A Curriculum Learning Approach to Reinforcement Learning: Leveraging RAG for Multimodal Question Answering
作者: Chenliang Zhang, Lin Wang, Yuanyuan Lu, Yusheng Qi, Kexin Wang, Peixu Hou, Wenshi Chen
分类: cs.AI, cs.LG
发布日期: 2025-08-14 (更新: 2026-01-14)
💡 一句话要点
利用课程学习强化学习,解决检索增强生成多模态问答难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态问答 检索增强生成 课程学习 强化学习 知识图谱 视觉大语言模型 知识蒸馏
📋 核心要点
- 现有方法在多模态多轮问答中,难以有效利用知识图谱、网络搜索等多种信息源,导致答案准确性不足。
- 论文提出结合课程学习的强化学习方法,逐步引导模型学习,提升模型在复杂场景下的问答能力。
- 实验结果表明,该方法在多模态问答任务中显著提升了答案准确性,尤其在任务1中取得了领先优势。
📝 摘要(中文)
本文介绍了大众点评-信任安全团队针对META CRAG-MM挑战赛的解决方案。该挑战赛要求构建一个综合的检索增强生成系统,用于多模态多轮问答。比赛包含三个任务:(1)使用从基于图像的模拟知识图谱中检索到的结构化数据回答问题;(2)综合来自知识图谱和网络搜索结果的信息;(3)处理需要上下文理解和从多个来源聚合信息的多轮对话。对于任务1,我们的解决方案基于视觉大语言模型,并通过GPT-4.1知识蒸馏的监督微调进行增强。我们进一步应用课程学习策略来指导强化学习,从而提高答案准确性并减少幻觉。对于任务2和任务3,我们还利用网络搜索API来整合外部知识,使系统能够更好地处理复杂的查询和多轮对话。我们的方法在任务1中以52.38%的显著优势获得第一名,在任务3中获得第三名,证明了课程学习与强化学习相结合的训练流程的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态多轮问答任务,该任务的难点在于如何有效地利用来自知识图谱、网络搜索等多种模态和来源的信息,并处理多轮对话中的上下文依赖关系。现有方法在处理复杂查询和多轮对话时,容易出现答案不准确甚至产生幻觉的问题。
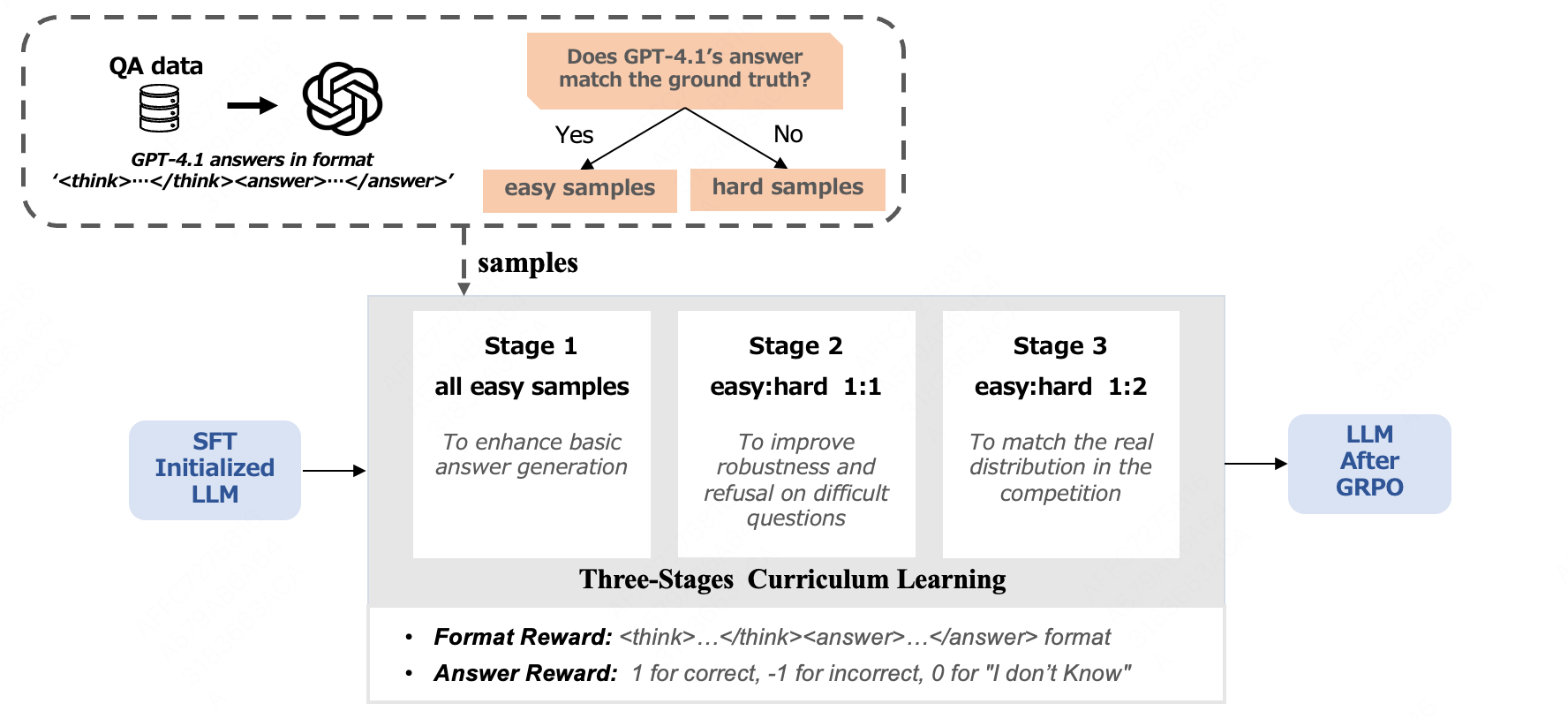
核心思路:论文的核心思路是利用课程学习的思想,设计一个由易到难的学习过程,逐步引导模型学习如何有效地检索、整合和利用各种信息源。同时,结合强化学习,通过奖励机制鼓励模型生成更准确、更符合上下文的答案。
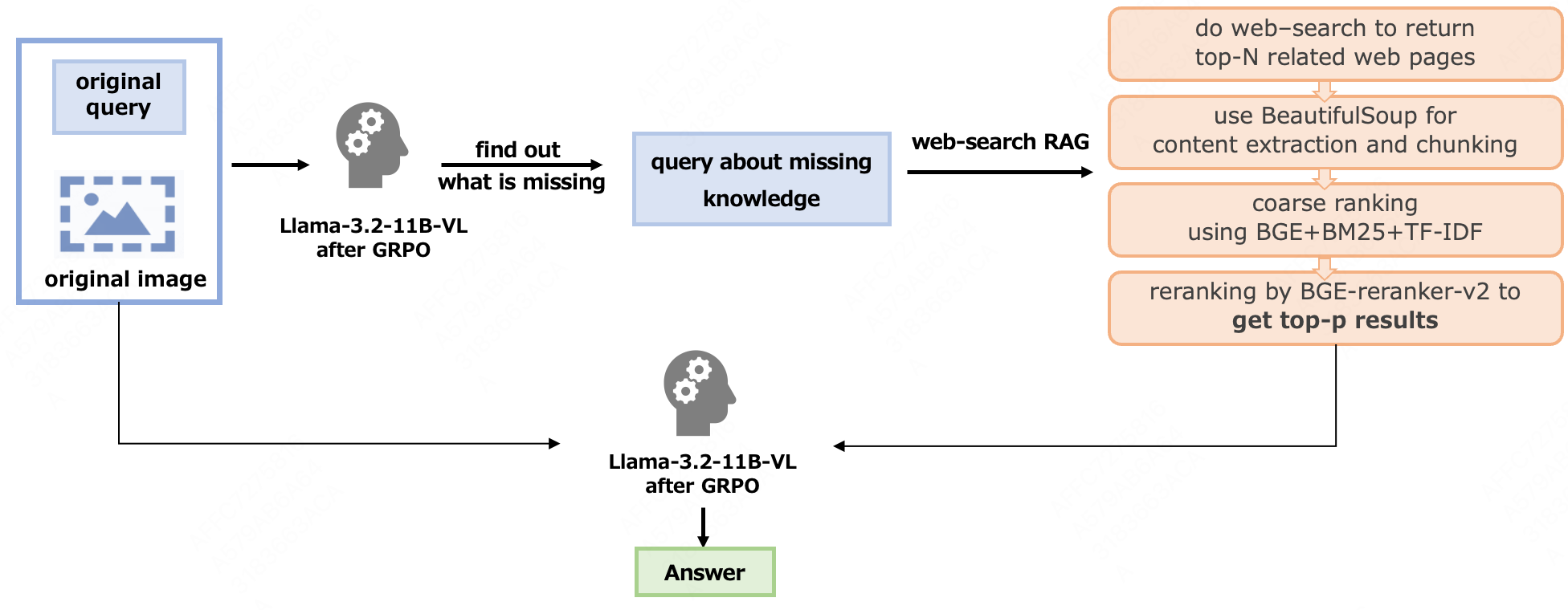
技术框架:整体框架包含以下几个主要模块:1) 视觉大语言模型:作为基础模型,用于理解图像和文本信息;2) 知识图谱检索模块:用于从图像相关的知识图谱中检索相关信息;3) 网络搜索模块:用于从互联网上获取外部知识;4) 答案生成模块:用于根据检索到的信息和上下文生成答案;5) 课程学习模块:用于设计由易到难的学习课程;6) 强化学习模块:用于通过奖励机制优化答案生成策略。
关键创新:论文的关键创新在于将课程学习与强化学习相结合,用于训练多模态问答系统。课程学习能够有效地引导模型学习,避免陷入局部最优解,而强化学习则能够通过奖励机制优化答案生成策略,提高答案的准确性和一致性。
关键设计:在课程学习方面,论文设计了一系列由易到难的任务,例如,首先让模型学习回答简单的单轮问题,然后逐步增加问题的复杂度和轮数。在强化学习方面,论文设计了一个奖励函数,用于评估答案的准确性、相关性和一致性。此外,论文还采用了知识蒸馏技术,利用GPT-4.1生成高质量的训练数据,进一步提升模型的性能。
🖼️ 关键图片
📊 实验亮点
该方法在META CRAG-MM挑战赛的任务1中取得了显著领先,以52.38%的优势获得第一名,证明了课程学习与强化学习相结合的有效性。此外,在任务3中也获得了第三名,表明该方法在处理复杂查询和多轮对话方面具有较强的竞争力。实验结果表明,该方法能够有效提高答案的准确性和一致性,并减少幻觉。
🎯 应用场景
该研究成果可应用于智能客服、教育机器人、智能助手等领域,提升多模态交互体验。例如,在电商场景中,用户可以通过图像提问商品信息,系统结合商品知识图谱和网络信息,给出准确全面的回答。未来,该技术有望在更广泛的领域实现更智能的人机交互。
📄 摘要(原文)
This paper describes the solutions of the Dianping-Trust-Safety team for the META CRAG-MM challenge. The challenge requires building a comprehensive retrieval-augmented generation system capable for multi-modal multi-turn question answering. The competition consists of three tasks: (1) answering questions using structured data retrieved from an image-based mock knowledge graph, (2) synthesizing information from both knowledge graphs and web search results, and (3) handling multi-turn conversations that require context understanding and information aggregation from multiple sources. For Task 1, our solution is based on the vision large language model, enhanced by supervised fine-tuning with knowledge distilled from GPT-4.1. We further applied curriculum learning strategies to guide reinforcement learning, resulting in improved answer accuracy and reduced hallucination. For Task 2 and Task 3, we additionally leveraged web search APIs to incorporate external knowledge, enabling the system to better handle complex queries and multi-turn conversations. Our approach achieved 1st place in Task 1 with a significant lead of 52.38%, and 3rd place in Task 3, demonstrating the effectiveness of the integration of curriculum learning with reinforcement learning in our training pipeline.