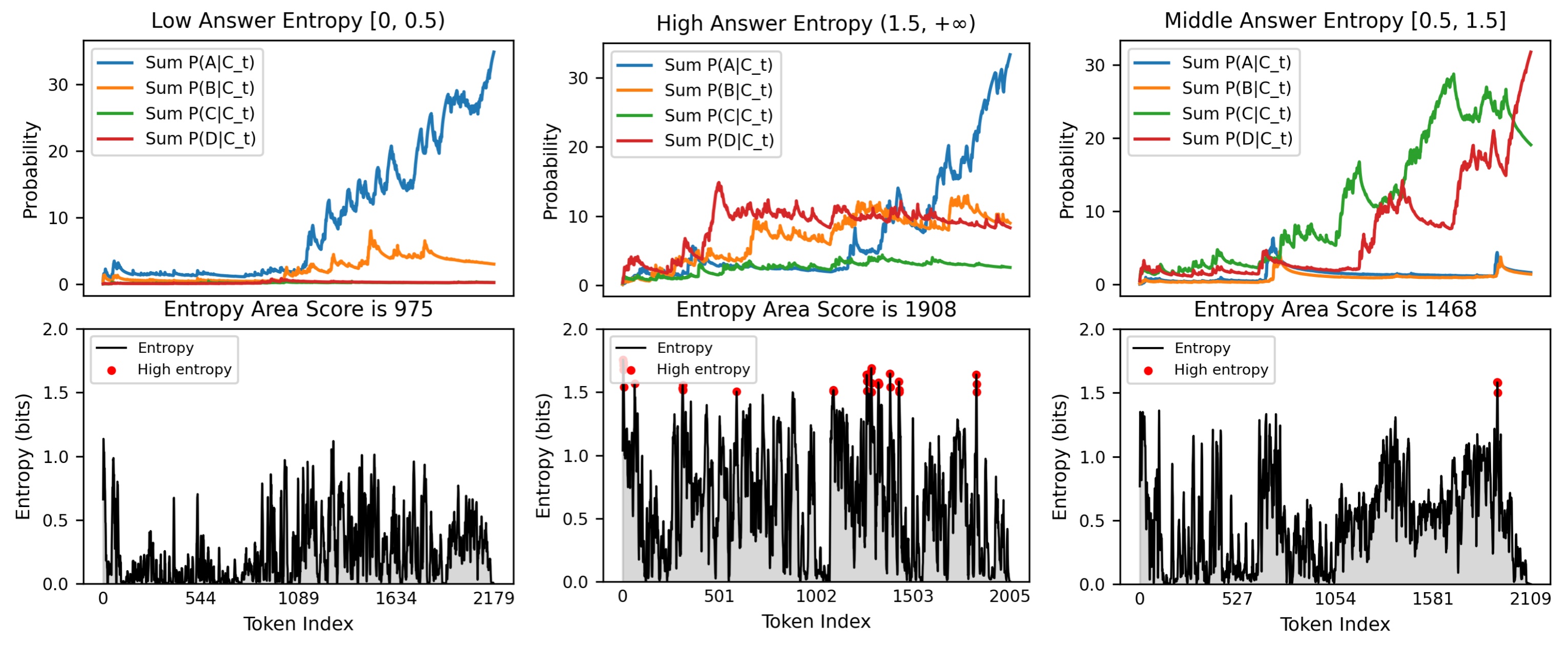
技术框架:EAS的计算流程如下:1. 对于给定的输入,LLM生成一个答案序列。2. 在生成每个token时,记录模型预测的概率分布,并计算该分布的熵。3. 将所有token的熵值进行累加,得到一个序列级别的熵值。4. 将该熵值作为EAS,用于衡量模型生成该答案的不确定性。整个过程不需要额外的模型或重复采样。
关键创新:EAS的关键创新在于它利用了LLM自身的信息(token级别的预测熵)来量化不确定性,避免了对外部模型的依赖,也无需进行耗时的重复采样。此外,EAS通过整合整个生成序列的熵,能够更全面地反映模型在生成过程中的不确定性演变。
关键设计:EAS的计算非常简单,只需要计算每个token的熵,然后将它们累加即可。熵的计算公式为:H(p) = - Σ p(i) * log(p(i)),其中p(i)是模型预测的第i个token的概率。没有涉及复杂的参数设置或网络结构,易于实现和应用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EAS与答案熵具有很强的相关性,验证了其有效性。在训练数据选择方面,EAS在相同样本预算下始终优于Pass Rate过滤方法,在数学基准测试中,使用EAS选择的数据训练的学生模型准确率得到了显著提升。这些结果表明EAS是一种高效且实用的不确定性建模工具。
🎯 应用场景
EAS可应用于LLM的训练数据选择、模型评估和优化。通过EAS筛选高质量训练数据,可以提升模型性能。在模型评估中,EAS可以作为一种补充指标,衡量模型生成答案的可靠性。此外,EAS还可以用于指导模型优化,例如,通过降低高EAS样本的生成不确定性来提高模型的鲁棒性。
📄 摘要(原文)
In this work, we introduce Entropy Area Score (EAS), a simple yet effective metric to quantify uncertainty in the answer generation process of reasoning large language models (LLMs). EAS requires neither external models nor repeated sampling, it integrates token-level predictive entropy from the model itself to capture the evolution of uncertainty during generation. Empirical results show that EAS is strongly correlated with answer entropy across models and datasets. In training data selection, EAS identifies high-potential samples and consistently outperforms Pass Rate filtering under equal sample budgets, improving student model accuracy on math benchmarks. EAS is both efficient and interpretable, offering a practical tool for uncertainty modeling and data quality assessment in LLM training.