IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model
作者: Anqing Jiang, Yu Gao, Yiru Wang, Zhigang Sun, Shuo Wang, Yuwen Heng, Hao Sun, Shichen Tang, Lijuan Zhu, Jinhao Chai, Jijun Wang, Zichong Gu, Hao Jiang, Li Sun
分类: cs.AI, cs.CV, cs.RO
发布日期: 2025-08-07 (更新: 2025-08-15)
备注: 9 pagres, 2 figures
💡 一句话要点
提出IRL-VLA,通过逆强化学习奖励世界模型训练视觉-语言-动作策略,提升端到端自动驾驶性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 逆强化学习 奖励世界模型 自动驾驶 闭环强化学习
📋 核心要点
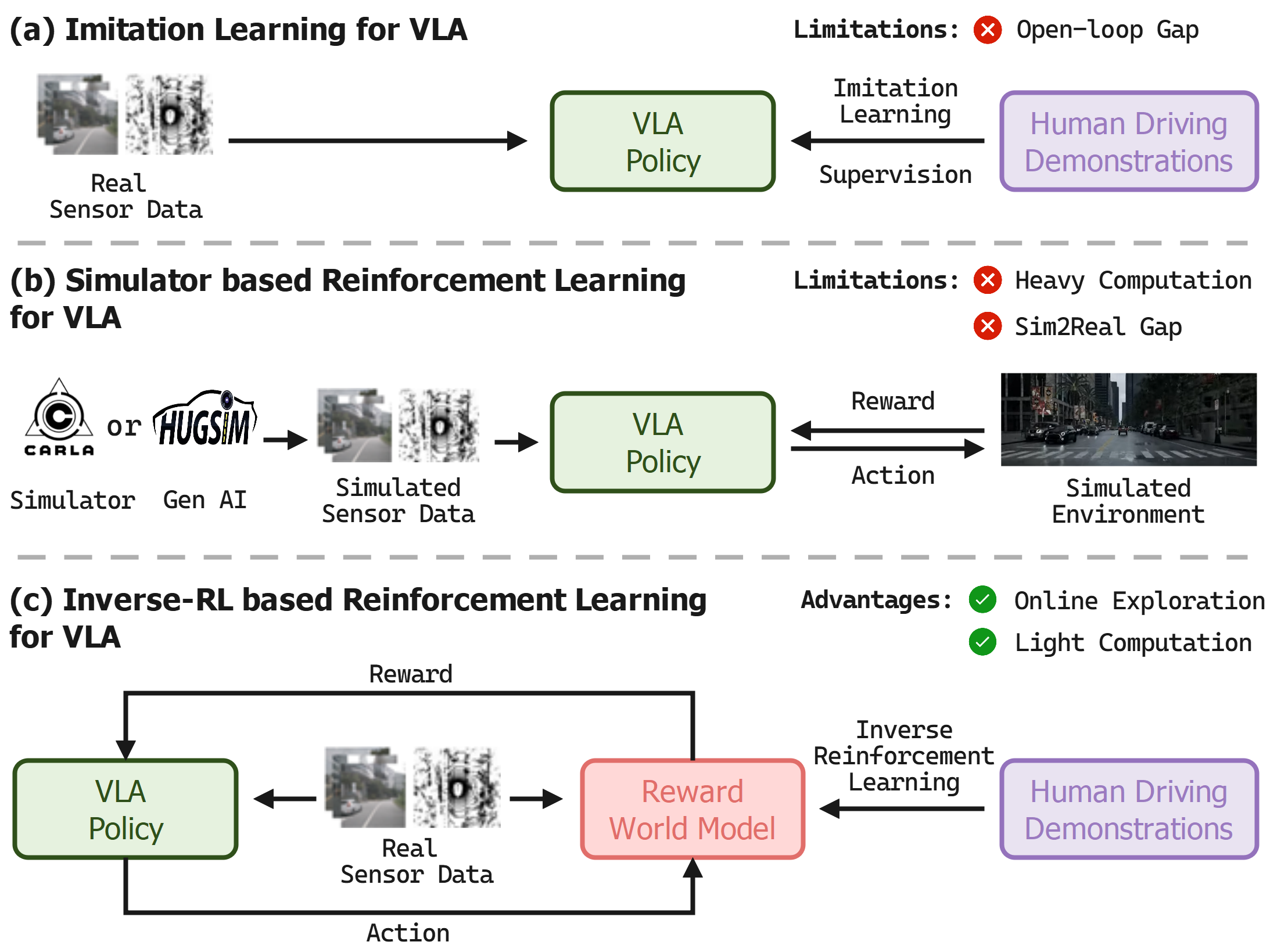
- 现有VLA模型依赖开环模仿学习,易受数据集行为限制,导致性能受限,难以适应复杂环境。
- IRL-VLA通过逆强化学习构建奖励世界模型,实现高效闭环奖励计算,引导策略学习。
- 实验表明,IRL-VLA在NAVSIM v2基准测试中达到SOTA,并在CVPR2025自动驾驶挑战赛中获得亚军。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在自动驾驶领域展现出巨大潜力。然而,其发展面临两个关键挑战:(1)现有VLA架构通常基于开环模仿学习,易于捕捉数据集中的记录行为,导致次优和受限的性能;(2)闭环训练严重依赖高保真传感器仿真,而领域差距和计算效率低下构成重大障碍。本文提出IRL-VLA,一种新颖的闭环强化学习方法,通过逆强化学习奖励世界模型以及自建的VLA方法实现。该框架采用三阶段范式:首先,提出VLA架构并通过模仿学习预训练VLA策略。其次,构建轻量级奖励世界模型,通过逆强化学习实现高效的闭环奖励计算。最后,为了进一步提高规划性能,设计了专门的奖励世界模型引导的强化学习,通过PPO(近端策略优化)有效平衡安全事件、舒适驾驶和交通效率。我们的方法在NAVSIM v2端到端驾驶基准测试中取得了最先进的性能,并在CVPR2025自动驾驶挑战赛中获得亚军。我们希望我们的框架能够加速闭环自动驾驶中的VLA研究。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在自动驾驶中面临两个主要问题:一是开环模仿学习导致策略受限于训练数据,泛化能力差;二是闭环训练依赖高保真仿真,存在领域差异和计算成本高的问题。因此,需要一种方法能够使VLA模型在闭环环境中进行有效训练,并具备良好的泛化能力和效率。
核心思路:IRL-VLA的核心思路是利用逆强化学习(IRL)构建一个奖励世界模型,该模型能够根据环境状态和动作预测奖励信号,从而避免了对真实奖励函数的依赖。通过奖励世界模型,VLA策略可以在闭环环境中进行强化学习,从而学习到更优的驾驶策略。同时,轻量级的奖励世界模型降低了计算成本,提高了训练效率。
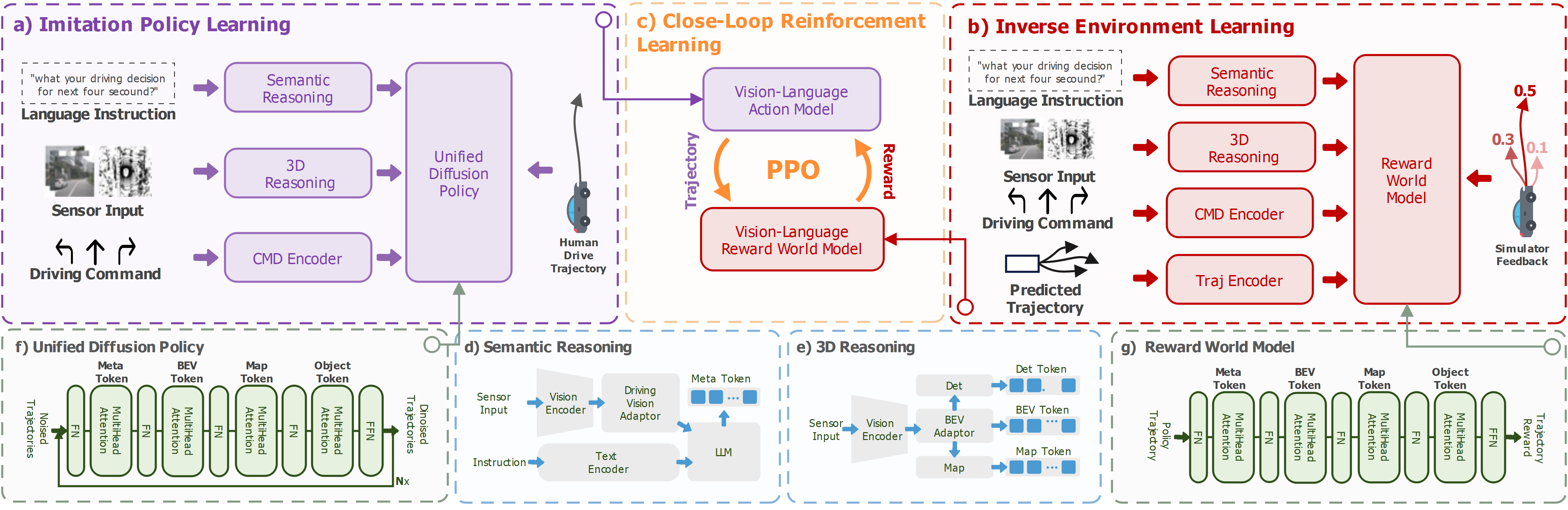
技术框架:IRL-VLA框架包含三个主要阶段: 1. VLA策略预训练:首先,设计一个VLA架构,并通过模仿学习在驾驶数据集上进行预训练,使策略具备初步的驾驶能力。 2. 奖励世界模型构建:利用逆强化学习,根据专家轨迹学习一个奖励世界模型。该模型以环境状态和动作为输入,预测奖励信号。为了提高效率,奖励世界模型被设计为轻量级。 3. 奖励世界模型引导的强化学习:使用奖励世界模型提供的奖励信号,通过PPO算法对VLA策略进行强化学习。为了平衡安全、舒适和效率,设计了专门的奖励函数。
关键创新:IRL-VLA的关键创新在于使用逆强化学习构建奖励世界模型,从而实现了VLA策略在闭环环境中的高效强化学习。与传统的依赖真实奖励函数的强化学习方法相比,IRL-VLA避免了手动设计奖励函数的困难,并能够更好地适应复杂环境。
关键设计: * VLA架构:具体架构未知,但应包含视觉、语言和动作三个模态的输入。 * 奖励世界模型:设计为轻量级,具体结构未知,但需要能够高效地预测奖励信号。 * 奖励函数:设计用于平衡安全事件、舒适驾驶和交通效率,具体形式未知。 * 强化学习算法:使用PPO算法进行策略优化。
🖼️ 关键图片
📊 实验亮点
IRL-VLA在NAVSIM v2端到端驾驶基准测试中取得了最先进的性能(SOTA),表明该方法在复杂驾驶环境中的有效性。此外,在CVPR2025自动驾驶挑战赛中获得亚军,进一步验证了其优越性。具体的性能数据和提升幅度未知,但结果表明IRL-VLA显著优于现有方法。
🎯 应用场景
IRL-VLA框架可应用于各种自动驾驶场景,例如城市道路、高速公路等。该方法能够提高自动驾驶系统的安全性、舒适性和效率,并降低开发成本。此外,该框架还可以扩展到其他视觉-语言-动作任务中,例如机器人导航、人机交互等,具有广泛的应用前景。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated potential in autonomous driving. However, two critical challenges hinder their development: (1) Existing VLA architectures are typically based on imitation learning in open-loop setup which tends to capture the recorded behaviors in the dataset, leading to suboptimal and constrained performance, (2) Close-loop training relies heavily on high-fidelity sensor simulation, where domain gaps and computational inefficiencies pose significant barriers. In this paper, we introduce IRL-VLA, a novel close-loop Reinforcement Learning via \textbf{I}nverse \textbf{R}einforcement \textbf{L}earning reward world model with a self-built VLA approach. Our framework proceeds in a three-stage paradigm: In the first stage, we propose a VLA architecture and pretrain the VLA policy via imitation learning. In the second stage, we construct a lightweight reward world model via inverse reinforcement learning to enable efficient close-loop reward computation. To further enhance planning performance, finally, we design specialized reward world model guidence reinforcement learning via PPO(Proximal Policy Optimization) to effectively balance the safety incidents, comfortable driving, and traffic efficiency. Our approach achieves state-of-the-art performance in NAVSIM v2 end-to-end driving benchmark, 1st runner up in CVPR2025 Autonomous Grand Challenge. We hope that our framework will accelerate VLA research in close-loop autonomous driving.