HyperFlexis: Joint Design of Algorithms and Systems for Multi-SLO Serving and Fast Scaling
作者: Zahra Yousefijamarani, Xinglu Wang, Qian Wang, Morgan Lindsay Heisler, Taha Shabani, Niloofar Gholipour, Parham Yassini, Hong Chang, Kan Chen, Qiantao Zhang, Xiaolong Bai, Jiannan Wang, Ying Xiong, Yong Zhang, Zhenan Fan
分类: cs.DC, cs.AI
发布日期: 2025-08-21 (更新: 2025-09-25)
💡 一句话要点
HyperFlexis:面向多SLO服务和快速扩展的算法与系统联合设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型服务 多SLO调度 快速扩展 Prefill/Decode分离 设备到设备权重传输
📋 核心要点
- 现有LLM服务系统难以应对请求的多样性,尤其是在满足不同阶段的SLO和快速扩展方面。
- HyperFlexis通过算法和系统联合设计,优化调度和扩展,以满足多SLO需求,并支持多种架构。
- 实验表明,HyperFlexis能显著提高SLO达成率,降低请求延迟,并实现与现有技术相当的成本。
📝 摘要(中文)
现代大型语言模型(LLM)服务系统面临着来自具有不同长度、优先级和阶段特定服务级别目标(SLO)的高度可变请求的挑战。为了满足这些需求,需要实时调度、快速且经济高效的扩展,以及对同地和分离的Prefill/Decode(P/D)架构的支持。我们提出了HyperFlexis,一个统一的LLM服务系统,它集成了算法和系统级创新,以联合优化多SLO下的调度和扩展。它具有一个多SLO感知调度器,该调度器利用预算估计和请求优先级排序来确保主动地满足新请求和正在进行的请求的SLO。该系统支持用于P/D分离架构的预填充和解码阶段的多SLO调度以及KV缓存传输。它还支持经济高效的扩展决策、扩展期间的预填充-解码实例链接以及快速的P/D角色转换。为了加速扩展并减少冷启动延迟,提出了一种设备到设备(D2D)权重传输机制,该机制可将权重加载开销降低高达19.39倍。这些优化使系统能够实现高达4.44倍的SLO实现率,降低65.82%的请求延迟,并与最先进的基线实现成本均等。代码即将发布。
🔬 方法详解
问题定义:现有LLM服务系统面临着处理具有不同长度、优先级和阶段特定SLO的高度可变请求的挑战。传统的调度和扩展方法难以在满足所有这些需求的同时,保持低延迟和高资源利用率。此外,现有方法在支持分离的Prefill/Decode(P/D)架构和快速扩展方面存在不足,导致冷启动延迟高和资源浪费。
核心思路:HyperFlexis的核心思路是通过算法和系统级的联合设计,实现对调度和扩展的协同优化。它通过多SLO感知调度器,利用预算估计和请求优先级排序,主动满足新请求和正在进行的请求的SLO。同时,通过支持P/D分离架构和快速角色转换,以及D2D权重传输机制,加速扩展并降低冷启动延迟。
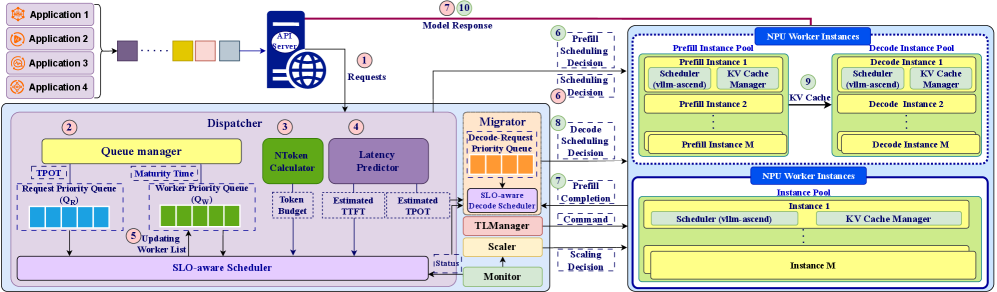
技术框架:HyperFlexis的整体架构包含以下主要模块:1) 多SLO感知调度器:负责根据请求的优先级和预算,进行实时调度;2) P/D分离架构支持:支持预填充和解码阶段的多SLO调度以及KV缓存传输;3) 快速扩展机制:支持经济高效的扩展决策、实例链接和快速角色转换;4) D2D权重传输:通过设备到设备的数据传输,加速权重加载。
关键创新:HyperFlexis的关键创新在于:1) 多SLO感知调度器,能够根据请求的优先级和预算,动态调整调度策略,从而更好地满足不同请求的SLO;2) D2D权重传输机制,通过设备到设备的数据传输,显著降低了权重加载的开销,加速了扩展过程。
关键设计:多SLO感知调度器采用预算估计和请求优先级排序机制。预算估计用于预测请求在不同阶段所需的资源,请求优先级排序则根据请求的重要性进行排序。D2D权重传输机制通过优化数据传输路径和压缩算法,减少了数据传输的时间和带宽占用。
🖼️ 关键图片

📊 实验亮点
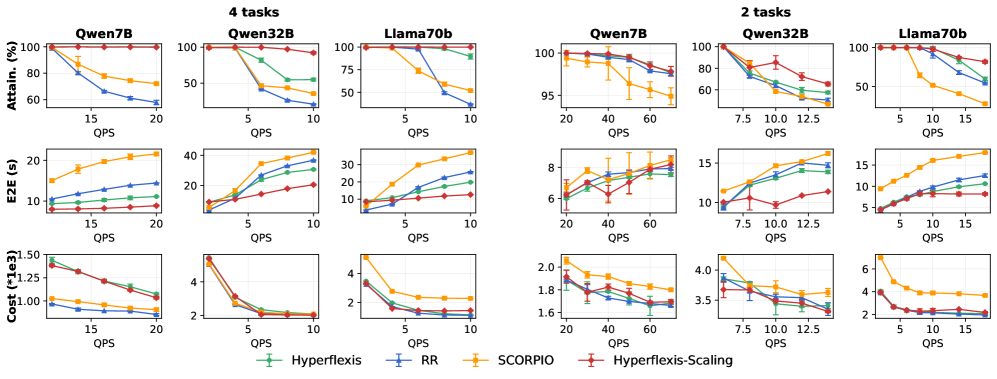
HyperFlexis通过算法和系统联合优化,实现了显著的性能提升。实验结果表明,HyperFlexis能够实现高达4.44倍的SLO达成率,降低65.82%的请求延迟,并与最先进的基线实现成本均等。D2D权重传输机制可以将权重加载开销降低高达19.39倍。
🎯 应用场景
HyperFlexis可应用于各种需要高性能和低延迟的LLM服务场景,例如在线问答、文本生成、代码生成等。它能够提高服务质量,降低运营成本,并支持更大规模的用户并发访问。该研究成果对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Modern large language model (LLM) serving systems face challenges from highly variable requests with diverse lengths, priorities, and stage-specific service-level objectives (SLOs). Meeting these requires real-time scheduling, rapid and cost-effective scaling, and support for both collocated and disaggregated Prefill/Decode (P/D) architectures. We present HyperFlexis, a unified LLM serving system that integrates algorithmic and system-level innovations to jointly optimize scheduling and scaling under multiple SLOs. It features a multi-SLO-aware scheduler that leverages budget estimation and request prioritization to ensure proactive SLO compliance for both new and ongoing requests. The system supports prefill- and decode-stage multi-SLO scheduling for P/D-disaggregated architectures and KV cache transfers. It also enables cost-effective scaling decisions, prefill-decode instance linking during scaling, and rapid P/D role transitions. To accelerate scaling and reduce cold-start latency, a device-to-device (D2D) weight transfer mechanism is proposed that lowers weight loading overhead by up to 19.39$\times$. These optimizations allow the system to achieve up to 4.44$\times$ higher SLO attainment, 65.82% lower request latency, and cost parity with state-of-the-art baselines. The code will be released soon.