A Framework for Inherently Safer AGI through Language-Mediated Active Inference
作者: Bo Wen
分类: cs.AI, cs.LG, eess.SY, nlin.AO
发布日期: 2025-08-07
💡 一句话要点
提出一种基于语言介导主动推理的AGI安全框架,旨在实现内生安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用人工智能安全 主动推理 大型语言模型 自然语言表示 内生安全
📋 核心要点
- 现有AI安全方法依赖事后解释和奖励工程,但存在根本性局限,难以保证AGI的安全性。
- 该框架结合主动推理和LLM,利用自然语言作为媒介,实现透明的信念表示和分层价值对齐,从而内生性地保障安全。
- 论文提出了基于抽象和推理语料库(ARC)的实验计划,旨在验证该框架的安全属性。
📝 摘要(中文)
本文提出了一种新颖的框架,通过结合主动推理原则与大型语言模型(LLM),来开发安全的通用人工智能(AGI)。我们认为,传统的AI安全方法,侧重于事后可解释性和奖励工程,存在根本性的局限性。我们提出了一种架构,其中安全保证通过透明的信念表示和分层价值对齐,被集成到系统的核心设计中。我们的框架利用自然语言作为表示和操作信念的媒介,从而实现直接的人工监督,同时保持计算上的可处理性。该架构实现了一个多智能体系统,其中智能体根据主动推理原则进行自组织,偏好和安全约束通过分层马尔可夫毯流动。我们概述了确保安全的具体机制,包括:(1)在自然语言中显式分离信念和偏好,(2)通过资源感知的自由能最小化实现有界理性,以及(3)通过模块化智能体结构实现组合安全性。本文最后提出了一个以抽象和推理语料库(ARC)基准为中心的的研究议程,提出了实验来验证我们框架的安全属性。我们的方法提供了一条通往AGI开发的道路,这种开发本质上更安全,而不是事后才进行安全措施的改造。
🔬 方法详解
问题定义:现有AI安全方法,如事后可解释性和奖励工程,在面对通用人工智能(AGI)时,难以保证其安全性。这些方法通常是在模型训练完成后才进行安全措施的添加,无法从根本上解决潜在的安全问题。此外,AGI的复杂性使得事后解释变得困难,而奖励工程则容易导致目标异化。
核心思路:该论文的核心思路是将安全保证集成到AGI系统的核心设计中,而不是作为事后的补丁。通过结合主动推理原则和大型语言模型(LLM),利用自然语言作为信念表示和操作的媒介,实现透明的信念表示和分层价值对齐。这种设计允许直接的人工监督,同时保持计算上的可处理性,从而实现内生安全性。
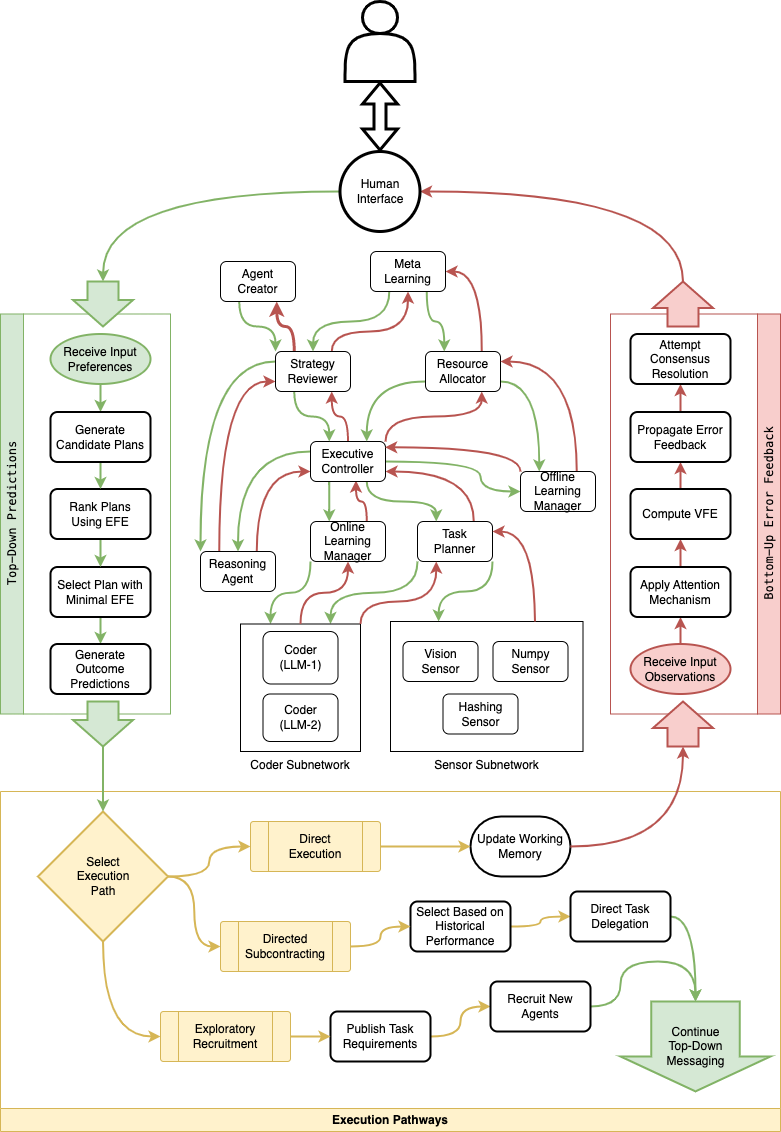
技术框架:该框架采用多智能体系统架构,其中智能体根据主动推理原则进行自组织。每个智能体都有自己的信念和偏好,这些信念和偏好以自然语言的形式表示。智能体之间的交互通过分层马尔可夫毯进行,偏好和安全约束在层级结构中流动。整个系统通过资源感知的自由能最小化来实现有界理性,确保智能体在有限的资源下做出合理的决策。模块化的智能体结构则实现了组合安全性,使得系统的整体安全性可以通过各个模块的安全性的组合来保证。
关键创新:该论文最重要的技术创新点在于将主动推理、大型语言模型和自然语言表示相结合,构建了一个内生安全的AGI框架。与传统的AI安全方法相比,该框架不是在模型训练完成后才考虑安全问题,而是将安全保证集成到系统的核心设计中。此外,利用自然语言作为信念表示的媒介,使得人工监督成为可能,从而增强了系统的可解释性和可控性。
关键设计:框架的关键设计包括:(1) 使用自然语言显式分离信念和偏好,避免信念受到偏好的影响;(2) 通过资源感知的自由能最小化实现有界理性,防止智能体过度追求目标而忽略安全约束;(3) 采用模块化智能体结构,实现组合安全性,使得系统的整体安全性可以通过各个模块的安全性的组合来保证。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未来研究的方向。
🖼️ 关键图片
📊 实验亮点
论文提出了一个基于语言介导主动推理的AGI安全框架,并设计了基于抽象和推理语料库(ARC)的实验计划,以验证该框架的安全属性。虽然论文没有提供具体的性能数据和对比基线,但其提出的内生安全设计理念为AGI安全研究提供了一个新的方向。
🎯 应用场景
该研究成果可应用于开发更安全的通用人工智能系统,尤其是在高风险领域,如医疗、金融和自动驾驶。通过内生安全设计,可以降低AGI系统出现意外行为的风险,提高其可靠性和可信度。未来,该框架有望成为AGI安全领域的重要参考。
📄 摘要(原文)
This paper proposes a novel framework for developing safe Artificial General Intelligence (AGI) by combining Active Inference principles with Large Language Models (LLMs). We argue that traditional approaches to AI safety, focused on post-hoc interpretability and reward engineering, have fundamental limitations. We present an architecture where safety guarantees are integrated into the system's core design through transparent belief representations and hierarchical value alignment. Our framework leverages natural language as a medium for representing and manipulating beliefs, enabling direct human oversight while maintaining computational tractability. The architecture implements a multi-agent system where agents self-organize according to Active Inference principles, with preferences and safety constraints flowing through hierarchical Markov blankets. We outline specific mechanisms for ensuring safety, including: (1) explicit separation of beliefs and preferences in natural language, (2) bounded rationality through resource-aware free energy minimization, and (3) compositional safety through modular agent structures. The paper concludes with a research agenda centered on the Abstraction and Reasoning Corpus (ARC) benchmark, proposing experiments to validate our framework's safety properties. Our approach offers a path toward AGI development that is inherently safer, rather than retrofitted with safety measures.