SyGra: A Unified Graph-Based Framework for Scalable Generation, Quality Tagging, and Management of Synthetic Data
作者: Bidyapati Pradhan, Surajit Dasgupta, Amit Kumar Saha, Omkar Anustoop, Sriram Puttagunta, Vipul Mittal, Gopal Sarda
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-08-21 (更新: 2025-12-11)
💡 一句话要点
SyGra:统一的图框架,用于合成数据的可扩展生成、质量标记和管理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 大型语言模型 质量评估 对话系统 图神经网络
📋 核心要点
- 大型语言模型(LLM)的发展严重依赖于高质量数据集,而现有数据准备过程成本高昂且耗时。
- SyGra框架通过模块化流水线和双阶段质量标记机制,实现了可扩展、可配置和高质量的合成数据生成。
- 该框架支持SFT和DPO等多种训练范式,并能有效降低LLM训练中数据准备的开销。
📝 摘要(中文)
本文提出了一种全面的合成数据生成框架,旨在促进可扩展、可配置和高保真的合成数据生成,以满足监督式微调(SFT)和直接偏好优化(DPO)等对齐任务的需求。该方法采用模块化和基于配置的流水线,能够以最小的人工干预建模复杂的对话流程。该框架使用双阶段质量标记机制,结合启发式规则和基于LLM的评估,自动过滤和评分从OASST格式的对话中提取的数据,确保高质量对话样本的整理。生成的数据集以灵活的模式构建,支持SFT和DPO用例,从而能够无缝集成到各种训练工作流程中。这些创新共同为大规模生成和管理合成对话数据提供了一个强大的解决方案,显著降低了LLM训练流水线中数据准备的开销。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练中高质量对话数据稀缺且准备成本高昂的问题。现有方法通常依赖于人工标注或简单的规则生成,难以保证数据的质量和多样性,且可扩展性差。这些痛点严重制约了LLM的训练效率和性能。
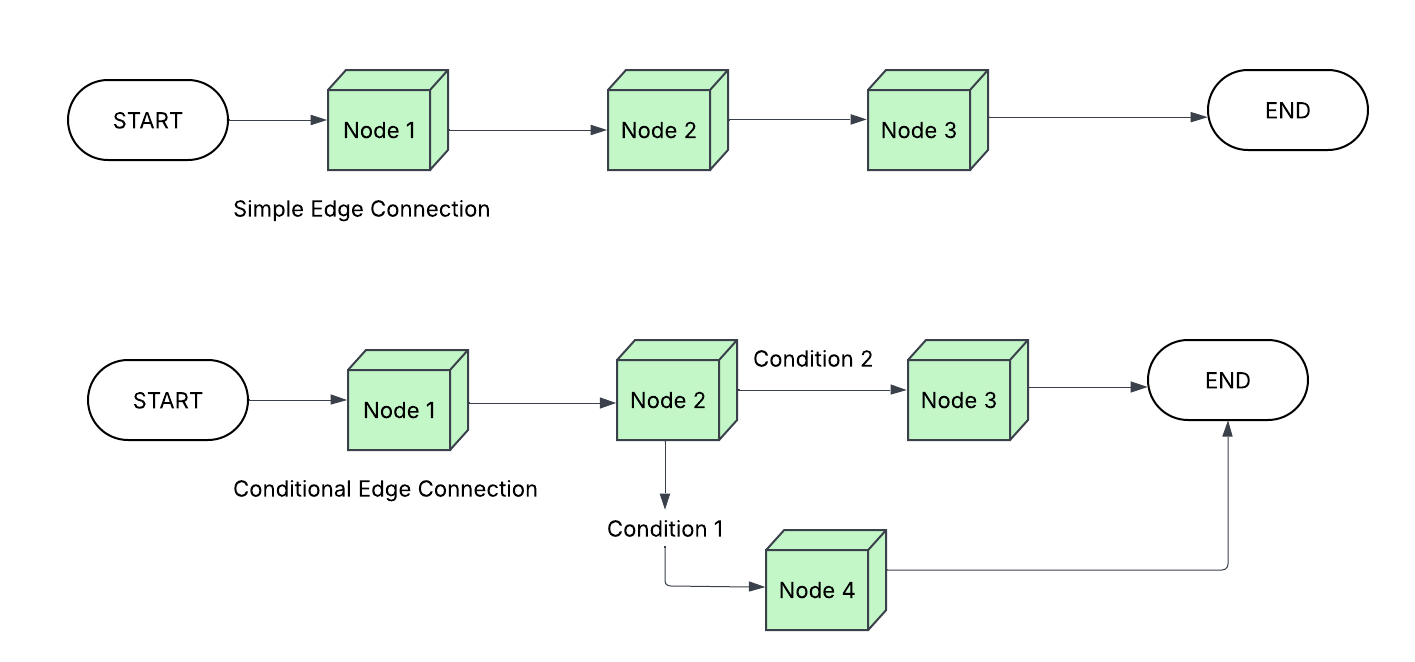
核心思路:论文的核心思路是构建一个基于图的统一框架,通过模块化的流水线自动生成、标记和管理合成数据。该框架利用可配置的对话流程建模和双阶段质量评估机制,在保证数据质量的同时,实现数据的可扩展生成。通过将数据组织成支持SFT和DPO等多种训练范式的灵活模式,简化了数据集成过程。
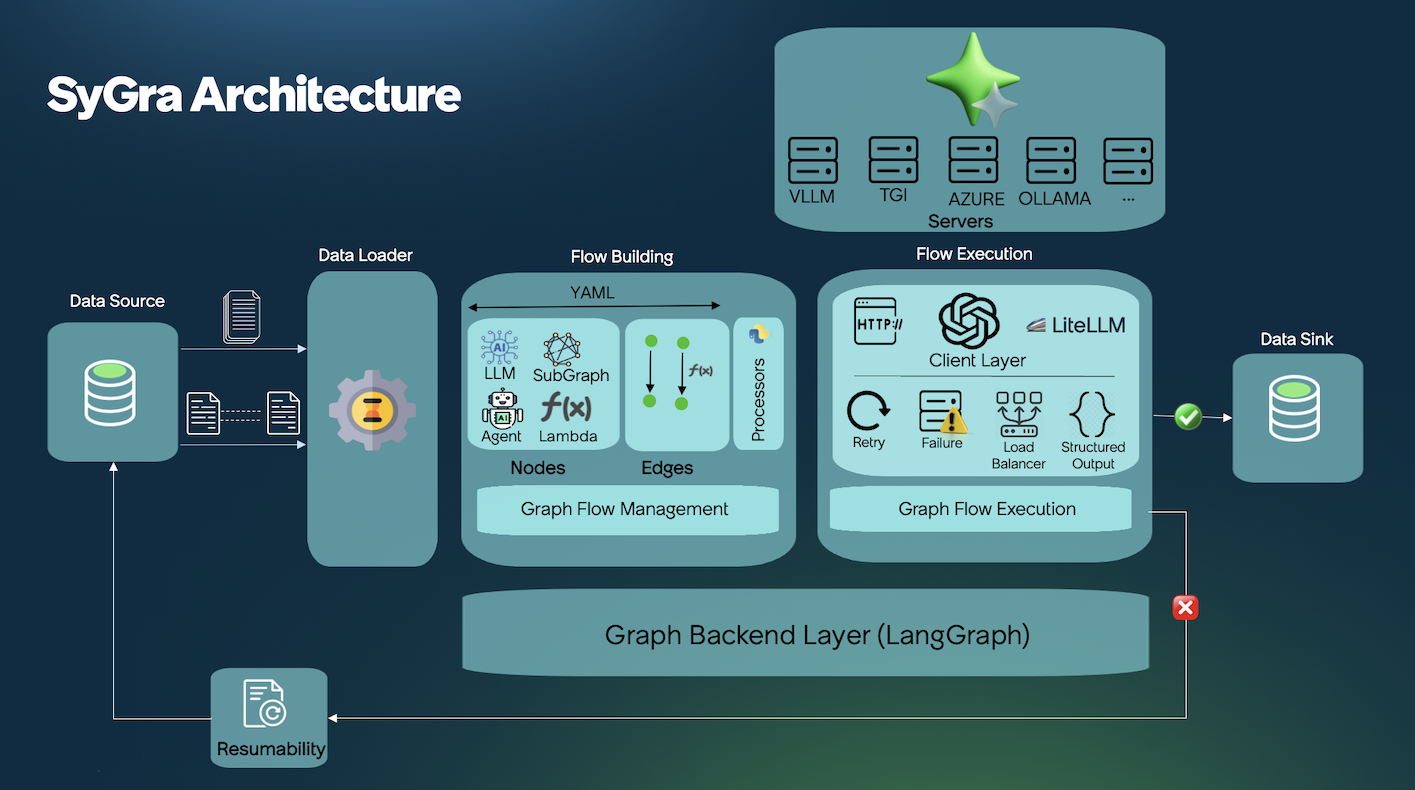
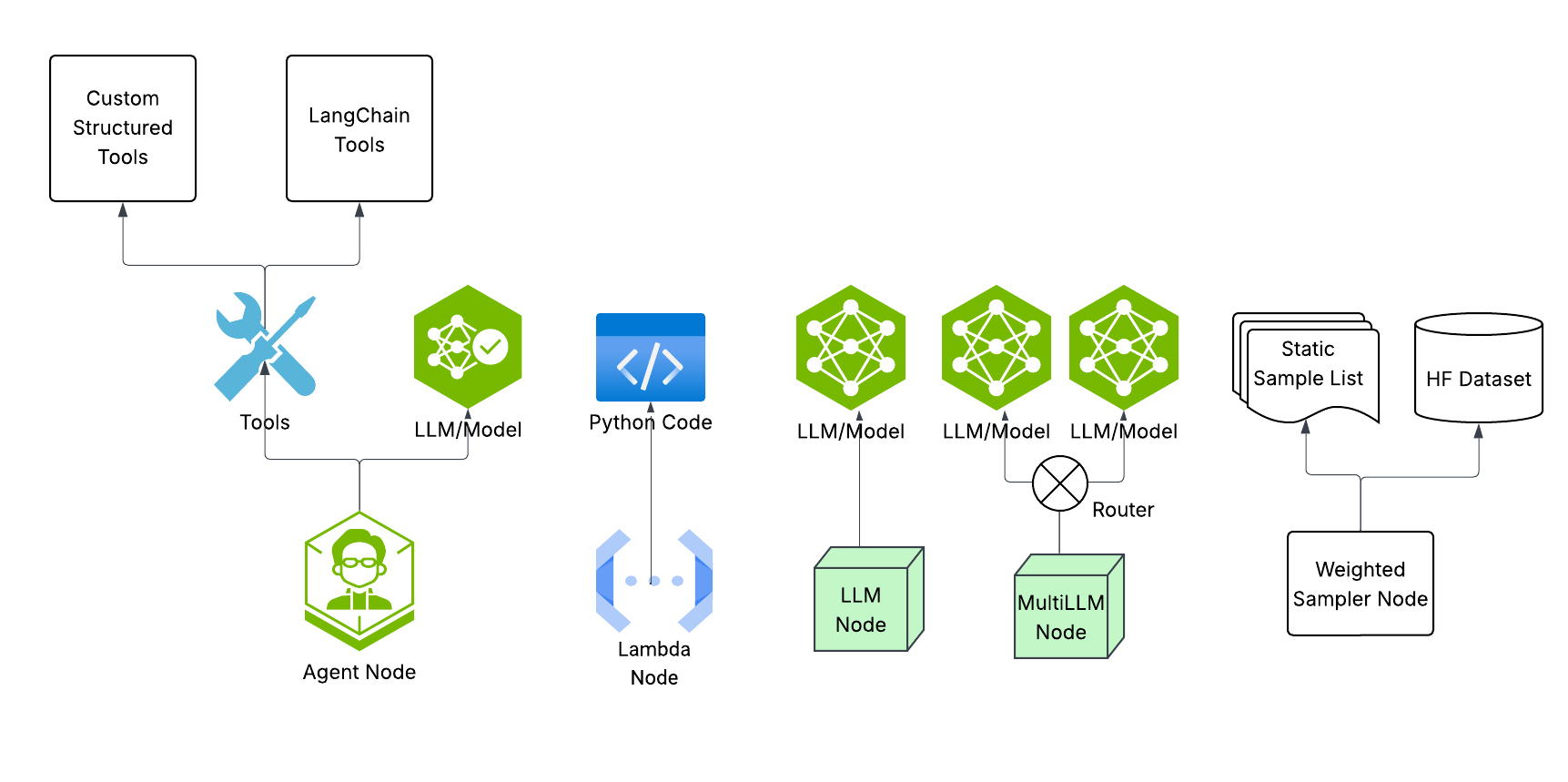
技术框架:SyGra框架包含以下主要模块:1) 对话生成模块:基于可配置的对话流程图生成对话数据;2) 启发式规则质量标记模块:使用预定义的规则对生成的数据进行初步筛选;3) LLM质量评估模块:利用大型语言模型对数据进行更细致的质量评估和评分;4) 数据管理模块:以灵活的模式存储和管理数据,支持SFT和DPO等训练任务。
关键创新:该框架的关键创新在于:1) 统一的图结构:使用图结构来表示复杂的对话流程,提高了生成过程的灵活性和可配置性;2) 双阶段质量评估:结合启发式规则和LLM评估,提高了数据质量评估的准确性和效率;3) 灵活的数据模式:支持SFT和DPO等多种训练范式,简化了数据集成过程。与现有方法相比,SyGra框架能够以更低的成本生成更高质量、更多样化的合成数据。
关键设计:对话流程图的设计允许用户自定义对话的主题、角色和交互方式。启发式规则包括关键词匹配、长度限制等。LLM质量评估使用预训练的LLM对对话的流畅性、相关性和信息量进行评分。数据的存储模式包括对话文本、质量评分和元数据等。
🖼️ 关键图片
📊 实验亮点
论文提出了SyGra框架,能够生成高质量的合成对话数据,并支持SFT和DPO等多种训练范式。通过双阶段质量评估,有效提升了数据质量。实验结果(具体数值未知)表明,使用SyGra框架生成的数据能够有效提升LLM的性能。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练、微调和对齐等任务。通过生成高质量的合成数据,可以有效提升LLM的性能和泛化能力,并降低数据准备的成本。此外,该框架还可以应用于对话系统、智能客服等领域,用于生成训练数据和评估对话质量。
📄 摘要(原文)
The advancement of large language models (LLMs) is critically dependent on the availability of high-quality datasets for Supervised Fine-Tuning (SFT), alignment tasks like Direct Preference Optimization (DPO), etc. In this work, we present a comprehensive synthetic data generation framework that facilitates scalable, configurable, and high-fidelity generation of synthetic data tailored for these training paradigms. Our approach employs a modular and configuration-based pipeline capable of modeling complex dialogue flows with minimal manual intervention. This framework uses a dual-stage quality tagging mechanism, combining heuristic rules and LLM-based evaluations, to automatically filter and score data extracted from OASST-formatted conversations, ensuring the curation of high-quality dialogue samples. The resulting datasets are structured under a flexible schema supporting both SFT and DPO use cases, enabling seamless integration into diverse training workflows. Together, these innovations offer a robust solution for generating and managing synthetic conversational data at scale, significantly reducing the overhead of data preparation in LLM training pipelines.