MedMKEB: A Comprehensive Knowledge Editing Benchmark for Medical Multimodal Large Language Models
作者: Dexuan Xu, Jieyi Wang, Zhongyan Chai, Yongzhi Cao, Hanpin Wang, Huamin Zhang, Yu Huang
分类: cs.AI
发布日期: 2025-08-07
备注: 18 pages
💡 一句话要点
提出MedMKEB:用于评估医学多模态大语言模型知识编辑的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学多模态 知识编辑 大语言模型 基准数据集 视觉问答
📋 核心要点
- 医学多模态大语言模型需要持续更新知识,但缺乏系统性的评估基准来衡量知识编辑的效果。
- MedMKEB基准通过构建包含反事实纠正、语义泛化等任务,评估模型知识编辑的多个维度。
- 实验表明现有知识编辑方法在医学领域存在局限性,需要专门的医学知识编辑策略。
📝 摘要(中文)
多模态大语言模型(MLLMs)的最新进展显著提升了医学人工智能,使其能够统一理解视觉和文本信息。然而,随着医学知识的不断发展,允许这些模型有效地更新过时或不正确的信息而不需从头开始重新训练至关重要。尽管文本知识编辑已被广泛研究,但仍然缺乏针对涉及图像和文本模态的医学多模态知识编辑的系统基准。为了填补这一空白,我们提出了MedMKEB,这是第一个旨在评估医学多模态大语言模型中知识编辑的可靠性、通用性、局部性、可移植性和鲁棒性的综合基准。MedMKEB建立在高质量的医学视觉问答数据集之上,并丰富了精心构建的编辑任务,包括反事实纠正、语义泛化、知识转移和对抗鲁棒性。我们纳入了人类专家验证,以确保基准的准确性和可靠性。在最先进的通用和医学MLLM上进行的大量单次编辑和顺序编辑实验表明,现有的基于知识的编辑方法在医学中存在局限性,突出了开发专门的编辑策略的必要性。MedMKEB将作为标准基准,以促进可信和高效的医学知识编辑算法的开发。
🔬 方法详解
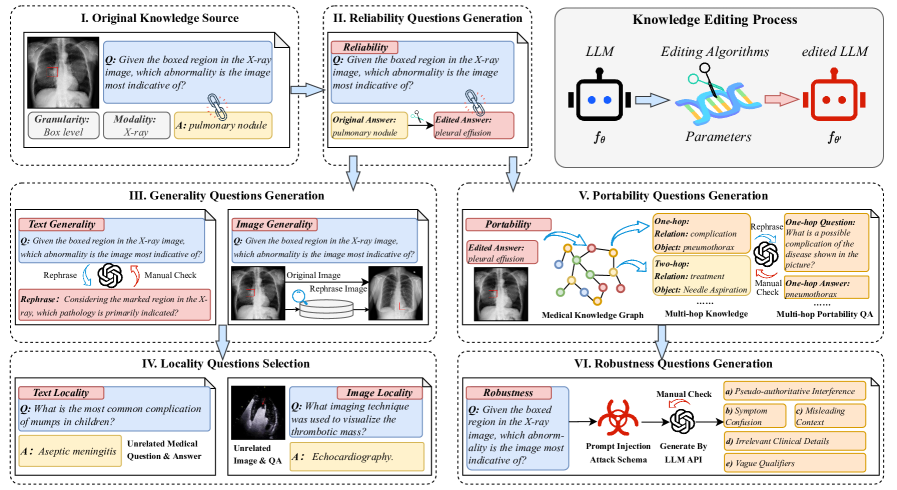
问题定义:论文旨在解决医学多模态大语言模型(MLLMs)知识更新的问题。现有的MLLMs在医学领域应用中,由于医学知识的快速发展,模型中可能存在过时或错误的知识。重新训练整个模型成本高昂,因此需要一种有效的方法来编辑模型中的知识。然而,目前缺乏针对医学多模态知识编辑的系统性评估基准,难以衡量不同知识编辑方法的优劣。
核心思路:论文的核心思路是构建一个综合性的基准数据集MedMKEB,用于评估医学MLLMs的知识编辑能力。该基准包含多种类型的编辑任务,旨在全面评估知识编辑的可靠性、通用性、局部性、可移植性和鲁棒性。通过在该基准上评估现有知识编辑方法,可以发现其在医学领域的局限性,并促进更有效的医学知识编辑算法的开发。
技术框架:MedMKEB基准的构建流程主要包括以下几个阶段:1) 基于高质量的医学视觉问答数据集,构建基础数据集。2) 设计并构建多种类型的知识编辑任务,包括反事实纠正、语义泛化、知识转移和对抗鲁棒性。3) 引入人类专家进行验证,确保基准的准确性和可靠性。4) 在现有的MLLMs上进行实验,评估其知识编辑能力。
关键创新:MedMKEB的主要创新在于它是第一个针对医学多模态知识编辑的综合性基准。它不仅考虑了文本模态的知识编辑,还考虑了图像模态的知识编辑,更贴合医学领域的实际应用场景。此外,MedMKEB还设计了多种类型的编辑任务,可以全面评估知识编辑的各个方面。
关键设计:MedMKEB的关键设计包括:1) 选择了高质量的医学视觉问答数据集作为基础,保证了数据的质量。2) 设计了四种类型的编辑任务,分别从不同角度评估知识编辑的能力。3) 引入了人类专家进行验证,确保了基准的准确性和可靠性。4) 采用了单次编辑和顺序编辑两种实验设置,更全面地评估知识编辑的效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的知识编辑方法在MedMKEB基准上表现出局限性,尤其是在医学领域。例如,在反事实纠正任务中,模型的准确率提升有限,表明现有方法难以有效地纠正模型中的错误知识。此外,顺序编辑实验表明,连续的知识编辑可能会导致模型性能下降,需要进一步研究如何提高知识编辑的稳定性和可靠性。
🎯 应用场景
该研究成果可应用于提升医学人工智能系统的可靠性和准确性,例如辅助诊断、医学影像分析和智能问诊等。通过知识编辑,可以及时更新医学模型中的知识,使其能够更好地适应医学领域的快速发展,从而为医生和患者提供更准确、更可靠的决策支持。
📄 摘要(原文)
Recent advances in multimodal large language models (MLLMs) have significantly improved medical AI, enabling it to unify the understanding of visual and textual information. However, as medical knowledge continues to evolve, it is critical to allow these models to efficiently update outdated or incorrect information without retraining from scratch. Although textual knowledge editing has been widely studied, there is still a lack of systematic benchmarks for multimodal medical knowledge editing involving image and text modalities. To fill this gap, we present MedMKEB, the first comprehensive benchmark designed to evaluate the reliability, generality, locality, portability, and robustness of knowledge editing in medical multimodal large language models. MedMKEB is built on a high-quality medical visual question-answering dataset and enriched with carefully constructed editing tasks, including counterfactual correction, semantic generalization, knowledge transfer, and adversarial robustness. We incorporate human expert validation to ensure the accuracy and reliability of the benchmark. Extensive single editing and sequential editing experiments on state-of-the-art general and medical MLLMs demonstrate the limitations of existing knowledge-based editing approaches in medicine, highlighting the need to develop specialized editing strategies. MedMKEB will serve as a standard benchmark to promote the development of trustworthy and efficient medical knowledge editing algorithms.