Can Large Language Models Generate Effective Datasets for Emotion Recognition in Conversations?
作者: Burak Can Kaplan, Hugo Cesar De Castro Carneiro, Stefan Wermter
分类: cs.AI, cs.CL
发布日期: 2025-08-07
备注: 8 pages, 4 figures
💡 一句话要点
利用小型语言模型生成对话情绪识别数据集,提升模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话情绪识别 数据生成 大型语言模型 数据增强 情感分析
📋 核心要点
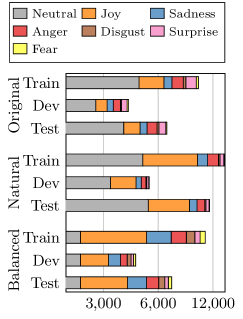
- 对话情绪识别数据稀缺,现有数据集存在偏差和主观性问题,限制了模型性能。
- 利用小型通用语言模型生成多样化的对话情绪识别数据集,以补充现有数据集。
- 实验表明,使用生成数据集训练的模型在现有基准测试中取得了显著的性能提升,具有更强的鲁棒性。
📝 摘要(中文)
对话情绪识别(ERC)旨在识别交互过程中的情绪变化,是提升机器智能的重要一步。然而,ERC数据仍然稀缺,且现有数据集由于其高度偏差的来源和软标签的内在主观性而面临诸多挑战。尽管大型语言模型(LLM)已在许多情感任务中展示了其质量,但它们的训练成本通常很高,并且它们在ERC任务中的应用(尤其是在数据生成方面)仍然有限。为了应对这些挑战,我们采用了一个小型的、资源高效的通用LLM来合成具有多样化属性的ERC数据集,以补充三个最广泛使用的ERC基准。我们生成了六个新的数据集,每个基准都定制了两个数据集以进行增强。我们评估这些数据集的效用,以(1)补充现有数据集以进行ERC分类,以及(2)分析ERC中标签不平衡的影响。我们的实验结果表明,在生成的数据集上训练的ERC分类器模型表现出强大的鲁棒性,并且在现有ERC基准上始终获得具有统计意义的性能改进。
🔬 方法详解
问题定义:对话情绪识别(ERC)任务旨在识别对话中每个话语的情绪。现有ERC数据集规模小、存在偏差,且标注具有主观性,导致模型泛化能力差。大型语言模型虽然能力强大,但训练成本高昂,难以直接应用于生成ERC数据集。
核心思路:利用小型、资源高效的通用语言模型,通过精心设计的prompt,生成高质量、多样化的ERC数据集。通过补充现有数据集,缓解数据稀缺和偏差问题,提升ERC模型的性能和鲁棒性。
技术框架:该方法的核心是使用小型LLM生成数据集。具体流程如下:1) 设计prompt,指导LLM生成包含对话和对应情绪标签的数据;2) 生成六个新的数据集,每个数据集针对三个主流ERC基准进行定制;3) 使用生成的数据集训练ERC分类器模型;4) 在现有ERC基准上评估模型性能。
关键创新:该方法的核心创新在于利用小型LLM生成高质量的ERC数据集,降低了数据生成的成本,同时通过多样化的数据增强,提升了模型的泛化能力。与直接使用大型LLM进行微调相比,该方法更具成本效益,且更易于部署。
关键设计:关键设计包括:1) prompt的设计,需要确保LLM能够生成符合ERC任务要求的数据;2) 数据集的多样性设计,需要考虑不同情绪、不同对话场景等因素;3) 实验评估,需要选择合适的基准模型和评估指标,以验证生成数据集的有效性。具体的参数设置、损失函数、网络结构等技术细节未在摘要中体现,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用生成的数据集训练的ERC分类器模型在现有ERC基准上取得了显著的性能提升,证明了生成数据集的有效性。具体提升幅度未在摘要中给出,属于未知信息。该方法生成的模型具有更强的鲁棒性,能够更好地应对真实场景中的复杂对话。
🎯 应用场景
该研究成果可应用于智能客服、心理咨询、人机交互等领域,提升机器理解人类情感的能力,从而提供更个性化、更贴心的服务。通过生成高质量的对话情绪识别数据集,可以降低模型训练成本,促进相关技术的发展和应用。
📄 摘要(原文)
Emotion recognition in conversations (ERC) focuses on identifying emotion shifts within interactions, representing a significant step toward advancing machine intelligence. However, ERC data remains scarce, and existing datasets face numerous challenges due to their highly biased sources and the inherent subjectivity of soft labels. Even though Large Language Models (LLMs) have demonstrated their quality in many affective tasks, they are typically expensive to train, and their application to ERC tasks--particularly in data generation--remains limited. To address these challenges, we employ a small, resource-efficient, and general-purpose LLM to synthesize ERC datasets with diverse properties, supplementing the three most widely used ERC benchmarks. We generate six novel datasets, with two tailored to enhance each benchmark. We evaluate the utility of these datasets to (1) supplement existing datasets for ERC classification, and (2) analyze the effects of label imbalance in ERC. Our experimental results indicate that ERC classifier models trained on the generated datasets exhibit strong robustness and consistently achieve statistically significant performance improvements on existing ERC benchmarks.