PuzzleClone: An SMT-Powered Framework for Synthesizing Verifiable Data
作者: Kai Xiong, Yanwei Huang, Rongjunchen Zhang, Kun Chen, Haipang Wu
分类: cs.AI
发布日期: 2025-08-21 (更新: 2025-08-25)
🔗 代码/项目: GITHUB
💡 一句话要点
PuzzleClone:一个基于SMT的框架,用于合成可验证的数据,提升LLM推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据合成 可满足性模理论 逻辑推理 数学推理 大型语言模型 数据增强 程序验证
📋 核心要点
- 现有LLM生成的数据集在可靠性、多样性和可扩展性方面存在局限性,难以有效提升LLM的推理能力。
- PuzzleClone框架通过SMT将谜题编码为逻辑规范,并随机化变量和约束生成可验证的变体,实现大规模数据合成。
- 实验表明,在PuzzleClone数据集上进行后训练,显著提升了LLM在逻辑和数学基准上的性能,最高提升12.5%。
📝 摘要(中文)
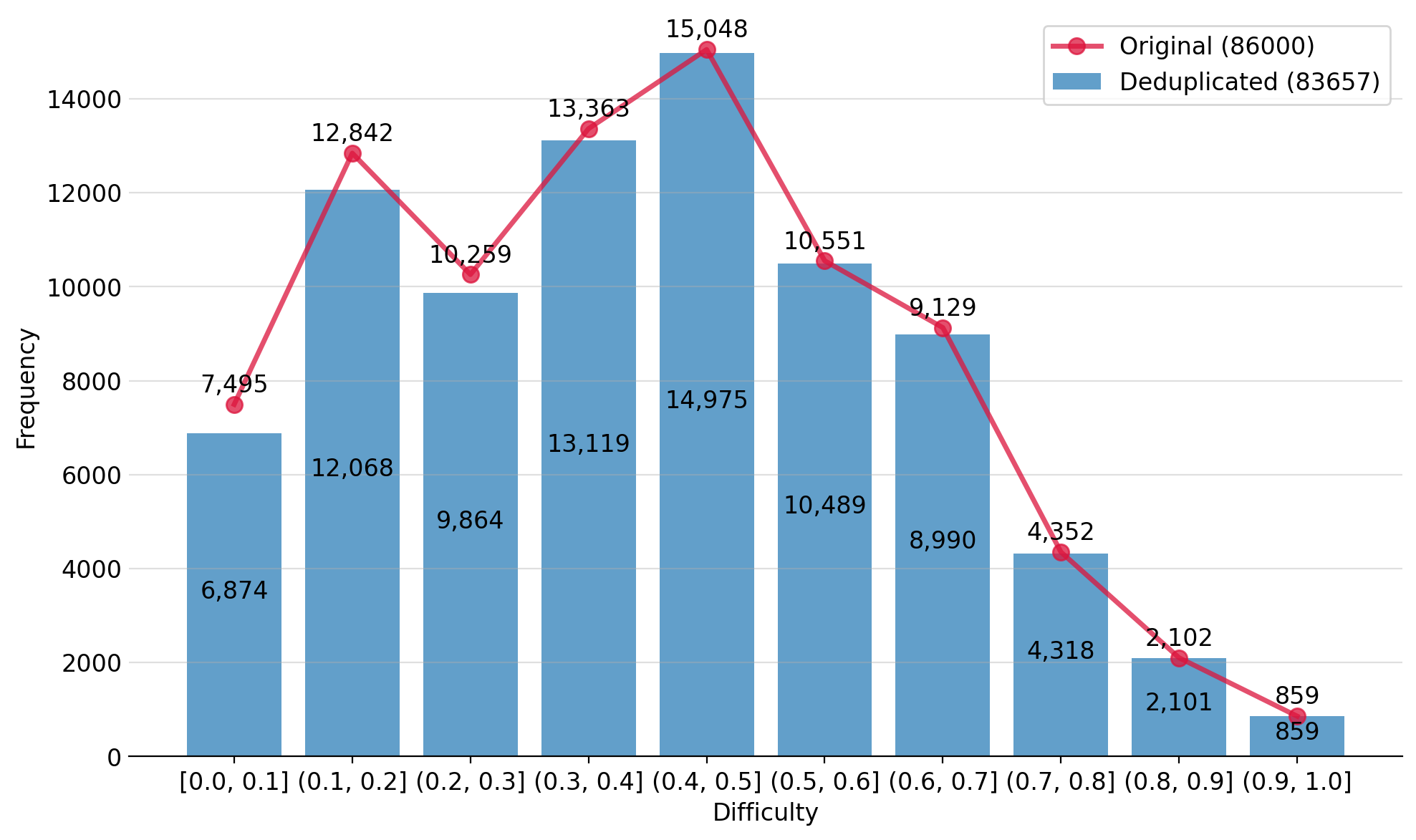
高质量且具有可验证答案的数学和逻辑数据集对于增强大型语言模型(LLM)的推理能力至关重要。尽管最近的数据增强技术促进了大规模基准的创建,但现有的LLM生成的数据集通常存在可靠性、多样性和可扩展性有限的问题。为了应对这些挑战,我们引入了PuzzleClone,这是一个正式的框架,用于使用可满足性模理论(SMT)大规模合成可验证的数据。我们的方法具有三个关键创新:(1) 将种子谜题编码为结构化的逻辑规范,(2) 通过系统的变量和约束随机化生成可扩展的变体,以及 (3) 通过重现机制确保有效性。应用PuzzleClone,我们构建了一个包含超过83K个多样化且经过程序验证的谜题的精选基准。生成的谜题涵盖了广泛的难度和格式,对当前最先进的模型提出了重大挑战。我们在PuzzleClone数据集上进行后训练(SFT和RL)。实验结果表明,在PuzzleClone上进行训练不仅在PuzzleClone测试集上产生了显著的改进,而且在逻辑和数学基准上也产生了显著的改进。后训练将PuzzleClone的平均准确率从14.4提高到56.2,并在7个逻辑和数学基准上实现了高达12.5个绝对百分点的持续改进(AMC2023从52.5提高到65.0)。我们的代码和数据可在https://github.com/HiThink-Research/PuzzleClone 获取。
🔬 方法详解
问题定义:论文旨在解决现有LLM生成数据集在数学和逻辑推理任务中存在的可靠性、多样性和可扩展性不足的问题。现有方法难以生成大量高质量、可验证的推理数据,限制了LLM推理能力的提升。
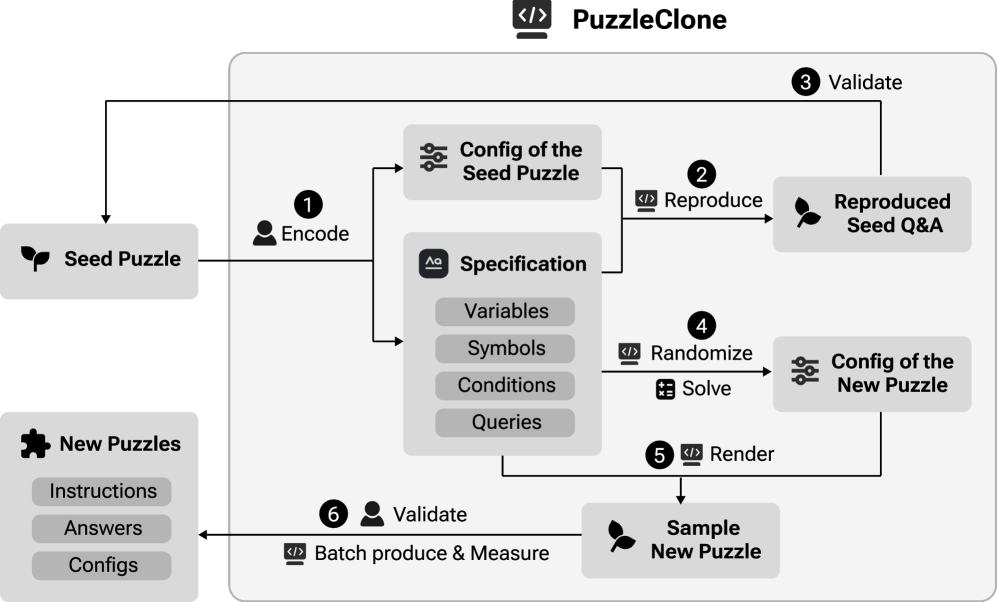
核心思路:论文的核心思路是利用可满足性模理论(SMT)将谜题形式化为逻辑规范,然后通过系统性的变量和约束随机化,生成大量语义一致但形式多样的谜题变体。通过SMT求解器验证生成谜题的有效性,确保数据的可靠性。
技术框架:PuzzleClone框架包含三个主要阶段:1) 种子谜题编码:将人工设计的或现有的谜题转化为结构化的逻辑规范,使用SMT语言进行表达。2) 变体生成:通过随机化变量、约束和关系,生成与种子谜题语义相关的变体。随机化过程需要保证生成的变体在逻辑上仍然是有效的。3) 验证:使用SMT求解器验证生成的变体是否满足逻辑规范,确保答案的正确性和一致性。
关键创新:最重要的技术创新在于利用SMT进行数据合成和验证。与传统的基于规则或模板的数据增强方法相比,PuzzleClone能够生成更复杂、多样且可验证的数据。通过形式化的逻辑规范,可以精确控制生成数据的语义,并使用SMT求解器自动验证数据的有效性,避免了人工标注的成本和误差。
关键设计:在变体生成阶段,论文设计了多种随机化策略,包括变量替换、约束添加/删除、关系修改等。为了保证生成变体的有效性,论文采用了一种重现机制,即首先生成一个可能的解,然后根据这个解反向推导出相应的约束条件。此外,论文还设计了一套难度评估指标,用于筛选和过滤掉过于简单或过于复杂的谜题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在PuzzleClone数据集上进行后训练(SFT和RL)后,LLM在PuzzleClone测试集上的平均准确率从14.4%显著提升至56.2%。同时,在7个逻辑和数学基准测试中,也取得了显著的性能提升,例如在AMC2023数据集上,准确率从52.5%提升至65.0%,提升幅度高达12.5%。
🎯 应用场景
PuzzleClone框架可应用于各种需要逻辑推理和数学计算的AI应用,例如智能教育、自动定理证明、程序验证等。该框架能够生成大量高质量的训练数据,提升模型在复杂推理任务中的性能,并降低人工标注的成本。未来,该技术有望扩展到其他领域,例如自然语言理解和知识图谱推理。
📄 摘要(原文)
High-quality mathematical and logical datasets with verifiable answers are essential for strengthening the reasoning capabilities of large language models (LLMs). While recent data augmentation techniques have facilitated the creation of large-scale benchmarks, existing LLM-generated datasets often suffer from limited reliability, diversity, and scalability. To address these challenges, we introduce PuzzleClone, a formal framework for synthesizing verifiable data at scale using Satisfiability Modulo Theories (SMT). Our approach features three key innovations: (1) encoding seed puzzles into structured logical specifications, (2) generating scalable variants through systematic variable and constraint randomization, and (3) ensuring validity via a reproduction mechanism. Applying PuzzleClone, we construct a curated benchmark comprising over 83K diverse and programmatically validated puzzles. The generated puzzles span a wide spectrum of difficulty and formats, posing significant challenges to current state-of-the-art models. We conduct post training (SFT and RL) on PuzzleClone datasets. Experimental results show that training on PuzzleClone yields substantial improvements not only on PuzzleClone testset but also on logic and mathematical benchmarks. Post training raises PuzzleClone average from 14.4 to 56.2 and delivers consistent improvements across 7 logic and mathematical benchmarks up to 12.5 absolute percentage points (AMC2023 from 52.5 to 65.0). Our code and data are available at https://github.com/HiThink-Research/PuzzleClone.