Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
作者: Roshita Bhonsle, Rishav Dutta, Sneha Vavilapalli, Harsh Seth, Abubakarr Jaye, Yapei Chang, Mukund Rungta, Emmanuel Aboah Boateng, Sadid Hasan, Ehi Nosakhare, Soundar Srinivasan
分类: cs.AI
发布日期: 2025-08-07
💡 一句话要点
提出Auto-Eval Judge通用框架,用于评估Agent任务完成质量,提升评估与人类对齐度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent评估 任务完成评估 通用框架 模块化设计 LLM-as-a-Judge Agent-as-a-Judge 推理评估 自动化评估
📋 核心要点
- 现有Agent评估方法主要关注最终输出或局限于特定领域,忽略了Agent的推理过程和通用性。
- 提出Auto-Eval Judge框架,通过分解任务为子任务并验证每一步骤,模拟人类评估Agent任务完成质量。
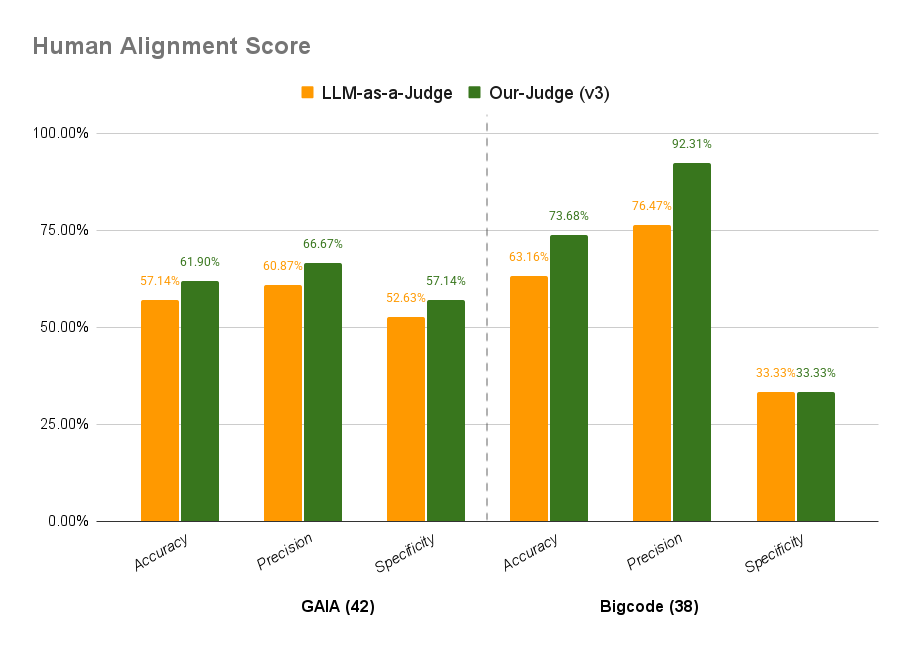
- 实验表明,该框架在GAIA和BigCodeBench基准测试中,与人类评估的对齐精度分别提升了4.76%和10.52%。
📝 摘要(中文)
随着基础模型在各个领域作为Agent的应用日益广泛,一个鲁棒的评估框架变得至关重要。现有方法,如LLM-as-a-Judge,仅关注最终输出,忽略了驱动Agent决策的逐步推理过程。而现有的Agent-as-a-Judge系统通常为狭窄的、特定领域的设置而设计。为了解决这一差距,我们提出了一个通用的、模块化的框架,用于评估Agent任务完成情况,且与任务领域无关。该框架通过将任务分解为子任务,并使用可用信息(如Agent的输出和推理)验证每个步骤,从而模拟类似人类的评估。每个模块都对评估过程的特定方面做出贡献,并且它们的输出被聚合以产生关于任务完成的最终判断。我们通过在GAIA和BigCodeBench两个基准上评估Magentic-One Actor Agent来验证我们的框架。我们的Judge Agent预测任务成功的准确性与人类评估更接近,分别实现了4.76%和10.52%的更高对齐精度,与基于GPT-4o的LLM-as-a-Judge基线相比。这证明了我们提出的通用评估框架的潜力。
🔬 方法详解
问题定义:现有Agent评估方法存在局限性。LLM-as-a-Judge方法只关注最终输出,无法评估Agent的中间推理过程。Agent-as-a-Judge方法虽然可以评估中间过程,但通常是针对特定领域设计的,缺乏通用性。因此,需要一种通用的、能够评估Agent逐步推理过程的评估框架。
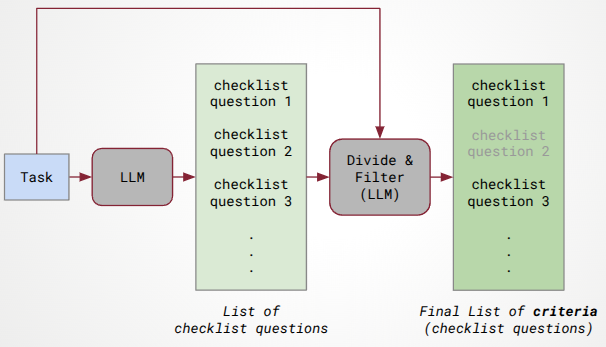
核心思路:Auto-Eval Judge框架的核心思路是模拟人类的评估方式,将复杂的任务分解为多个子任务,并对每个子任务的完成情况进行评估。通过对每个步骤的验证,可以更全面地了解Agent的推理过程,从而更准确地评估其任务完成质量。这种分解和验证的方式使得评估过程更加透明和可解释。
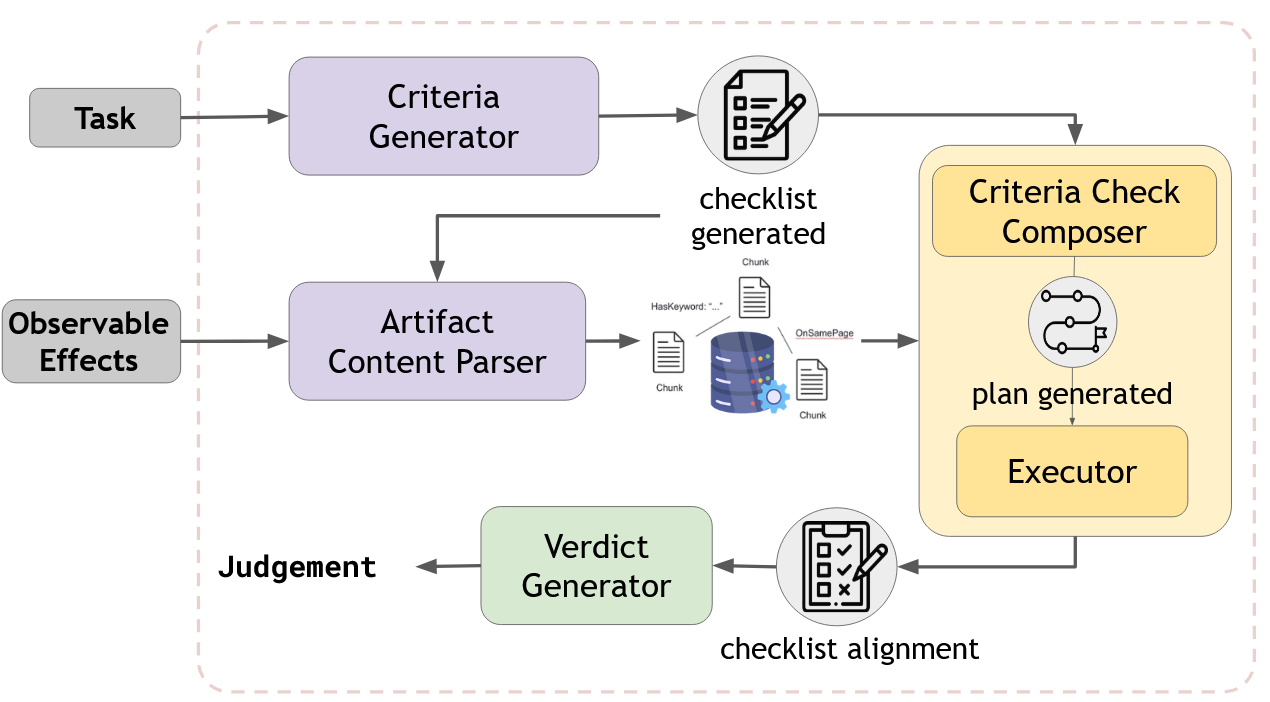
技术框架:Auto-Eval Judge框架是一个模块化的框架,包含多个模块,每个模块负责评估过程的特定方面。整体流程如下:1. 任务分解:将Agent需要完成的复杂任务分解为多个子任务。2. 信息收集:收集Agent在完成每个子任务时产生的输出和推理过程信息。3. 模块评估:使用不同的评估模块对每个子任务的完成情况进行评估。这些模块可以包括正确性验证、逻辑一致性检查、效率评估等。4. 结果聚合:将各个模块的评估结果进行聚合,得到最终的评估结果。
关键创新:该框架的关键创新在于其通用性和模块化设计。通用性体现在该框架可以应用于不同领域的Agent评估,而无需进行特定领域的定制。模块化设计使得可以根据不同的评估需求,灵活地选择和组合不同的评估模块。此外,该框架通过模拟人类的评估方式,提高了评估结果与人类判断的一致性。
关键设计:框架的关键设计包括:1. 任务分解策略:如何将复杂任务分解为合适的子任务,需要根据具体任务的特点进行设计。2. 评估模块的选择:根据评估目标选择合适的评估模块,例如,可以使用LLM进行正确性验证,使用规则引擎进行逻辑一致性检查。3. 结果聚合方法:如何将各个模块的评估结果进行有效聚合,需要考虑不同模块的权重和依赖关系。论文中未明确给出具体参数设置、损失函数或网络结构等细节,这部分信息未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Auto-Eval Judge框架在GAIA和BigCodeBench两个基准测试中,与人类评估的对齐精度分别提升了4.76%和10.52%,显著优于基于GPT-4o的LLM-as-a-Judge基线。这表明该框架能够更准确地评估Agent的任务完成质量,并与人类的判断更加一致。
🎯 应用场景
该研究成果可广泛应用于各种Agent系统的评估,例如智能客服、自动驾驶、代码生成等。通过提供更准确、更全面的评估,可以帮助开发者更好地改进Agent的性能,提高Agent的可靠性和安全性。此外,该框架还可以用于Agent之间的比较和选择,为用户提供更好的Agent服务。
📄 摘要(原文)
The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.