We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
作者: Runqi Qiao, Qiuna Tan, Peiqing Yang, Yanzi Wang, Xiaowan Wang, Enhui Wan, Sitong Zhou, Guanting Dong, Yuchen Zeng, Yida Xu, Jie Wang, Chong Sun, Chen Li, Honggang Zhang
分类: cs.AI, cs.CV, cs.LG
发布日期: 2025-08-14
备注: Working in progress
💡 一句话要点
提出We-Math 2.0,通过知识驱动和模型中心的数据建模,提升多模态大语言模型在数学推理上的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 数学推理 知识图谱 强化学习 数据集构建
📋 核心要点
- 现有MLLM在数学推理方面存在不足,主要原因是缺乏全面的知识驱动设计和模型中心的数据空间建模。
- We-Math 2.0通过构建结构化知识系统、模型中心的数据集和强化学习训练范式,全面提升MLLM的数学推理能力。
- 实验结果表明,We-Math 2.0在多个基准测试中表现出色,尤其是在新提出的MathBookEval上,验证了其泛化能力。
📝 摘要(中文)
多模态大语言模型(MLLMs)在各种任务中表现出令人印象深刻的能力,但仍然难以进行复杂的数学推理。现有的研究主要集中在数据集构建和方法优化上,往往忽略了两个关键方面:全面的知识驱动设计和以模型为中心的数据空间建模。本文介绍了We-Math 2.0,一个统一的系统,它整合了一个结构化的数学知识系统、以模型为中心的数据空间建模和一个基于强化学习(RL)的训练范式,以全面提高MLLMs的数学推理能力。We-Math 2.0的主要贡献有四个方面:(1) MathBook知识系统:我们构建了一个五级层次系统,包含491个知识点和1,819个基本原理。(2) MathBook-Standard & Pro:我们开发了MathBook-Standard,该数据集通过双重扩展确保了广泛的概念覆盖和灵活性。此外,我们定义了一个三维难度空间,并为每个问题生成7个渐进变体,以构建MathBook-Pro,这是一个用于鲁棒训练的具有挑战性的数据集。(3) MathBook-RL:我们提出了一个两阶段RL框架,包括:(i)冷启动微调,使模型与面向知识的思维链推理对齐;(ii)渐进对齐RL,利用平均奖励学习和动态数据调度来实现跨难度级别的渐进对齐。(4) MathBookEval:我们引入了一个全面的基准,涵盖所有491个知识点,具有不同的推理步骤分布。实验结果表明,MathBook-RL在四个广泛使用的基准测试中表现出与现有基线相当的竞争力,并在MathBookEval上取得了优异的成绩,表明其在数学推理方面具有良好的泛化能力。
🔬 方法详解
问题定义:现有的多模态大语言模型在解决复杂数学问题时,推理能力不足。主要痛点在于缺乏结构化的数学知识体系支撑,以及难以针对模型特性构建有效的数据集,导致模型难以进行有效的学习和泛化。
核心思路:We-Math 2.0的核心思路是构建一个全面的、结构化的数学知识系统,并基于此设计模型中心的数据集,最后利用强化学习方法进行训练,从而提升模型的数学推理能力。通过知识驱动和数据驱动相结合的方式,弥补现有方法的不足。
技术框架:We-Math 2.0包含三个主要组成部分:MathBook知识系统、MathBook数据集(Standard & Pro)和MathBook-RL训练框架。MathBook知识系统提供结构化的数学知识;MathBook数据集提供不同难度级别的数据,用于模型的训练和评估;MathBook-RL训练框架利用强化学习方法,使模型能够更好地利用知识进行推理。
关键创新:该论文的关键创新在于提出了一个完整的、统一的系统,将知识系统、数据集构建和训练方法有机结合起来。特别是,提出了以模型为中心的数据空间建模方法,能够根据模型的特点生成更有效的数据。此外,两阶段的强化学习训练框架也能够更好地引导模型学习。
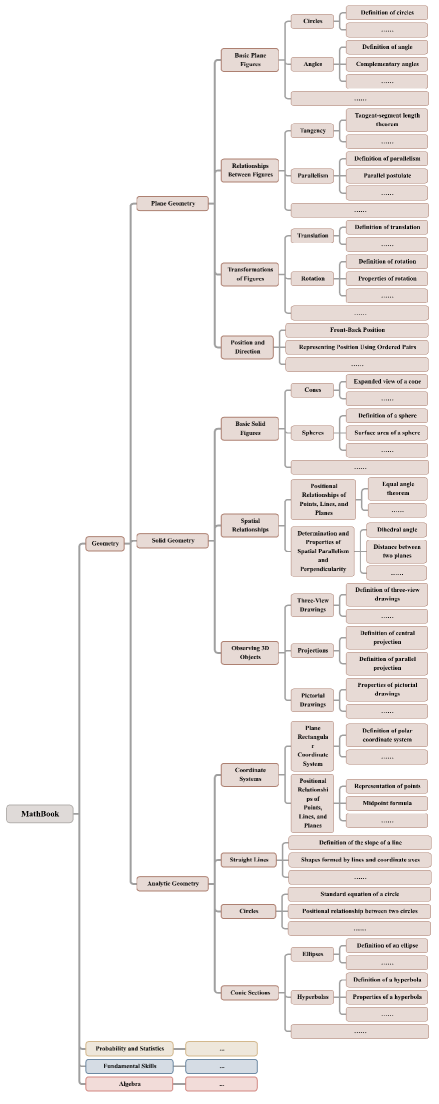
关键设计:MathBook知识系统采用五级层次结构,包含491个知识点和1819个基本原理。MathBook-Pro数据集定义了一个三维难度空间,并为每个问题生成7个渐进变体。MathBook-RL训练框架包含冷启动微调和渐进对齐RL两个阶段,分别用于知识对齐和难度对齐。渐进对齐RL采用平均奖励学习和动态数据调度策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MathBook-RL在四个广泛使用的基准测试中表现出与现有基线相当的竞争力,并在MathBookEval上取得了优异的成绩。尤其是在MathBookEval上,验证了该方法在数学推理方面具有良好的泛化能力,表明其能够有效利用知识进行推理。
🎯 应用场景
We-Math 2.0可应用于教育领域,例如智能辅导系统,帮助学生理解和解决数学问题。此外,该研究也可用于开发更强大的通用人工智能系统,使其具备更强的推理能力,从而在科学研究、工程设计等领域发挥作用。未来,该系统可以扩展到其他学科,构建更通用的知识推理引擎。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.