Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
作者: Huaicheng Zhang, Wei Tan, Guangzheng Li, Yixuan Zhang, Hangting Chen, Shun Lei, Chenyu Yang, Zhiyong Wu, Shuai Wang, Qijun Huang, Dong Yu
分类: cs.SD, cs.AI, eess.AS
发布日期: 2025-08-07
💡 一句话要点
提出基于强化学习偏好优化的框架,解决歌词到歌曲生成中的内容幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 歌词到歌曲生成 内容幻觉 强化学习 偏好优化 音素错误率
📋 核心要点
- 现有歌词到歌曲生成模型存在内容幻觉问题,生成内容与输入歌词不符,影响音乐连贯性。
- 提出基于强化学习的偏好优化框架,通过构建幻觉偏好数据集,优化模型生成与歌词对齐的音乐。
- 实验表明,该方法有效降低了音素错误率,抑制了幻觉,同时保持了音乐质量。
📝 摘要(中文)
本文提出了一种新的强化学习框架,该框架利用偏好优化来控制歌词到歌曲生成中的内容幻觉问题。现有基于音频的生成语言模型在歌词到歌曲生成中存在内容幻觉,即生成与输入歌词不符的内容,损害音乐连贯性。传统的监督微调方法受限于被动标签拟合,自我改进能力有限,难以有效缓解幻觉。为了解决这个问题,本文构建了一个基于音素错误率(PER)计算和规则过滤的幻觉偏好数据集,并在此基础上实现了三种不同的偏好优化策略:直接偏好优化(DPO)、近端策略优化(PPO)和组相对策略优化(GRPO)。实验结果表明,这些方法能够有效抑制幻觉,同时保持音乐质量。该框架具有迁移性,有望应用于音乐风格遵循和音乐性增强。
🔬 方法详解
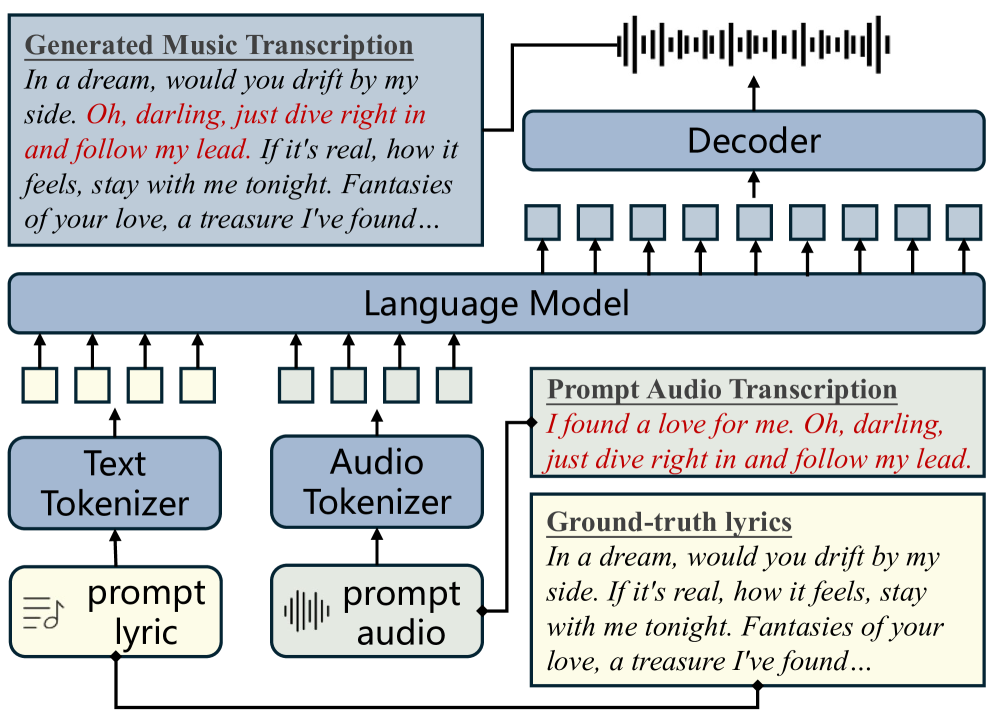
问题定义:论文旨在解决歌词到歌曲生成模型中普遍存在的“内容幻觉”问题。现有基于监督学习的微调方法,虽然可以学习歌词和音乐之间的对应关系,但由于其被动拟合标签的特性,难以有效抑制模型生成与歌词不一致的内容,即产生幻觉。这种幻觉会严重影响生成歌曲的质量和可信度。
核心思路:论文的核心思路是利用强化学习(RL)中的偏好优化方法,直接优化模型生成与歌词对齐的音乐的能力。通过构建一个能够反映人类对幻觉的偏好的数据集,并将其作为强化学习的奖励信号,引导模型学习生成更符合歌词内容的音乐。这样可以克服监督学习方法的局限性,实现更有效的幻觉控制。
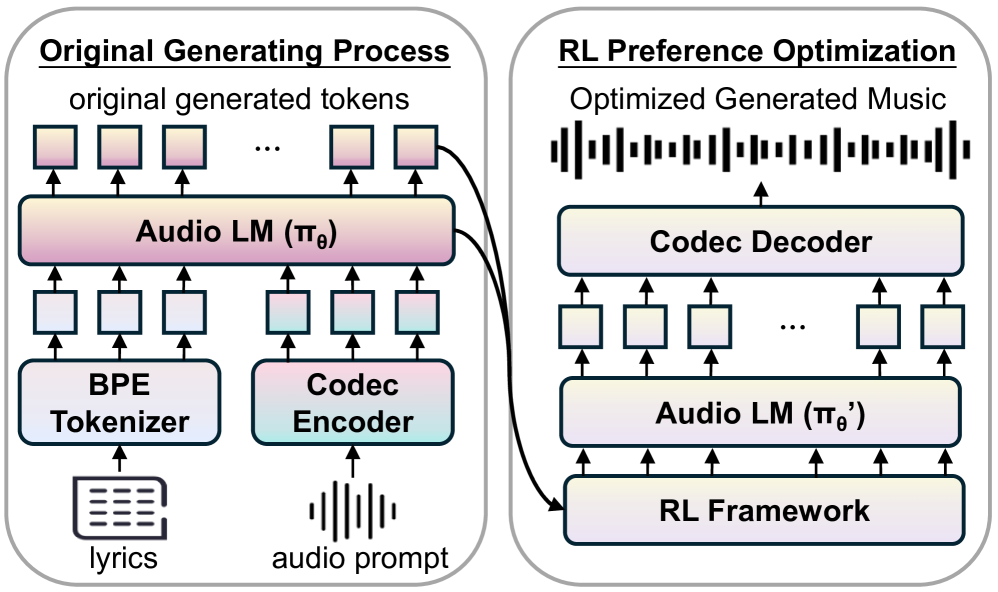
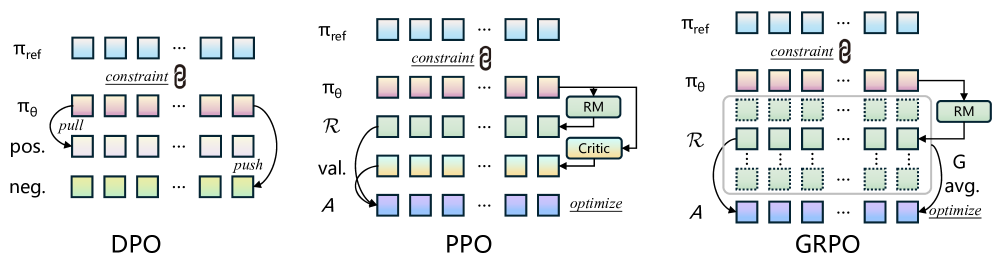
技术框架:整体框架包含以下几个主要步骤:1) 幻觉偏好数据集构建:利用音素错误率(PER)计算和规则过滤,构建一个包含正负样本的偏好数据集,用于训练奖励模型或直接优化生成模型。2) 偏好优化策略选择:选择三种不同的偏好优化策略,包括直接偏好优化(DPO)、近端策略优化(PPO)和组相对策略优化(GRPO)。3) 模型训练与评估:使用构建的偏好数据集和选择的优化策略,训练歌词到歌曲生成模型,并使用客观指标(如PER)和主观评价来评估模型的性能。
关键创新:最重要的技术创新点在于将强化学习中的偏好优化方法引入到歌词到歌曲生成任务中,并将其应用于幻觉控制。与传统的监督学习方法不同,该方法能够直接优化模型生成符合人类偏好的音乐的能力,从而更有效地抑制幻觉。此外,构建的基于PER的幻觉偏好数据集也是一个重要的贡献。
关键设计:1) 幻觉偏好数据集:使用音素错误率(PER)作为衡量幻觉程度的指标,PER越高,表示幻觉越严重。通过计算生成音乐的歌词与输入歌词之间的PER,并结合规则过滤,构建正负样本。2) 偏好优化策略:DPO采用离线策略,直接优化模型参数,使其更倾向于生成正样本。PPO和GRPO采用在线策略,训练一个基于PER的奖励模型,并使用该奖励模型来指导生成模型的训练。PPO使用KL散度正则化,防止策略过度更新。GRPO则通过组相对比较来优化策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于强化学习偏好优化的方法能够有效降低歌词到歌曲生成中的内容幻觉。DPO方法实现了7.4%的PER降低,PPO和GRPO方法分别实现了4.9%和4.7%的PER降低。主观评价也表明,该方法在抑制幻觉的同时,保持了音乐质量。这些结果证明了该方法在解决歌词到歌曲生成中的内容幻觉问题上的有效性。
🎯 应用场景
该研究成果可应用于AI音乐创作平台,提升歌曲生成的质量和可控性,减少内容错误。该技术还可扩展到其他文本到音频的生成任务,例如语音合成、音效生成等。未来,该框架有望应用于音乐风格迁移、个性化音乐推荐等领域,为音乐产业带来更多创新。
📄 摘要(原文)
Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.