InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
作者: Yuhang Liu, Zeyu Liu, Shuanghe Zhu, Pengxiang Li, Congkai Xie, Jiasheng Wang, Xavier Hu, Xiaotian Han, Jianbo Yuan, Xinyao Wang, Shengyu Zhang, Hongxia Yang, Fei Wu
分类: cs.AI, cs.CL
发布日期: 2025-08-07 (更新: 2025-12-08)
备注: Accepted to AAAI 2026 (Oral Presentation)
🔗 代码/项目: GITHUB
💡 一句话要点
InfiGUI-G1提出自适应探索策略优化AEPO,提升GUI界面操作的语义对齐能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI操作 多模态大语言模型 强化学习 语义对齐 自适应探索策略优化
📋 核心要点
- 现有方法在GUI操作中,语义对齐不足导致模型难以学习复杂的指令与UI元素间的关联。
- 论文提出AEPO框架,通过多答案生成和自适应探索奖励,鼓励模型更广泛和高效地探索。
- 实验表明,AEPO训练的模型在GUI grounding任务上显著优于现有方法,提升高达9.0%。
📝 摘要(中文)
多模态大型语言模型(MLLM)的出现推动了自主智能体的发展,这些智能体能够仅使用视觉输入在图形用户界面(GUI)上操作。一个根本性的挑战是稳健地理解自然语言指令,这需要精确的空间对齐(准确定位每个元素的坐标)以及更关键的语义对齐(将指令与功能上合适的UI元素匹配)。尽管带有可验证奖励的强化学习(RLVR)已被证明可以有效地提高这些MLLM的空间对齐能力,但我们发现低效的探索会阻碍语义对齐,从而阻止模型学习困难的语义关联。为了解决这个探索问题,我们提出了自适应探索策略优化(AEPO),一个新的策略优化框架。AEPO采用多答案生成策略来强制更广泛的探索,然后由一个理论上基于效率η=U/C第一性原理的自适应探索奖励(AER)函数来指导。我们经过AEPO训练的模型InfiGUI-G1-3B和InfiGUI-G1-7B在多个具有挑战性的GUI grounding基准测试中建立了新的最先进的结果,在旨在测试泛化和语义理解的基准测试中,相对于朴素的RLVR基线,实现了高达9.0%的显著相对改进。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型在GUI界面操作中,由于探索效率低下导致的语义对齐问题。现有基于强化学习的方法,虽然能较好地进行空间对齐,但在学习复杂的语义关联时,由于探索不足,性能受到限制。模型难以将自然语言指令与功能对应的UI元素精准匹配。
核心思路:论文的核心思路是通过改进探索策略,提高模型探索的广度和效率。具体而言,通过多答案生成策略,鼓励模型尝试不同的操作,从而扩大探索空间。同时,设计自适应探索奖励函数,根据探索的效率(收益与成本之比)来引导模型的探索方向,使其更倾向于探索有价值的区域。
技术框架:AEPO框架主要包含以下几个模块:1) 多答案生成模块:根据当前状态生成多个可能的动作;2) 执行环境:执行生成的动作,并返回环境反馈;3) 自适应探索奖励模块:根据环境反馈计算自适应探索奖励;4) 策略优化模块:利用自适应探索奖励优化策略网络。整体流程是,模型首先生成多个候选动作,然后环境执行这些动作并给出反馈,接着自适应探索奖励模块根据反馈计算奖励,最后策略优化模块利用奖励更新策略网络。
关键创新:最重要的技术创新点是自适应探索奖励(AER)函数的设计。AER函数基于效率η=U/C的第一性原理,其中U代表探索带来的收益,C代表探索的成本。通过最大化探索效率,引导模型更有效地探索。与传统的固定奖励或稀疏奖励相比,AER能够更准确地反映探索的价值,从而提高学习效率。
关键设计:多答案生成策略的具体实现方式未知,可能采用了类似于集束搜索的方法。自适应探索奖励函数的具体形式未知,但应该包含了对探索收益和成本的量化。策略优化模块可能采用了常见的策略梯度算法,如PPO或Actor-Critic。
🖼️ 关键图片

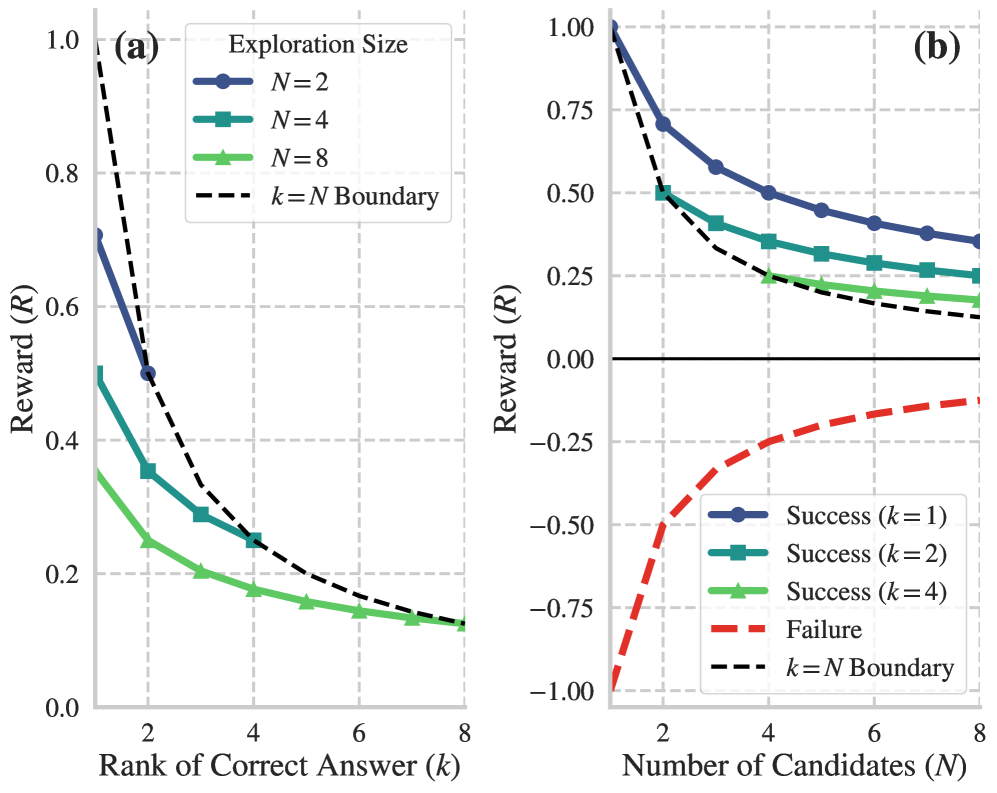
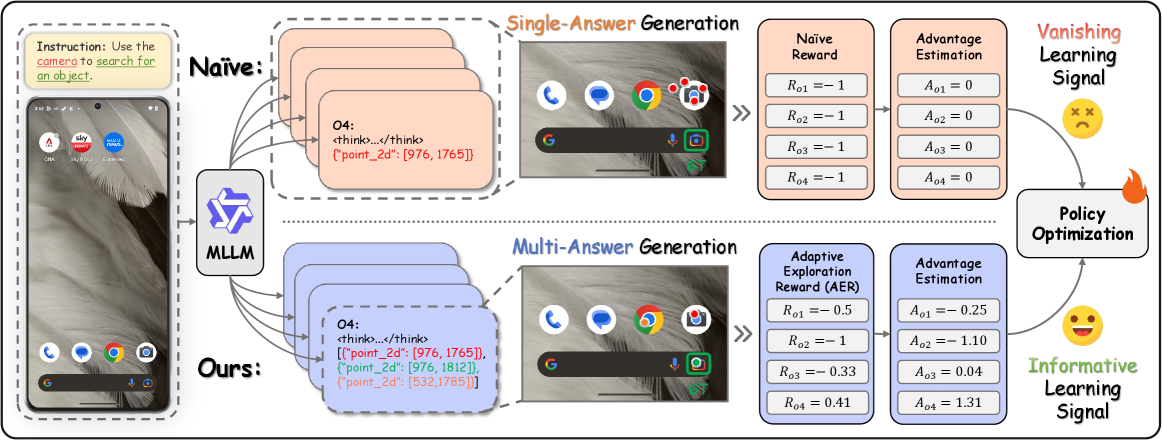
📊 实验亮点
InfiGUI-G1-3B和InfiGUI-G1-7B模型在多个GUI grounding基准测试中取得了state-of-the-art的结果,相较于naive RLVR基线,在测试泛化和语义理解的基准测试中,实现了高达9.0%的相对改进。这表明AEPO框架能够有效提升模型在复杂GUI环境下的操作能力。
🎯 应用场景
该研究成果可应用于开发更智能的自动化GUI操作代理,例如自动化测试、RPA(机器人流程自动化)、辅助残障人士使用计算机等。通过提升模型对GUI界面的理解和操作能力,可以实现更高效、更可靠的人机交互。
📄 摘要(原文)
The emergence of Multimodal Large Language Models (MLLMs) has propelled the development of autonomous agents that operate on Graphical User Interfaces (GUIs) using pure visual input. A fundamental challenge is robustly grounding natural language instructions. This requires a precise spatial alignment, which accurately locates the coordinates of each element, and, more critically, a correct semantic alignment, which matches the instructions to the functionally appropriate UI element. Although Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be effective at improving spatial alignment for these MLLMs, we find that inefficient exploration bottlenecks semantic alignment, which prevent models from learning difficult semantic associations. To address this exploration problem, we present Adaptive Exploration Policy Optimization (AEPO), a new policy optimization framework. AEPO employs a multi-answer generation strategy to enforce broader exploration, which is then guided by a theoretically grounded Adaptive Exploration Reward (AER) function derived from first principles of efficiency eta=U/C. Our AEPO-trained models, InfiGUI-G1-3B and InfiGUI-G1-7B, establish new state-of-the-art results across multiple challenging GUI grounding benchmarks, achieving significant relative improvements of up to 9.0% against the naive RLVR baseline on benchmarks designed to test generalization and semantic understanding. Resources are available at https://github.com/InfiXAI/InfiGUI-G1.