Is On-Policy Data always the Best Choice for Direct Preference Optimization-based LM Alignment?
作者: Zetian Sun, Dongfang Li, Xuhui Chen, Baotian Hu, Min Zhang
分类: cs.AI, cs.CL
发布日期: 2025-08-14 (更新: 2026-01-27)
备注: Accepted by ICLR-2026
💡 一句话要点
揭示DPO中On-Policy数据并非总是最优,提出对齐阶段假设并优化数据选择
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 直接偏好优化 On-Policy学习 静态数据 对齐阶段假设
📋 核心要点
- 现有基于DPO的语言模型对齐方法依赖于静态或on-policy数据,但未充分理解其有效性差异。
- 论文提出“对齐阶段假设”,将对齐过程分为偏好注入和偏好微调两个阶段,并据此选择合适数据。
- 实验证明,on-policy数据并非总是最优,且提出的边界测量算法能有效识别对齐阶段,提升模型性能。
📝 摘要(中文)
将语言模型(LM)与人类偏好对齐对于构建可靠的AI系统至关重要。通常,这个问题被定义为优化LM策略,以最大化反映人类偏好的预期奖励。最近,直接偏好优化(DPO)被提出作为一种LM对齐方法,它直接从静态偏好数据中优化策略,并通过结合on-policy采样(即在训练循环中生成的偏好候选)来进一步改进,以实现更好的LM对齐。然而,我们表明on-policy数据并不总是最优的,静态和on-policy偏好候选之间存在系统的有效性差异。例如,对于Llama-3,on-policy数据可能导致3倍的有效性,而对于Zephyr,则为0.4倍。为了解释这种现象,我们提出了对齐阶段假设,该假设将对齐过程分为两个不同的阶段:偏好注入阶段,该阶段受益于多样化的数据,以及偏好微调阶段,该阶段偏爱高质量的数据。通过理论和实证分析,我们描述了这些阶段,并提出了一种有效的算法来识别它们之间的边界。我们在5个模型(Llama、Zephyr、Phi-2、Qwen、Pythia)和2个对齐方法(DPO、SLiC-HF)上进行了实验,以展示对齐阶段假设的通用性和边界测量算法的有效性。
🔬 方法详解
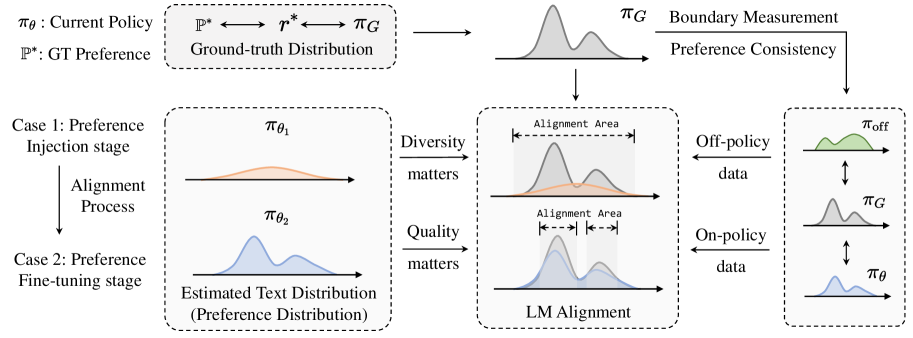
问题定义:现有基于DPO的语言模型对齐方法,在选择训练数据时,通常要么使用静态数据集,要么使用on-policy生成的数据。然而,论文指出,on-policy数据并非总是最优选择,不同模型在不同阶段可能对不同类型的数据有不同的偏好。现有方法缺乏对数据选择的细致分析,导致模型对齐效果不稳定。
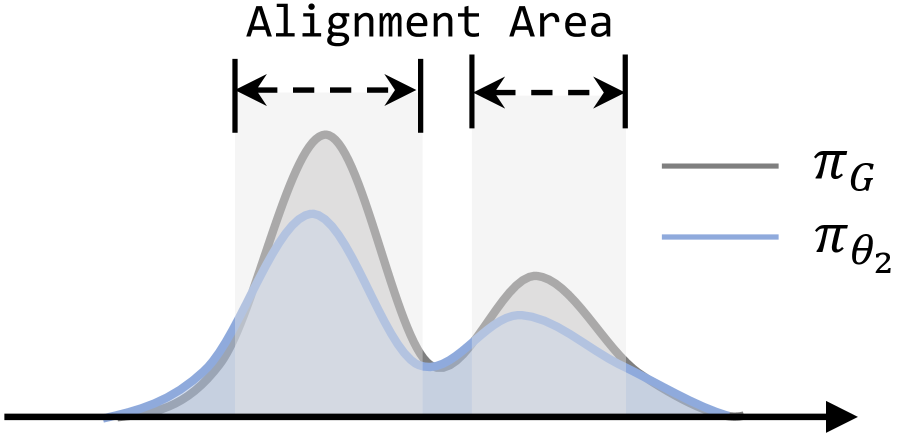
核心思路:论文的核心思路是提出“对齐阶段假设”,认为语言模型对齐过程可以分为两个阶段:偏好注入阶段和偏好微调阶段。偏好注入阶段需要多样化的数据来快速学习人类偏好,而偏好微调阶段则需要高质量的数据来精细调整模型。基于此假设,论文提出了一种边界测量算法,用于识别这两个阶段之间的转换点,从而动态选择合适的训练数据。
技术框架:论文的技术框架主要包括三个部分:1)对齐阶段假设的提出,明确了对齐过程的两个阶段及其特点;2)边界测量算法的设计,用于自动识别两个阶段之间的转换点;3)基于边界测量算法的数据选择策略,根据当前阶段选择静态或on-policy数据进行训练。整体流程是先进行初步的对齐训练,然后使用边界测量算法评估当前阶段,最后根据阶段选择合适的数据进行后续训练。
关键创新:论文最重要的技术创新点在于提出了“对齐阶段假设”,并设计了相应的边界测量算法。该假设打破了以往认为on-policy数据总是优于静态数据的固有观念,为语言模型对齐的数据选择提供了新的视角。边界测量算法能够自动识别对齐阶段,从而实现动态数据选择,提高了模型对齐的效率和效果。
关键设计:边界测量算法的具体设计细节未知,摘要中没有明确说明。但是,可以推测该算法可能基于模型在静态数据和on-policy数据上的性能差异来判断当前所处的阶段。例如,如果模型在on-policy数据上的性能提升明显高于静态数据,则可能处于偏好注入阶段;反之,如果模型在静态数据上的性能提升更高,则可能处于偏好微调阶段。具体的损失函数、网络结构等技术细节在摘要中未提及,需要查阅论文全文才能了解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,on-policy数据并非总是最优,不同模型在不同阶段对数据的偏好不同。例如,对于Llama-3,on-policy数据可能导致3倍的有效性,而对于Zephyr,则为0.4倍。论文提出的边界测量算法能够有效识别对齐阶段,并根据阶段选择合适的数据进行训练,从而提高模型性能。实验在5个模型(Llama、Zephyr、Phi-2、Qwen、Pythia)和2个对齐方法(DPO、SLiC-HF)上验证了该方法的通用性。
🎯 应用场景
该研究成果可应用于各种需要与人类偏好对齐的语言模型训练场景,例如对话系统、文本生成、代码生成等。通过动态选择合适的训练数据,可以提高模型的对齐效率和效果,从而构建更安全、可靠和符合人类价值观的AI系统。该研究还有助于更好地理解语言模型对齐过程,为未来的研究提供新的思路。
📄 摘要(原文)
The alignment of language models~(LMs) with human preferences is critical for building reliable AI systems. The problem is typically framed as optimizing an LM policy to maximize the expected reward that reflects human preferences. Recently, Direct Preference Optimization~(DPO) was proposed as a LM alignment method that directly optimize the policy from static preference data, and further improved by incorporating on-policy sampling~(i.e., preference candidates generated during the training loop) for better LM alignment. However, we show on-policy data is not always optimal, with systematic effectiveness difference emerging between static and on-policy preference candidates. For example, on-policy data can result in a $3\times$ effectiveness compared with static data for Llama-3, and a $0.4\times$ effectiveness for Zephyr. To explain the phenomenon, we propose the alignment stage assumption, which divides the alignment process into two distinct stages: the preference injection stage, which benefits from diverse data, and the preference fine-tuning stage, which favors high-quality data. Through theoretical and empirical analysis, we characterize these stages and propose an effective algorithm to identify the boundaries between them. We perform experiments on $5$ models~(Llama, Zephyr, Phi-2, Qwen, Pythia) and $2$ alignment methods~(DPO, SLiC-HF) to show the generalizability of alignment stage assumption and the effectiveness of the boundary measurement algorithm.