Accurate and Consistent Graph Model Generation from Text with Large Language Models
作者: Boqi Chen, Ou Wei, Bingzhou Zheng, Gunter Mussbacher
分类: cs.SE, cs.AI
发布日期: 2025-08-01
备注: Accepted at ACM / IEEE 28th International Conference on Model Driven Engineering Languages and Systems (MODELS 2025)
💡 一句话要点
提出基于LLM的抽象-具体化框架,提升文本生成图模型的准确性和一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图模型生成 大型语言模型 抽象-具体化 自洽性 软件工程
📋 核心要点
- 现有基于LLM的图模型生成方法易出现语法错误、约束不一致和内容不准确等问题,后两者未被有效解决。
- 论文提出抽象-具体化框架,通过聚合LLM的多个输出来构建概率模型,再将其细化为满足约束的具体模型。
- 实验结果表明,该框架在多个LLM和数据集上显著提升了生成图模型的一致性和质量。
📝 摘要(中文)
本文研究了利用大型语言模型(LLM)从自然语言描述中生成图模型的问题。现有的基于LLM的方法通常会产生部分正确的模型,并存在三个主要问题:语法违规、约束不一致和不准确。虽然语法违规问题可以通过约束解码或过滤等技术解决,但后两个问题仍然没有得到充分解决。受LLM中自洽性方法的启发,本文提出了一种新颖的抽象-具体化框架,通过考虑LLM的多个输出来提高生成图模型的一致性和质量。该方法首先构建一个概率部分模型,聚合所有候选输出,然后将该部分模型细化为满足所有约束的最合适的具体模型。在多个用于模型生成任务的开源和闭源LLM以及数据集上评估了该框架。结果表明,该方法显著提高了生成图模型的一致性和质量。
🔬 方法详解
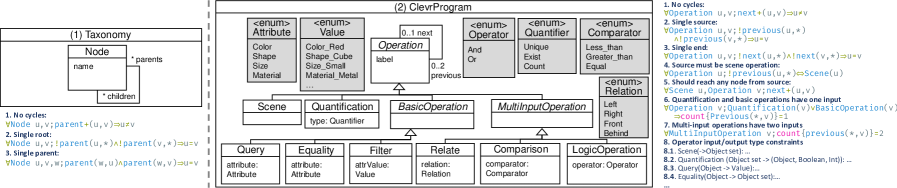
问题定义:论文旨在解决利用大型语言模型(LLM)从自然语言描述中生成准确且一致的图模型的问题。现有方法的主要痛点在于,生成的图模型常常存在语法错误(不符合元模型定义)、约束不一致(不满足领域特定约束)以及内容不准确(包含幻觉元素)等问题,尤其后两者难以解决。
核心思路:论文的核心思路是借鉴LLM中的自洽性方法,通过生成多个候选图模型,并从中提取共性信息,构建一个概率性的抽象模型,然后将该抽象模型细化为一个满足所有约束的具体模型。这种方法旨在利用多个输出的冗余信息来减少幻觉,并提高模型的一致性和准确性。
技术框架:整体框架包含两个主要阶段:抽象阶段和具体化阶段。在抽象阶段,首先使用LLM生成多个候选图模型。然后,将这些候选模型进行聚合,构建一个概率性的部分模型,该模型表示了各个元素和关系的置信度。在具体化阶段,利用约束求解器或优化算法,将该部分模型细化为一个具体的、满足所有约束的图模型。
关键创新:最重要的技术创新点在于提出了抽象-具体化框架,该框架能够有效地利用LLM的多个输出来提高生成图模型的一致性和质量。与现有方法相比,该框架不仅关注语法正确性,还着重解决了约束不一致和内容不准确的问题。
关键设计:关键设计包括如何定义和构建概率性的部分模型,以及如何选择合适的约束求解器或优化算法来进行具体化。部分模型的构建可能涉及到对不同候选模型中的节点、边和属性进行加权平均或投票。具体化过程可能需要定义一个目标函数,该函数衡量生成模型与部分模型的相似度,并同时满足所有约束。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个开源和闭源LLM以及数据集上都取得了显著的性能提升。具体而言,该方法在生成图模型的准确性和一致性方面均优于现有的基线方法,并且能够有效地减少幻觉元素的出现。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于软件工程领域,例如从需求文档自动生成软件架构模型、从用户故事生成用例图等。这可以提高软件开发的效率和质量,并降低开发成本。此外,该方法还可以应用于知识图谱构建、数据建模等领域,具有广泛的应用前景。
📄 摘要(原文)
Graph model generation from natural language description is an important task with many applications in software engineering. With the rise of large language models (LLMs), there is a growing interest in using LLMs for graph model generation. Nevertheless, LLM-based graph model generation typically produces partially correct models that suffer from three main issues: (1) syntax violations: the generated model may not adhere to the syntax defined by its metamodel, (2) constraint inconsistencies: the structure of the model might not conform to some domain-specific constraints, and (3) inaccuracy: due to the inherent uncertainty in LLMs, the models can include inaccurate, hallucinated elements. While the first issue is often addressed through techniques such as constraint decoding or filtering, the latter two remain largely unaddressed. Motivated by recent self-consistency approaches in LLMs, we propose a novel abstraction-concretization framework that enhances the consistency and quality of generated graph models by considering multiple outputs from an LLM. Our approach first constructs a probabilistic partial model that aggregates all candidate outputs and then refines this partial model into the most appropriate concrete model that satisfies all constraints. We evaluate our framework on several popular open-source and closed-source LLMs using diverse datasets for model generation tasks. The results demonstrate that our approach significantly improves both the consistency and quality of the generated graph models.