AI-SearchPlanner: Modular Agentic Search via Pareto-Optimal Multi-Objective Reinforcement Learning
作者: Lang Mei, Zhihan Yang, Xiaohan Yu, Huanyao Zhang, Chong Chen
分类: cs.AI
发布日期: 2025-08-28 (更新: 2025-12-27)
💡 一句话要点
AI-SearchPlanner:通过帕累托最优多目标强化学习实现模块化Agent搜索
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 搜索规划 大型语言模型 问答系统 多目标优化
📋 核心要点
- 现有基于强化学习的搜索Agent依赖单一LLM处理搜索规划和问答,难以同时优化两种能力。
- AI-SearchPlanner解耦搜索规划器和问答生成器,专门训练小型LLM进行搜索规划,提升效率。
- 实验表明,AI-SearchPlanner在有效性和效率上优于现有方法,并具有良好的泛化能力。
📝 摘要(中文)
本文提出AI-SearchPlanner,一个新颖的强化学习框架,旨在通过专注于搜索规划来提升冻结的问答(QA)模型的性能。现有基于强化学习的搜索Agent依赖于单个大型语言模型(LLM)以端到端的方式处理搜索规划和问答任务,这限制了它们同时优化两种能力。AI-SearchPlanner引入了三个关键创新:1) 解耦搜索规划器和生成器的架构,2) 用于搜索规划的双重奖励对齐,以及 3) 规划效用和成本的帕累托优化,以实现目标。在真实世界数据集上的大量实验表明,AI-SearchPlanner在有效性和效率方面均优于现有的基于强化学习的搜索Agent,同时在不同的冻结QA模型和数据领域中表现出强大的泛化能力。
🔬 方法详解
问题定义:现有基于强化学习的搜索Agent通常采用端到端的方式,使用单个大型语言模型同时处理搜索规划和问答任务。这种方式的痛点在于,难以同时优化搜索规划和问答两个不同的能力。尤其是在实际应用中,高质量的问答通常需要大型的、冻结的LLM(如GPT-4),而端到端的方式限制了对搜索规划能力的针对性优化。
核心思路:AI-SearchPlanner的核心思路是将搜索规划和问答生成两个模块解耦。具体而言,使用一个小型、可训练的LLM专门负责搜索规划,而使用一个大型、冻结的LLM负责问答生成。通过这种解耦,可以更加高效地训练和优化搜索规划模块,从而提升整体的搜索效果。同时,利用双重奖励对齐和帕累托优化,在规划效用和成本之间取得平衡。
技术框架:AI-SearchPlanner的整体架构包含两个主要模块:搜索规划器(Search Planner)和问答生成器(Question-Answering Generator)。搜索规划器是一个小型、可训练的LLM,负责根据问题生成搜索查询。问答生成器是一个大型、冻结的LLM,负责根据搜索结果生成最终答案。强化学习算法用于训练搜索规划器,使其能够生成更有效的搜索查询,从而提升问答生成器的性能。
关键创新:AI-SearchPlanner的关键创新在于以下三点:1) 解耦搜索规划器和生成器的架构,允许针对性地优化搜索规划能力;2) 引入双重奖励对齐机制,更好地指导搜索规划器的训练;3) 采用帕累托优化方法,在规划效用和成本之间取得平衡。与现有方法的本质区别在于,AI-SearchPlanner不再依赖单个LLM完成所有任务,而是将任务分解为搜索规划和问答生成两个独立的模块,从而提升了整体的效率和性能。
关键设计:AI-SearchPlanner的关键设计包括:1) 使用小型LLM(例如,参数量较小的预训练模型)作为搜索规划器,以降低训练成本;2) 设计双重奖励函数,分别衡量搜索结果的相关性和问答的准确性;3) 使用帕累托优化算法,在搜索规划的效用(例如,问答准确率的提升)和成本(例如,搜索次数)之间进行权衡;4) 强化学习算法的选择,例如,可以使用PPO等算法来训练搜索规划器。
🖼️ 关键图片

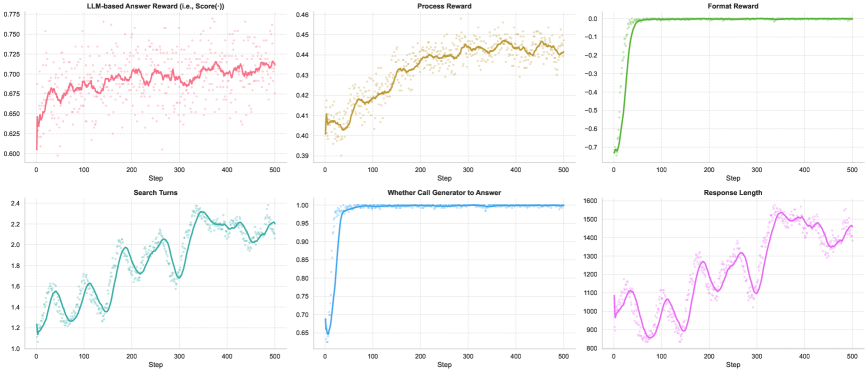

📊 实验亮点
实验结果表明,AI-SearchPlanner在多个真实世界数据集上优于现有的基于强化学习的搜索Agent。具体而言,AI-SearchPlanner在问答准确率方面取得了显著提升,同时降低了搜索成本。此外,AI-SearchPlanner还表现出良好的泛化能力,可以在不同的冻结QA模型和数据领域中取得一致的性能提升。例如,在某个数据集上,AI-SearchPlanner的问答准确率比基线方法提高了5个百分点,同时搜索次数减少了20%。
🎯 应用场景
AI-SearchPlanner具有广泛的应用前景,可以应用于各种需要信息检索和问答的场景,例如智能客服、搜索引擎、知识图谱问答等。通过提升搜索规划的效率和准确性,AI-SearchPlanner可以帮助用户更快地找到所需的信息,并获得更准确的答案。未来,该研究可以进一步扩展到多模态搜索、个性化搜索等领域,为用户提供更加智能化的信息服务。
📄 摘要(原文)
Recent studies have explored integrating Large Language Models (LLMs) with search engines to leverage both the LLMs' internal pre-trained knowledge and external information. Specially, reinforcement learning (RL) has emerged as a promising paradigm for enhancing LLM reasoning through multi-turn interactions with search engines. However, existing RL-based search agents rely on a single LLM to handle both search planning and question-answering (QA) tasks in an end-to-end manner, which limits their ability to optimize both capabilities simultaneously. In practice, sophisticated AI search systems often employ a large, frozen LLM (e.g., GPT-4, DeepSeek-R1) to ensure high-quality QA. Thus, a more effective and efficient approach is to utilize a small, trainable LLM dedicated to search planning. In this paper, we propose \textbf{AI-SearchPlanner}, a novel reinforcement learning framework designed to enhance the performance of frozen QA models by focusing on search planning. Specifically, our approach introduces three key innovations: 1) Decoupling the Architecture of the Search Planner and Generator, 2) Dual-Reward Alignment for Search Planning, and 3) Pareto Optimization of Planning Utility and Cost, to achieve the objectives. Extensive experiments on real-world datasets demonstrate that AI SearchPlanner outperforms existing RL-based search agents in both effectiveness and efficiency, while exhibiting strong generalization capabilities across diverse frozen QA models and data domains.