What to Ask Next? Probing the Imaginative Reasoning of LLMs with TurtleSoup Puzzles
作者: Mengtao Zhou, Sifan Wu, Huan Zhang, Qi Sima, Bang Liu
分类: cs.AI
发布日期: 2025-08-14
💡 一句话要点
提出TurtleSoup-Bench,用于评估LLM在信息稀疏环境下的想象推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 想象推理 海龟汤游戏 基准测试 智能体
📋 核心要点
- 现有基准测试无法充分评估LLM在信息不足情况下的动态探索式想象推理能力。
- 提出基于“海龟汤”游戏的框架,包含基准、智能体和评估协议,以评估LLM的想象推理能力。
- 实验表明,LLM在想象推理方面存在局限性,与人类相比存在显著差距,为未来研究奠定基础。
📝 摘要(中文)
本文旨在评估大型语言模型(LLM)的想象推理能力,即在信息稀疏环境中主动构建、测试和修正假设的能力。现有基准测试通常是静态的或侧重于社会演绎,无法捕捉这种推理过程的动态探索性。为了解决这一差距,本文提出了一个基于经典“海龟汤”游戏的综合研究框架,集成了基准测试、智能体和评估协议。论文提出了TurtleSoup-Bench,这是第一个大规模、双语、交互式的想象推理基准测试,包含800个来自互联网和专家作者的海龟汤谜题。同时,提出了Mosaic-Agent,一种用于评估LLM在此环境中性能的新型智能体。为了评估推理质量,开发了一种多维度协议,用于衡量逻辑一致性、细节补全和结论对齐。对领先LLM的实验表明,LLM在想象推理方面存在明显的局限性、常见的失败模式,以及与人类相比存在显著的性能差距。这项工作为LLM的想象推理提供了新的见解,并为未来探索性智能体行为的研究奠定了基础。
🔬 方法详解
问题定义:论文旨在解决现有LLM评估基准在评估想象推理能力方面的不足。现有基准要么是静态的,要么侧重于社会演绎,无法捕捉到在信息稀疏环境下,LLM主动构建、测试和修正假设的动态探索过程。因此,需要一个更具挑战性和互动性的基准来评估LLM的想象推理能力。
核心思路:论文的核心思路是利用“海龟汤”游戏作为评估LLM想象推理能力的载体。“海龟汤”游戏需要玩家通过提问来逐步获取信息,从而推断出谜题的完整故事,这与想象推理的过程非常契合。通过设计一个基于“海龟汤”游戏的基准测试,可以有效地评估LLM在信息稀疏环境下的假设构建、测试和修正能力。
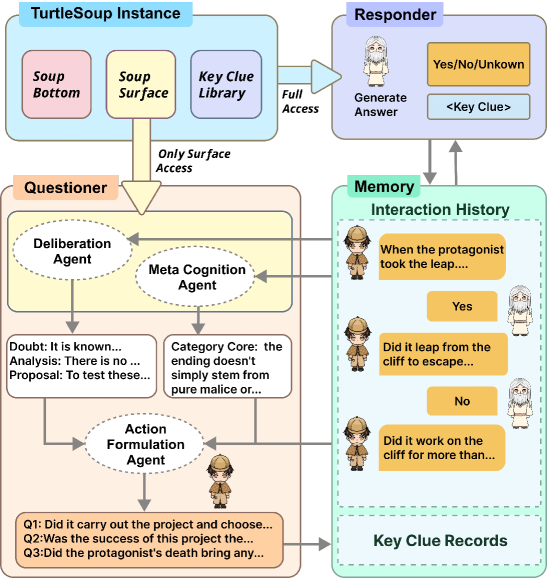
技术框架:论文提出的研究框架包含三个主要组成部分:TurtleSoup-Bench基准测试、Mosaic-Agent智能体和评估协议。TurtleSoup-Bench是一个大规模、双语、交互式的海龟汤谜题数据集,包含800个谜题。Mosaic-Agent是一个专门设计的智能体,用于与LLM进行交互,通过提问来逐步解决海龟汤谜题。评估协议则用于衡量LLM的推理质量,包括逻辑一致性、细节补全和结论对齐。
关键创新:论文的关键创新在于提出了TurtleSoup-Bench,这是第一个大规模、双语、交互式的想象推理基准测试。与现有的静态或侧重于社会演绎的基准测试不同,TurtleSoup-Bench能够更有效地评估LLM在信息稀疏环境下的动态探索式推理能力。此外,Mosaic-Agent的设计也考虑了海龟汤游戏的特点,能够更有效地与LLM进行交互,从而更好地评估其推理能力。
关键设计:TurtleSoup-Bench包含800个海龟汤谜题,涵盖多种类型和难度级别,确保了基准测试的多样性和挑战性。Mosaic-Agent的设计采用了模块化的结构,包括问题生成模块、答案解析模块和状态更新模块,使其能够有效地与LLM进行交互。评估协议则采用了多维度的指标,包括逻辑一致性、细节补全和结论对齐,从而全面评估LLM的推理质量。具体参数设置和网络结构未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,领先的LLM在TurtleSoup-Bench上的表现与人类相比存在显著差距,揭示了LLM在想象推理方面的局限性。具体性能数据未知,但实验结果清晰地展示了LLM在逻辑一致性、细节补全和结论对齐方面的不足,为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于开发更智能、更具创造力的AI系统,例如,在需要进行假设推理和问题解决的领域,如科学发现、故障诊断、以及需要与人进行复杂对话的聊天机器人等。此外,该基准测试可以促进对LLM局限性的理解,并推动未来在探索性智能体行为方面的研究。
📄 摘要(原文)
We investigate the capacity of Large Language Models (LLMs) for imaginative reasoning--the proactive construction, testing, and revision of hypotheses in information-sparse environments. Existing benchmarks, often static or focused on social deduction, fail to capture the dynamic, exploratory nature of this reasoning process. To address this gap, we introduce a comprehensive research framework based on the classic "Turtle Soup" game, integrating a benchmark, an agent, and an evaluation protocol. We present TurtleSoup-Bench, the first large-scale, bilingual, interactive benchmark for imaginative reasoning, comprising 800 turtle soup puzzles sourced from both the Internet and expert authors. We also propose Mosaic-Agent, a novel agent designed to assess LLMs' performance in this setting. To evaluate reasoning quality, we develop a multi-dimensional protocol measuring logical consistency, detail completion, and conclusion alignment. Experiments with leading LLMs reveal clear capability limits, common failure patterns, and a significant performance gap compared to humans. Our work offers new insights into LLMs' imaginative reasoning and establishes a foundation for future research on exploratory agent behavior.