LLM-BI: Towards Fully Automated Bayesian Inference with Large Language Models
作者: Yongchao Huang
分类: cs.AI
发布日期: 2025-08-07
备注: 6 pages
💡 一句话要点
提出LLM-BI,利用大语言模型实现全自动贝叶斯推断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯推断 大型语言模型 自动化建模 概率编程 自然语言处理
📋 核心要点
- 贝叶斯推断需要专业知识来指定先验分布和似然函数,限制了其广泛应用。
- LLM-BI利用大型语言模型自动生成先验分布和似然函数,简化贝叶斯建模流程。
- 实验表明,LLM能够从自然语言描述中提取先验信息,并构建完整的贝叶斯模型。
📝 摘要(中文)
贝叶斯推断的广泛应用面临一个重要障碍,即先验分布和似然函数的设定,这通常需要专业的统计学知识。本文探讨了使用大型语言模型(LLM)来自动化这一过程的可行性。我们提出了LLM-BI(Large Language Model-driven Bayesian Inference),这是一个用于自动化贝叶斯工作流程的概念性流程。作为概念验证,我们展示了两个专注于贝叶斯线性回归的实验。在实验一中,我们证明了LLM可以成功地从自然语言中提取先验分布。在实验二中,我们表明LLM可以从单个高级问题描述中指定整个模型结构,包括先验和似然。我们的结果验证了LLM在自动化贝叶斯建模关键步骤方面的潜力,从而为概率编程的自动化推理流程提供了可能性。
🔬 方法详解
问题定义:贝叶斯推断在实际应用中面临的主要挑战是需要专家知识来定义先验分布和似然函数。这使得非专业人士难以应用贝叶斯方法解决实际问题。现有的方法依赖于人工指定这些分布,过程繁琐且容易出错。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大自然语言理解和生成能力,将自然语言描述的问题转化为贝叶斯模型的先验分布和似然函数。通过这种方式,可以降低贝叶斯建模的门槛,实现全自动的贝叶斯推断。
技术框架:LLM-BI的整体框架包含以下几个主要阶段:1) 问题描述:用户以自然语言描述待解决的问题。2) LLM模型:使用LLM将问题描述转化为先验分布和似然函数的具体形式。3) 贝叶斯推断:利用生成的先验和似然函数进行贝叶斯推断,得到后验分布。4) 结果分析:对后验分布进行分析和可视化,为用户提供决策支持。
关键创新:该方法最重要的创新点在于将大型语言模型引入贝叶斯推断流程,实现了从自然语言到贝叶斯模型的自动转换。与传统方法相比,LLM-BI无需人工干预,大大简化了建模过程,降低了对专业知识的要求。
关键设计:在实验中,使用了特定的prompt工程来指导LLM生成合适的先验分布和似然函数。例如,通过提供明确的指令和示例,引导LLM生成符合要求的概率分布。此外,还设计了评估指标来衡量LLM生成的先验分布和似然函数的质量,例如,通过比较生成的后验分布与真实后验分布的差异来评估模型的准确性。
🖼️ 关键图片
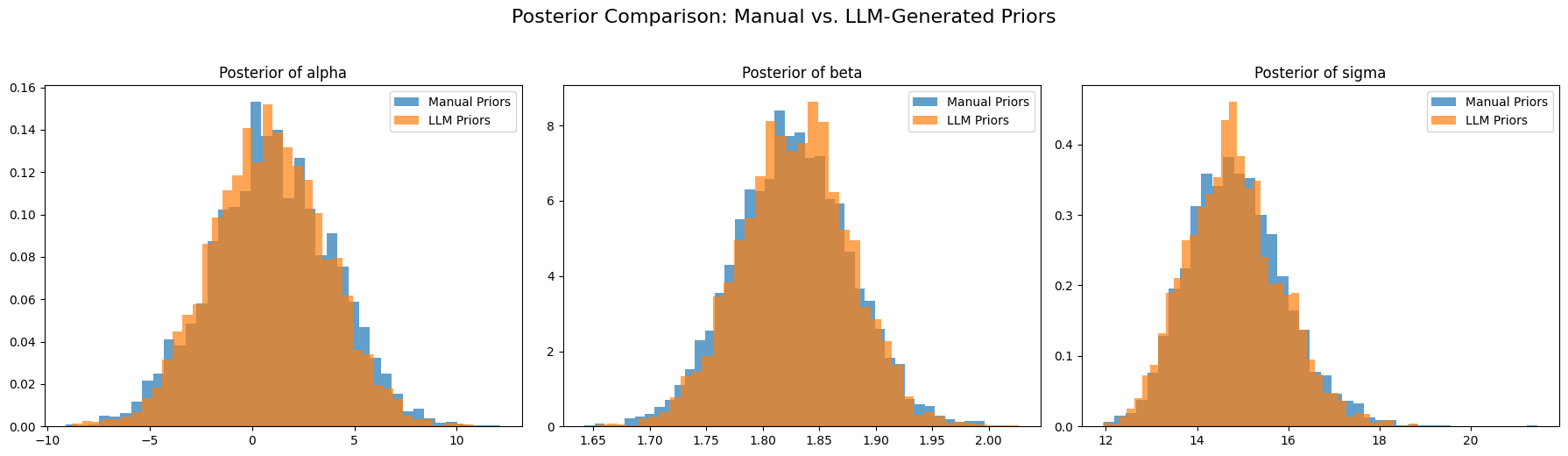
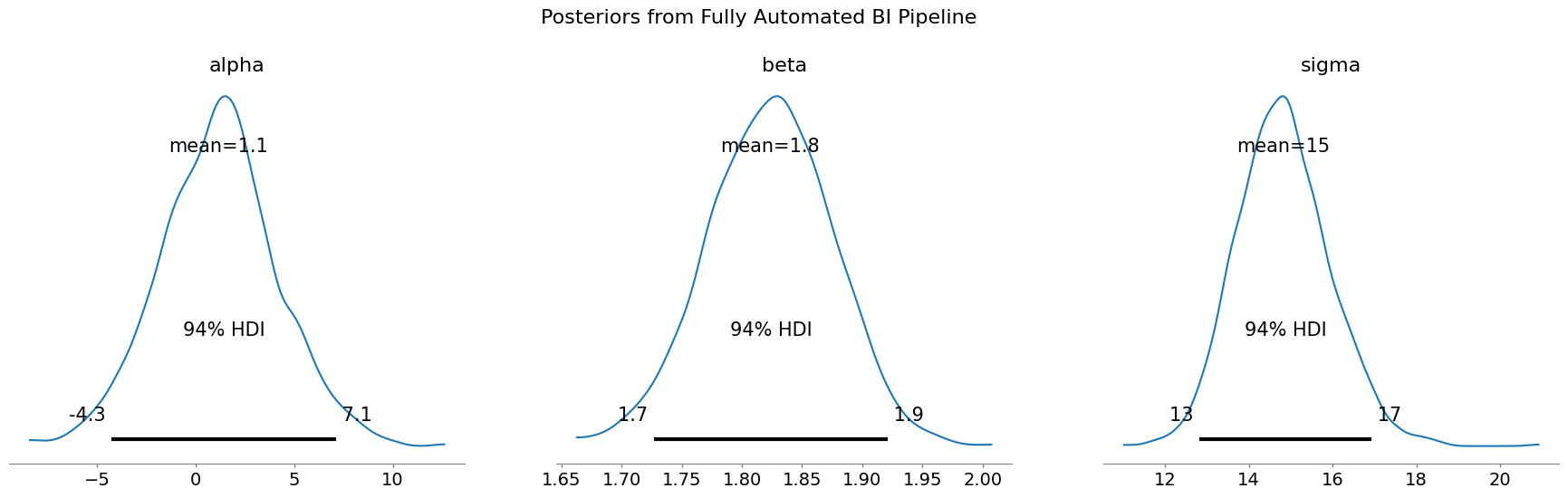
📊 实验亮点
实验结果表明,LLM能够成功地从自然语言中提取先验分布,并根据问题描述指定完整的贝叶斯模型结构,包括先验和似然函数。在贝叶斯线性回归任务中,LLM-BI能够生成与专家设计的模型相媲美的结果,验证了其在自动化贝叶斯建模方面的潜力。
🎯 应用场景
LLM-BI具有广泛的应用前景,例如在医疗诊断、金融风险评估、市场预测等领域,可以帮助非专业人士快速构建贝叶斯模型,进行数据分析和决策。该研究有望推动贝叶斯方法的普及,并促进人工智能在各个领域的应用。
📄 摘要(原文)
A significant barrier to the widespread adoption of Bayesian inference is the specification of prior distributions and likelihoods, which often requires specialized statistical expertise. This paper investigates the feasibility of using a Large Language Model (LLM) to automate this process. We introduce LLM-BI (Large Language Model-driven Bayesian Inference), a conceptual pipeline for automating Bayesian workflows. As a proof-of-concept, we present two experiments focused on Bayesian linear regression. In Experiment I, we demonstrate that an LLM can successfully elicit prior distributions from natural language. In Experiment II, we show that an LLM can specify the entire model structure, including both priors and the likelihood, from a single high-level problem description. Our results validate the potential of LLMs to automate key steps in Bayesian modeling, enabling the possibility of an automated inference pipeline for probabilistic programming.