Flexible metadata harvesting for ecology using large language models
作者: Zehao Lu, Thijs L van der Plas, Parinaz Rashidi, W Daniel Kissling, Ioannis N Athanasiadis
分类: cs.DL, cs.AI, cs.DB
发布日期: 2025-08-21 (更新: 2025-10-06)
DOI: 10.1007/978-3-032-06136-2_32
💡 一句话要点
提出基于LLM的元数据收集器,解决生态数据整合中元数据异构问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 元数据提取 生态学数据 数据整合 知识图谱 虚拟研究环境 自然语言处理
📋 核心要点
- 生态学研究面临数据来源多样、元数据标准不统一的挑战,阻碍了数据集的整合与重用。
- 该论文提出一种基于大型语言模型(LLM)的元数据收集器,能够灵活地从不同来源提取并统一元数据。
- 实验验证了该工具在提取结构化和非结构化元数据方面的准确性,并能识别数据集之间的关联。
📝 摘要(中文)
大型开放数据集能够加速生态学研究,特别是通过允许多源数据集的重用,从而使研究人员能够开发新的见解。然而,为了找到最适合组合和集成的数据集,研究人员必须浏览具有不同元数据可用性和标准的各种生态和环境数据提供商平台。为了克服这个障碍,我们开发了一种基于大型语言模型(LLM)的元数据收集器,它可以灵活地从任何数据集的登陆页面提取元数据,并使用现有的元数据标准将其转换为用户定义的统一格式。我们验证了我们的工具能够以相同的准确度提取结构化和非结构化元数据,这得益于我们的LLM后处理协议。此外,我们利用LLM通过计算嵌入相似性和统一提取的元数据格式以实现基于规则的处理来识别数据集之间的链接。因此,我们的工具可以灵活地链接不同数据集的元数据,例如,可用于本体创建或基于图的查询,以便在虚拟研究环境中查找相关的生态和环境数据集。
🔬 方法详解
问题定义:生态学研究依赖于多源数据集的整合,但不同数据提供商平台的元数据标准各异,导致研究人员难以找到并整合合适的数据集。现有方法难以有效处理异构的元数据,阻碍了生态学研究的进展。
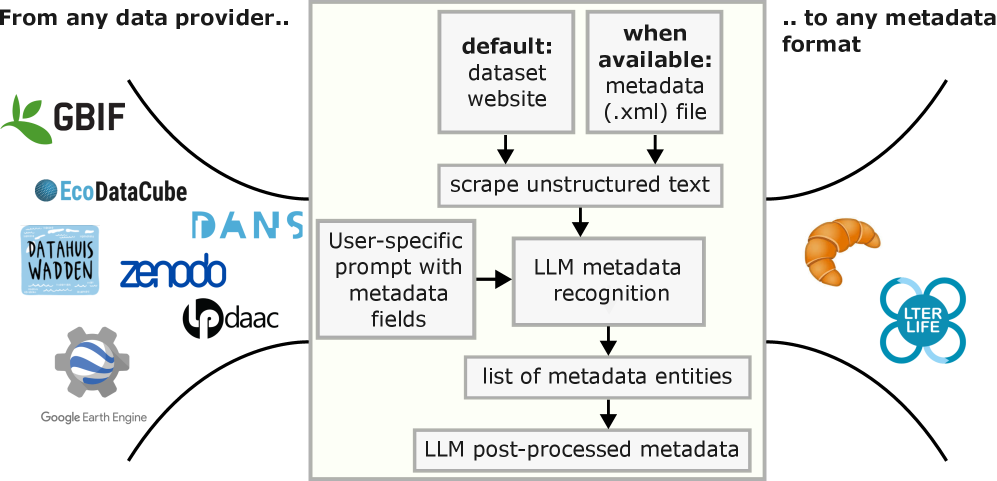
核心思路:利用大型语言模型(LLM)的强大文本理解和生成能力,构建一个灵活的元数据收集器。该收集器能够从任意数据集的登陆页面提取元数据,并将其转换为用户定义的统一格式,从而实现元数据的标准化和整合。
技术框架:该工具的核心流程包括:1) 从数据集登陆页面抓取数据;2) 使用LLM提取结构化和非结构化元数据;3) 利用LLM进行后处理,提高元数据质量;4) 基于LLM计算嵌入相似度或进行规则处理,识别数据集之间的链接。整体架构旨在实现元数据的自动化提取、标准化和关联。
关键创新:该方法的核心创新在于利用LLM灵活处理各种格式的元数据,无需预先定义严格的提取规则。通过LLM的后处理,可以有效提高元数据提取的准确性和完整性。此外,利用LLM识别数据集之间的链接,为构建生态学知识图谱奠定了基础。
关键设计:该工具的关键设计包括:1) 使用特定的prompt工程来指导LLM进行元数据提取;2) 设计LLM后处理协议,例如纠正拼写错误、统一术语等;3) 利用LLM计算数据集元数据的嵌入向量,并通过相似度计算识别相关数据集;4) 定义基于规则的处理流程,例如基于关键词匹配识别数据集之间的关联。
🖼️ 关键图片

📊 实验亮点
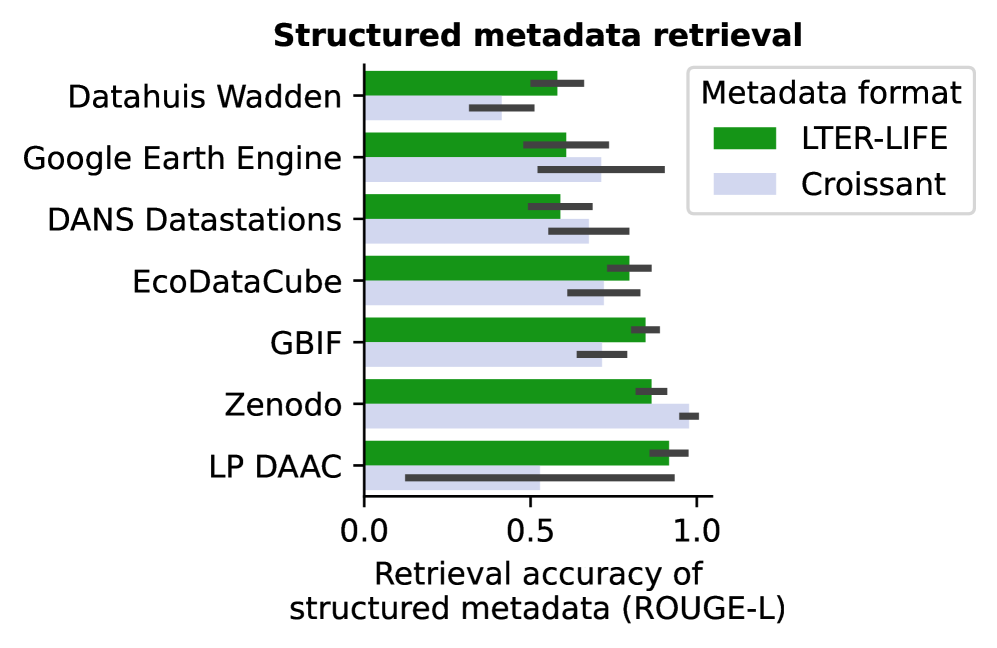
该研究验证了基于LLM的元数据收集器能够以较高的准确度提取结构化和非结构化元数据。通过LLM后处理,元数据质量得到显著提升。此外,该工具能够有效识别数据集之间的链接,为构建生态学知识图谱提供了可能。具体性能数据未知。
🎯 应用场景
该研究成果可应用于构建生态学虚拟研究环境,帮助研究人员快速发现和整合所需的数据集。通过构建生态学知识图谱,可以促进跨领域的数据共享和知识发现,加速生态学研究的进展。该方法也可推广到其他科学领域,解决数据整合和知识发现的难题。
📄 摘要(原文)
Large, open datasets can accelerate ecological research, particularly by enabling researchers to develop new insights by reusing datasets from multiple sources. However, to find the most suitable datasets to combine and integrate, researchers must navigate diverse ecological and environmental data provider platforms with varying metadata availability and standards. To overcome this obstacle, we have developed a large language model (LLM)-based metadata harvester that flexibly extracts metadata from any dataset's landing page, and converts these to a user-defined, unified format using existing metadata standards. We validate that our tool is able to extract both structured and unstructured metadata with equal accuracy, aided by our LLM post-processing protocol. Furthermore, we utilise LLMs to identify links between datasets, both by calculating embedding similarity and by unifying the formats of extracted metadata to enable rule-based processing. Our tool, which flexibly links the metadata of different datasets, can therefore be used for ontology creation or graph-based queries, for example, to find relevant ecological and environmental datasets in a virtual research environment.