Klear-CodeTest: Scalable Test Case Generation for Code Reinforcement Learning
作者: Jia Fu, Xinyu Yang, Hongzhi Zhang, Yahui Liu, Jingyuan Zhang, Qi Wang, Fuzheng Zhang, Guorui Zhou
分类: cs.SE, cs.AI
发布日期: 2025-08-07 (更新: 2025-09-11)
备注: 21 pages, 11 figures
🔗 代码/项目: GITHUB
💡 一句话要点
Klear-CodeTest:用于代码强化学习的可扩展测试用例生成框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码强化学习 测试用例生成 生成器-验证框架 一致性验证 安全沙箱 大型语言模型 代码质量 程序自动修复
📋 核心要点
- 代码强化学习中,高质量测试用例的匮乏严重阻碍了LLM的有效训练,现有方法难以保证测试用例的覆盖率和正确性。
- Klear-CodeTest采用生成器-验证(G-V)框架,通过一致性验证确保测试用例的正确性,并覆盖常规和边界情况。
- 实验表明,使用Klear-CodeTest生成的数据集能显著提升模型性能和训练稳定性,验证了其有效性。
📝 摘要(中文)
在代码强化学习中,精确且正确的反馈对于有效训练大型语言模型(LLMs)至关重要。然而,合成高质量的测试用例仍然是一个极具挑战且尚未解决的问题。本文提出了Klear-CodeTest,一个全面的测试用例合成框架,它具有严格的验证机制,以确保测试用例的质量和可靠性。我们的方法通过一种新颖的生成器-验证(G-V)框架实现了对编程问题的广泛覆盖,并通过一致性验证机制(针对黄金标准解决方案验证输出)来确保正确性。所提出的G-V框架生成全面的测试用例,包括常规用例和边界用例,从而增强了测试覆盖率和代码强化学习中解决方案正确性评估的区分能力。此外,我们设计了一个针对在线验证平台优化的多层安全沙箱系统,保证了安全可靠的代码执行。通过全面的实验,我们证明了我们精心策划的数据集的有效性,在模型性能和训练稳定性方面均显示出显著的改进。源代码、数据集和沙箱系统可在https://github.com/Kwai-Klear/CodeTest获取。
🔬 方法详解
问题定义:现有代码强化学习方法在训练大型语言模型时,面临着缺乏高质量测试用例的问题。这些测试用例需要具备广泛的覆盖率,能够涵盖各种常规和边界情况,并且必须保证其正确性,以提供可靠的反馈信号。现有方法难以同时满足这些要求,导致模型训练效率低下,甚至产生错误的学习结果。
核心思路:Klear-CodeTest的核心思路是采用生成器-验证(G-V)框架,将测试用例的生成和验证过程分离。生成器负责生成各种可能的测试用例,而验证器则负责对生成的测试用例进行严格的正确性检查。通过这种方式,可以有效地提高测试用例的质量和覆盖率,从而为代码强化学习提供更可靠的训练数据。
技术框架:Klear-CodeTest的整体框架包含以下几个主要模块:1) 问题理解模块:分析编程问题的描述,提取关键信息。2) 测试用例生成器:基于问题理解,生成包括常规用例和边界用例在内的多种测试用例。3) 一致性验证器:将生成的测试用例输入到黄金标准解决方案中,并比较输出结果,以验证测试用例的正确性。4) 安全沙箱系统:提供安全可靠的代码执行环境,防止恶意代码对系统造成损害。
关键创新:Klear-CodeTest的关键创新在于其G-V框架和一致性验证机制。G-V框架将测试用例的生成和验证过程分离,提高了测试用例的质量和覆盖率。一致性验证机制通过与黄金标准解决方案进行比较,确保了测试用例的正确性。此外,多层安全沙箱系统保证了代码执行的安全性。
关键设计:G-V框架中,生成器采用多种策略生成测试用例,包括随机生成、基于规则生成和基于模板生成等。一致性验证器采用多种比较方法,包括精确匹配、模糊匹配和语义匹配等。安全沙箱系统采用多层隔离技术,包括进程隔离、资源限制和网络隔离等。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

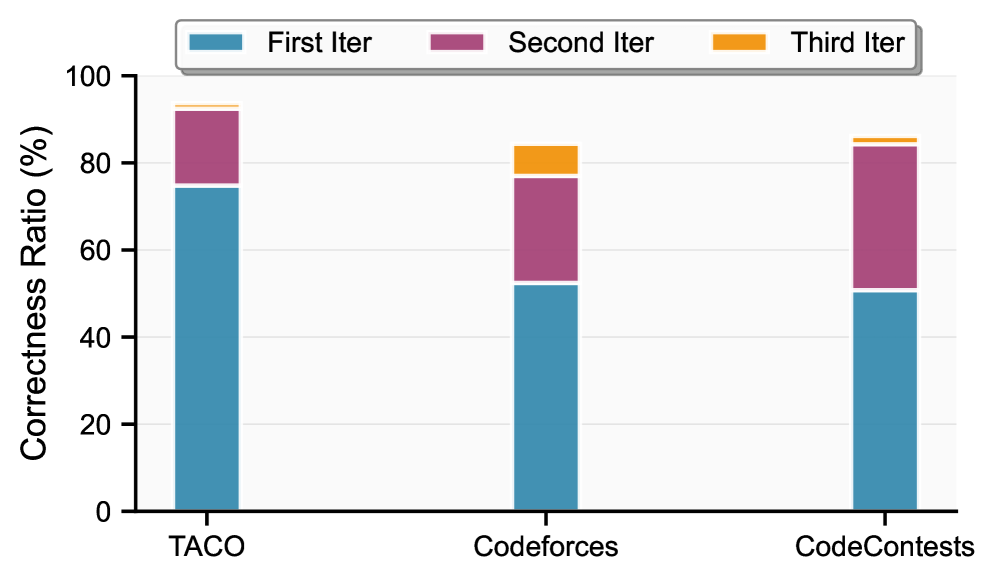

📊 实验亮点
实验结果表明,使用Klear-CodeTest生成的数据集训练的代码模型在多个编程任务上取得了显著的性能提升。与使用传统方法生成的数据集相比,模型在代码正确率和执行效率方面均有明显改善。具体提升幅度和对比基线在论文中进行了详细描述,但此处未提供具体数值。
🎯 应用场景
Klear-CodeTest可广泛应用于代码强化学习、程序自动修复、代码生成等领域。通过提供高质量的测试用例,可以有效提升代码模型的性能和可靠性,加速软件开发过程,降低开发成本。未来,该技术有望应用于更复杂的软件系统和编程语言,推动软件工程领域的智能化发展。
📄 摘要(原文)
Precise, correct feedback is crucial for effectively training large language models (LLMs) in code reinforcement learning. However, synthesizing high-quality test cases remains a profoundly challenging and unsolved problem. In this work, we present Klear-CodeTest, a comprehensive test case synthesis framework featuring rigorous verification to ensure quality and reliability of test cases. Our approach achieves broad coverage of programming problems via a novel Generator-Validation (G-V) framework, ensuring correctness through a consistency validation mechanism that verifies outputs against gold solutions. The proposed G-V framework generates comprehensive test cases including both regular and corner cases, enhancing test coverage and discriminative power for solution correctness assessment in code reinforcement learning. In addition, we design a multi-layered security sandbox system optimized for online verification platforms, guaranteeing safe and reliable code execution. Through comprehensive experiments, we demonstrate the effectiveness of our curated dataset, showing significant improvements in model performance and training stability. The source codes, curated dataset and sandbox system are available at: https://github.com/Kwai-Klear/CodeTest.