An Empirical Study of Knowledge Distillation for Code Understanding Tasks
作者: Ruiqi Wang, Zezhou Yang, Cuiyun Gao, Xin Xia, Qing Liao
分类: cs.SE, cs.AI
发布日期: 2025-08-21
备注: Accepted by ICSE 2026 (Cycle 1)
💡 一句话要点
针对代码理解任务,系统性研究知识蒸馏的有效性与应用方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 代码理解 预训练语言模型 模型压缩 代码智能
📋 核心要点
- 现有预训练语言模型在代码理解任务中计算开销大、推理延迟高,难以大规模部署。
- 采用知识蒸馏技术,将大型教师模型的知识迁移到小型学生模型,实现模型压缩和加速。
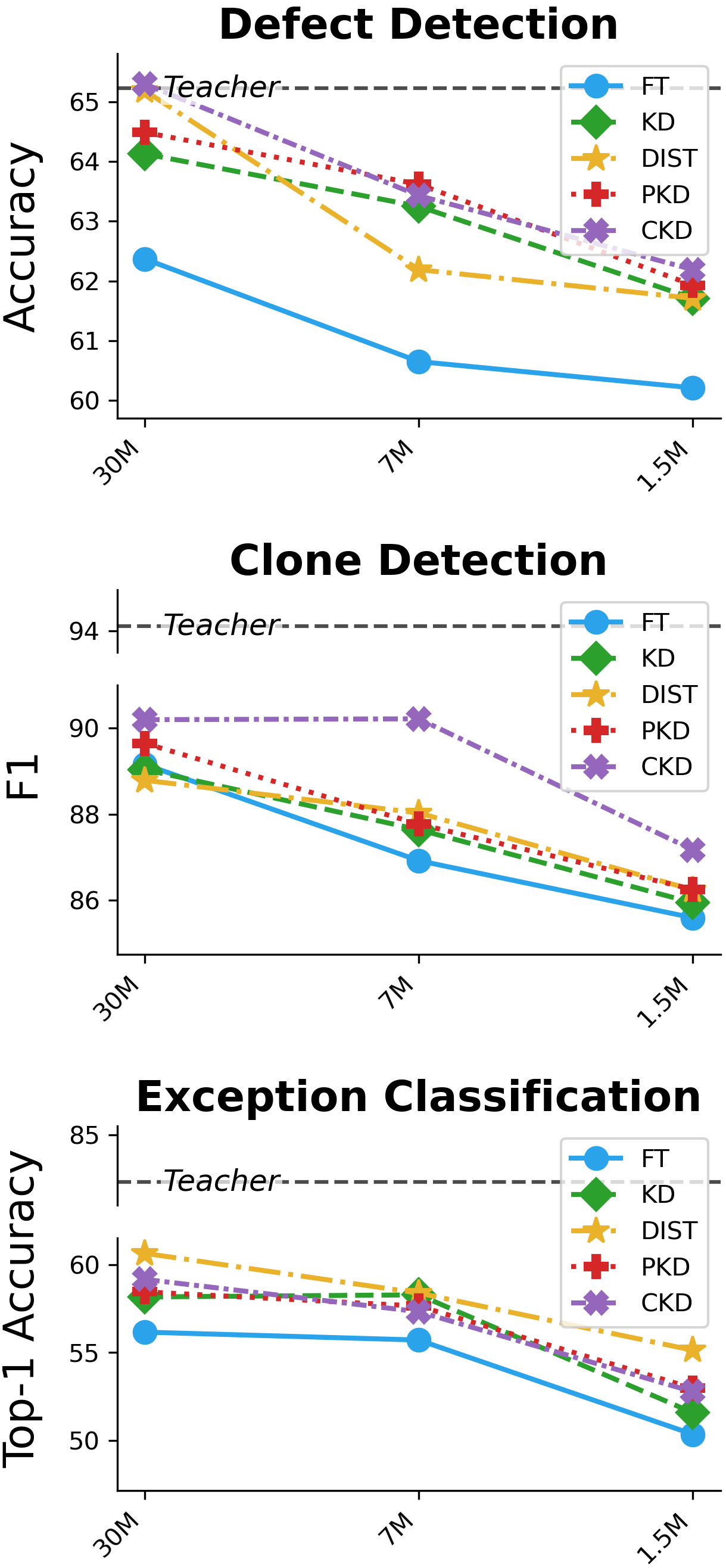
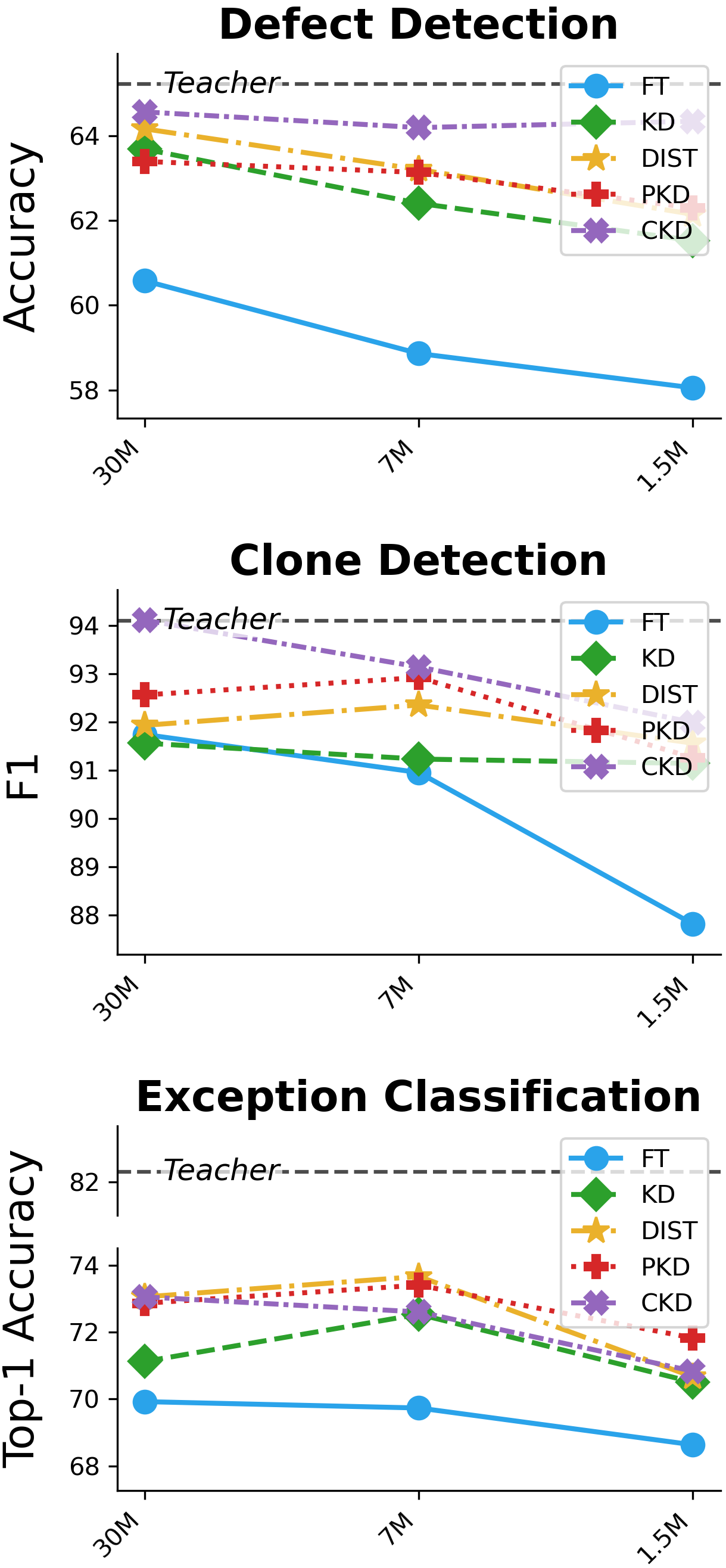
- 实验表明,知识蒸馏能显著提升学生模型的性能,基于特征的蒸馏方法效果最佳,代码特定PLM更适合作为教师模型。
📝 摘要(中文)
预训练语言模型(PLMs)已成为强大的代码理解工具。然而,由于其计算强度和推理延迟,在大型应用中部署这些PLM面临实际挑战。知识蒸馏(KD)是一种有前途的模型压缩和加速技术,通过将知识从大型教师模型转移到紧凑的学生模型来解决这些限制,从而在保留教师模型大部分能力的同时实现高效推理。虽然这项技术在自然语言处理和计算机视觉领域取得了显著成功,但其在代码理解任务中的潜力仍未得到充分探索。本文系统地研究了KD在代码理解任务中的有效性和使用方法。我们的研究包括两种流行的KD方法,即基于logits和基于特征的KD方法,在三个下游任务上对来自不同领域的八个学生模型和两个教师PLM进行了实验。实验结果表明,与标准微调相比,KD始终为不同规模的学生模型提供了显著的性能提升。值得注意的是,特定于代码的PLM作为教师模型表现出更好的效果。在所有KD方法中,最新的基于特征的KD方法表现出卓越的性能,使学生模型仅用5%的参数就能保留高达98%的教师性能。关于学生架构,我们的实验表明,与教师架构的相似性不一定会带来更好的性能。我们进一步讨论了KD过程和推理中的效率和行为,总结了研究结果的意义,并确定了有希望的未来方向。
🔬 方法详解
问题定义:论文旨在解决预训练语言模型(PLMs)在代码理解任务中部署时面临的计算资源消耗大和推理延迟高的问题。现有方法直接使用大型PLMs进行微调,虽然效果好,但难以在资源受限的环境中应用。知识蒸馏作为一种模型压缩技术,可以有效减小模型体积,提高推理速度,但其在代码理解任务中的应用潜力尚未充分挖掘。
核心思路:论文的核心思路是利用知识蒸馏技术,将大型、性能优异的教师模型的知识迁移到小型、轻量级的学生模型中。通过这种方式,学生模型可以在保持较高性能的同时,显著降低计算资源需求和推理延迟,从而实现PLMs在代码理解任务中的高效部署。论文重点研究不同类型的知识蒸馏方法,以及不同架构的学生模型和教师模型对蒸馏效果的影响。
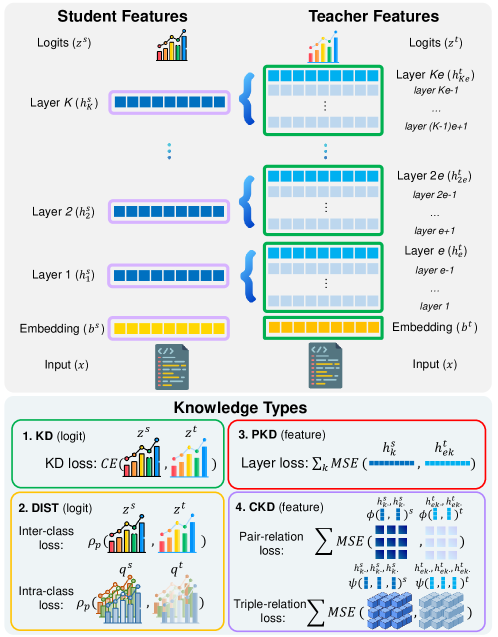
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择合适的教师模型和学生模型;2) 采用不同的知识蒸馏方法(包括基于logits和基于特征的方法)训练学生模型;3) 在多个代码理解下游任务上评估学生模型的性能;4) 分析蒸馏过程中的效率和行为,并探讨不同因素对蒸馏效果的影响。
关键创新:论文的关键创新在于系统性地研究了知识蒸馏在代码理解任务中的应用。具体包括:1) 探索了不同类型的知识蒸馏方法在代码理解任务中的有效性;2) 比较了不同架构的学生模型和教师模型对蒸馏效果的影响;3) 分析了蒸馏过程中的效率和行为,为知识蒸馏在代码理解任务中的应用提供了指导。
关键设计:论文实验中使用了两种类型的知识蒸馏方法:基于logits的蒸馏和基于特征的蒸馏。基于logits的蒸馏通过最小化学生模型和教师模型输出logits之间的差异来传递知识。基于特征的蒸馏则通过最小化学生模型和教师模型中间层特征之间的差异来传递知识。论文还探索了不同的损失函数,例如KL散度损失和均方误差损失,以及不同的学生模型架构,例如Transformer和LSTM。
🖼️ 关键图片
📊 实验亮点
实验结果表明,知识蒸馏能够显著提升学生模型在代码理解任务中的性能。例如,使用基于特征的知识蒸馏方法,学生模型仅用5%的参数就能保留高达98%的教师模型性能。此外,代码特定PLM作为教师模型表现出更好的效果。这些结果表明,知识蒸馏是提高代码理解模型效率的有效途径。
🎯 应用场景
该研究成果可应用于代码搜索、代码补全、代码缺陷检测等多个领域。通过知识蒸馏,可以将大型代码理解模型压缩成小型模型,部署在移动设备或嵌入式系统中,实现高效的代码智能服务。此外,该研究还可以为开发更有效的代码理解模型提供指导,推动代码智能技术的发展。
📄 摘要(原文)
Pre-trained language models (PLMs) have emerged as powerful tools for code understanding. However, deploying these PLMs in large-scale applications faces practical challenges due to their computational intensity and inference latency. Knowledge distillation (KD), a promising model compression and acceleration technique, addresses these limitations by transferring knowledge from large teacher models to compact student models, enabling efficient inference while preserving most of the teacher models' capabilities. While this technique has shown remarkable success in natural language processing and computer vision domains, its potential for code understanding tasks remains largely underexplored. In this paper, we systematically investigate the effectiveness and usage of KD in code understanding tasks. Our study encompasses two popular types of KD methods, i.e., logit-based and feature-based KD methods, experimenting across eight student models and two teacher PLMs from different domains on three downstream tasks. The experimental results indicate that KD consistently offers notable performance boosts across student models with different sizes compared with standard fine-tuning. Notably, code-specific PLM demonstrates better effectiveness as the teacher model. Among all KD methods, the latest feature-based KD methods exhibit superior performance, enabling student models to retain up to 98% teacher performance with merely 5% parameters. Regarding student architecture, our experiments reveal that similarity with teacher architecture does not necessarily lead to better performance. We further discuss the efficiency and behaviors in the KD process and inference, summarize the implications of findings, and identify promising future directions.