Modeling Human Responses to Multimodal AI Content
作者: Zhiqi Shen, Shaojing Fan, Danni Xu, Terence Sim, Mohan Kankanhalli
分类: cs.AI, cs.MM
发布日期: 2025-08-14
💡 一句话要点
提出MhAIM数据集与T-Lens系统,用于建模人类对多模态AI生成内容的反应,提升LLM的人类感知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态内容理解 AI生成内容 人类行为建模 LLM 人机交互 虚假信息检测 MhAIM数据集
📋 核心要点
- 现有方法侧重于识别AI生成内容的真伪,忽略了内容对人类感知和行为的影响,尤其是在需要预测用户反应的场景下。
- 论文提出MhAIM数据集,包含大量AI生成的多模态内容,并设计T-Lens系统,通过预测人类反应来增强LLM的交互能力。
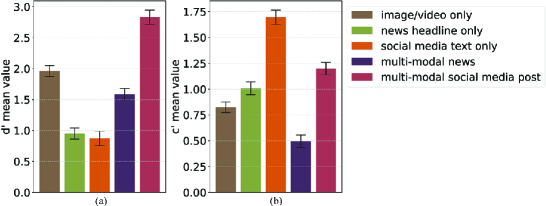
- 通过人工研究,发现多模态内容(文本+视觉)能帮助人们更好识别AI生成内容,并提出了可信度、影响力和开放性三个新指标。
📝 摘要(中文)
随着AI生成内容日益普及,虚假信息的风险也随之增加。现有研究主要集中于识别内容的真伪,而对这类内容如何影响人类感知和行为的研究较少。在交易或股票市场等领域,预测人们的反应(例如,新闻帖子是否会走红)可能比验证其事实准确性更为重要。为了解决这个问题,我们采取以人为本的方法,并引入了MhAIM数据集,其中包含154,552个在线帖子(其中111,153个是AI生成的),从而能够大规模分析人们对AI生成内容的反应。我们的人工研究表明,当帖子包含文本和视觉效果时,人们能更好地识别AI内容,尤其是在两者之间存在不一致的情况下。我们提出了三个新的指标:可信度、影响力和开放性,以量化用户如何判断和参与在线内容。我们提出了T-Lens,一个基于LLM的代理系统,旨在通过整合预测的人类对多模态信息的反应来回答用户查询。其核心是HR-MCP(人类反应模型上下文协议),建立在标准化的模型上下文协议(MCP)之上,从而可以与任何LLM无缝集成。这种集成使T-Lens能够更好地与人类反应保持一致,从而增强了可解释性和交互能力。我们的工作提供了经验性的见解和实用的工具,使LLM具备人类感知能力。通过强调AI、人类认知和信息接收之间复杂的相互作用,我们的发现为减轻AI驱动的虚假信息的风险提出了可操作的策略。
🔬 方法详解
问题定义:现有方法主要关注AI生成内容的检测,而忽略了理解和建模人类对这些内容的反应。在实际应用中,例如金融市场,预测用户对新闻的反应比验证新闻真伪更重要。现有方法缺乏对人类反应的建模能力,无法有效应对AI生成内容带来的挑战。
核心思路:论文的核心思路是以人为本,通过构建包含大量AI生成内容的数据集,并进行人工研究,来理解人类对不同类型AI生成内容的反应。然后,利用这些知识来改进LLM,使其能够更好地理解和预测人类行为。
技术框架:论文提出了一个名为T-Lens的系统,该系统基于LLM,并集成了HR-MCP(Human Response Model Context Protocol)。HR-MCP建立在标准化的MCP之上,允许T-Lens与任何LLM无缝集成。T-Lens通过预测人类对多模态信息的反应来回答用户查询。整体流程包括数据收集、人工标注、模型训练和系统部署。
关键创新:论文的关键创新在于:1) 构建了大规模的MhAIM数据集,包含大量AI生成的多模态内容;2) 提出了HR-MCP协议,允许LLM更好地理解和预测人类反应;3) 设计了T-Lens系统,将人类反应建模能力集成到LLM中。
关键设计:HR-MCP协议的设计允许LLM访问关于人类反应的上下文信息。论文提出了三个新的指标:可信度、影响力和开放性,用于量化用户对在线内容的判断和参与度。这些指标被用于训练模型,以预测人类对不同类型AI生成内容的反应。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
人工研究表明,当帖子包含文本和视觉效果时,人们能更好地识别AI内容。论文提出了可信度、影响力和开放性三个新指标,并构建了MhAIM数据集,包含154,552个在线帖子,为后续研究提供了数据基础。T-Lens系统通过集成HR-MCP协议,能够更好地与人类反应保持一致,增强了可解释性和交互能力。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于多个领域,例如:金融市场舆情分析、社交媒体内容审核、虚假信息检测与溯源、智能客服与对话系统。通过理解和预测人类对AI生成内容的反应,可以有效降低虚假信息传播的风险,提升人机交互的效率和质量,并为AI伦理研究提供数据支撑。
📄 摘要(原文)
As AI-generated content becomes widespread, so does the risk of misinformation. While prior research has primarily focused on identifying whether content is authentic, much less is known about how such content influences human perception and behavior. In domains like trading or the stock market, predicting how people react (e.g., whether a news post will go viral), can be more critical than verifying its factual accuracy. To address this, we take a human-centered approach and introduce the MhAIM Dataset, which contains 154,552 online posts (111,153 of them AI-generated), enabling large-scale analysis of how people respond to AI-generated content. Our human study reveals that people are better at identifying AI content when posts include both text and visuals, particularly when inconsistencies exist between the two. We propose three new metrics: trustworthiness, impact, and openness, to quantify how users judge and engage with online content. We present T-Lens, an LLM-based agent system designed to answer user queries by incorporating predicted human responses to multimodal information. At its core is HR-MCP (Human Response Model Context Protocol), built on the standardized Model Context Protocol (MCP), enabling seamless integration with any LLM. This integration allows T-Lens to better align with human reactions, enhancing both interpretability and interaction capabilities. Our work provides empirical insights and practical tools to equip LLMs with human-awareness capabilities. By highlighting the complex interplay among AI, human cognition, and information reception, our findings suggest actionable strategies for mitigating the risks of AI-driven misinformation.