Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
作者: Lishui Fan, Yu Zhang, Mouxiang Chen, Zhongxin Liu
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2025-08-07 (更新: 2025-09-17)
💡 一句话要点
提出Posterior-GRPO,通过奖励代码生成中的推理过程提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 强化学习 奖励模型 推理过程 Reward Hacking
📋 核心要点
- 现有代码生成方法依赖于测试用例的结果奖励,忽略了中间推理过程的质量,容易导致奖励黑客问题。
- Posterior-GRPO通过仅奖励成功代码生成结果的推理过程,缓解奖励黑客问题,并将模型推理与代码正确性对齐。
- 实验表明,P-GRPO在代码生成任务中优于仅基于结果的基线4.5%,并达到与GPT-4-Turbo相当的性能。
📝 摘要(中文)
本文提出了一种统一的框架,旨在有效结合强化学习中推理过程的质量,以提升大型语言模型(LLMs)的代码生成能力。为了评估推理过程,我们构建了LCB-RB基准,其中包含高质量和低质量推理过程的偏好对。为了准确评估推理质量,我们引入了一种基于优化-退化(OD-based)的方法来训练奖励模型,该方法通过系统地优化和退化初始推理路径,生成高质量的偏好对,并关注事实准确性、逻辑严谨性和连贯性等维度。一个7B参数的奖励模型在该方法下,在LCB-RB上实现了最先进的性能,并能很好地泛化到其他基准。此外,我们引入了Posterior-GRPO (P-GRPO),这是一种新型的强化学习方法,它将基于过程的奖励建立在任务成功的基础上。通过仅对成功结果的推理过程选择性地应用奖励,P-GRPO有效地缓解了奖励黑客问题,并将模型的内部推理与最终代码的正确性对齐。一个具有P-GRPO的7B参数模型在各种代码生成任务中实现了卓越的性能,超过了仅基于结果的基线4.5%,并达到了与GPT-4-Turbo相当的性能。我们进一步通过将其扩展到数学任务来证明我们方法的通用性。我们的模型、数据集和代码已公开。
🔬 方法详解
问题定义:现有基于强化学习的代码生成方法主要依赖于最终结果(例如,通过测试用例)来提供奖励信号,而忽略了代码生成过程中间推理步骤的质量。这种方式容易导致模型为了获得高奖励而“投机取巧”,即reward hacking,生成看似正确但实际推理过程错误的程序。因此,如何有效地将推理过程的质量纳入强化学习框架,避免reward hacking,是本文要解决的核心问题。
核心思路:本文的核心思路是提出Posterior-GRPO (P-GRPO),一种新型的强化学习方法,它有条件地将基于过程的奖励应用于任务成功的情况。具体来说,P-GRPO只对那些最终生成正确代码的推理过程给予奖励,从而确保模型学习到的推理过程不仅能够生成正确的代码,而且其内部的推理逻辑也是合理的。这种设计旨在缓解reward hacking问题,鼓励模型进行更可靠和可解释的推理。
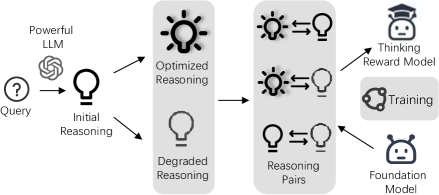
技术框架:P-GRPO的整体框架包含以下几个主要组成部分:1) LCB-RB基准数据集,用于评估推理过程的质量;2) 基于优化-退化(OD-based)方法的奖励模型训练,用于准确评估推理质量;3) P-GRPO强化学习算法,用于训练代码生成模型。首先,使用OD-based方法训练奖励模型,该模型能够区分高质量和低质量的推理过程。然后,在强化学习过程中,P-GRPO根据最终代码的正确性,有选择性地将奖励应用于推理过程。
关键创新:本文的关键创新在于提出了Posterior-GRPO (P-GRPO) 算法,它将过程奖励与任务成功联系起来,从而有效地缓解了reward hacking问题。与传统的强化学习方法不同,P-GRPO不是无差别地奖励所有的推理过程,而是只奖励那些最终导致正确代码的推理过程。这种有选择性的奖励机制能够更好地引导模型学习到正确的推理逻辑。
关键设计:在奖励模型训练方面,采用了基于优化-退化(OD-based)的方法来生成高质量的偏好对。具体来说,首先对初始推理路径进行优化,例如通过增加事实准确性、逻辑严谨性和连贯性等维度来提高其质量。然后,对初始推理路径进行退化,例如通过引入错误的事实、不严谨的逻辑或不连贯的推理来降低其质量。通过比较优化后的推理路径和退化后的推理路径,可以训练出一个能够准确评估推理质量的奖励模型。在P-GRPO算法中,奖励函数的设计至关重要,它需要能够准确地反映推理过程的质量,并且能够有效地引导模型学习到正确的推理逻辑。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用P-GRPO训练的7B参数模型在代码生成任务中取得了显著的性能提升,超过了仅基于结果的基线4.5%,并且达到了与GPT-4-Turbo相当的性能。此外,该方法在数学问题求解任务中也表现出良好的泛化能力,证明了其有效性和通用性。
🎯 应用场景
该研究成果可广泛应用于代码生成、数学问题求解等领域,有助于提升AI模型的可靠性和可解释性。通过奖励高质量的推理过程,可以训练出更值得信赖的AI系统,在软件开发、自动化测试、教育等领域具有重要的应用价值和潜力。
📄 摘要(原文)
Reinforcement learning (RL) has significantly advanced code generation for large language models (LLMs). However, current paradigms rely on outcome-based rewards from test cases, neglecting the quality of the intermediate reasoning process. While supervising the reasoning process directly is a promising direction, it is highly susceptible to reward hacking, where the policy model learns to exploit the reasoning reward signal without improving final outcomes. To address this, we introduce a unified framework that can effectively incorporate the quality of the reasoning process during RL. First, to enable reasoning evaluation, we develop LCB-RB, a benchmark comprising preference pairs of superior and inferior reasoning processes. Second, to accurately score reasoning quality, we introduce an Optimized-Degraded based (OD-based) method for reward model training. This method generates high-quality preference pairs by systematically optimizing and degrading initial reasoning paths along curated dimensions of reasoning quality, such as factual accuracy, logical rigor, and coherence. A 7B parameter reward model with this method achieves state-of-the-art (SOTA) performance on LCB-RB and generalizes well to other benchmarks. Finally, we introduce Posterior-GRPO (P-GRPO), a novel RL method that conditions process-based rewards on task success. By selectively applying rewards to the reasoning processes of only successful outcomes, P-GRPO effectively mitigates reward hacking and aligns the model's internal reasoning with final code correctness. A 7B parameter model with P-GRPO achieves superior performance across diverse code generation tasks, outperforming outcome-only baselines by 4.5%, achieving comparable performance to GPT-4-Turbo. We further demonstrate the generalizability of our approach by extending it to mathematical tasks. Our models, dataset, and code are publicly available.