RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
作者: Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, Ge Li
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-07-31 (更新: 2025-10-19)
💡 一句话要点
RL-PLUS:混合策略优化解决LLM在强化学习中能力边界崩溃问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 策略优化 重要性采样 优势函数
📋 核心要点
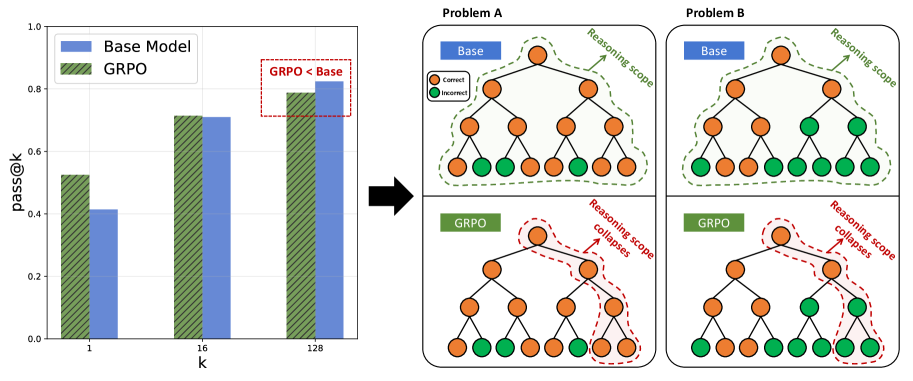
- 现有基于可验证奖励的强化学习方法难以突破LLM自身能力边界,且易导致能力边界崩溃,限制了LLM的推理范围。
- RL-PLUS采用混合策略优化,结合内部探索和外部数据,利用多重重要性采样和基于探索的优势函数,引导模型探索更优推理路径。
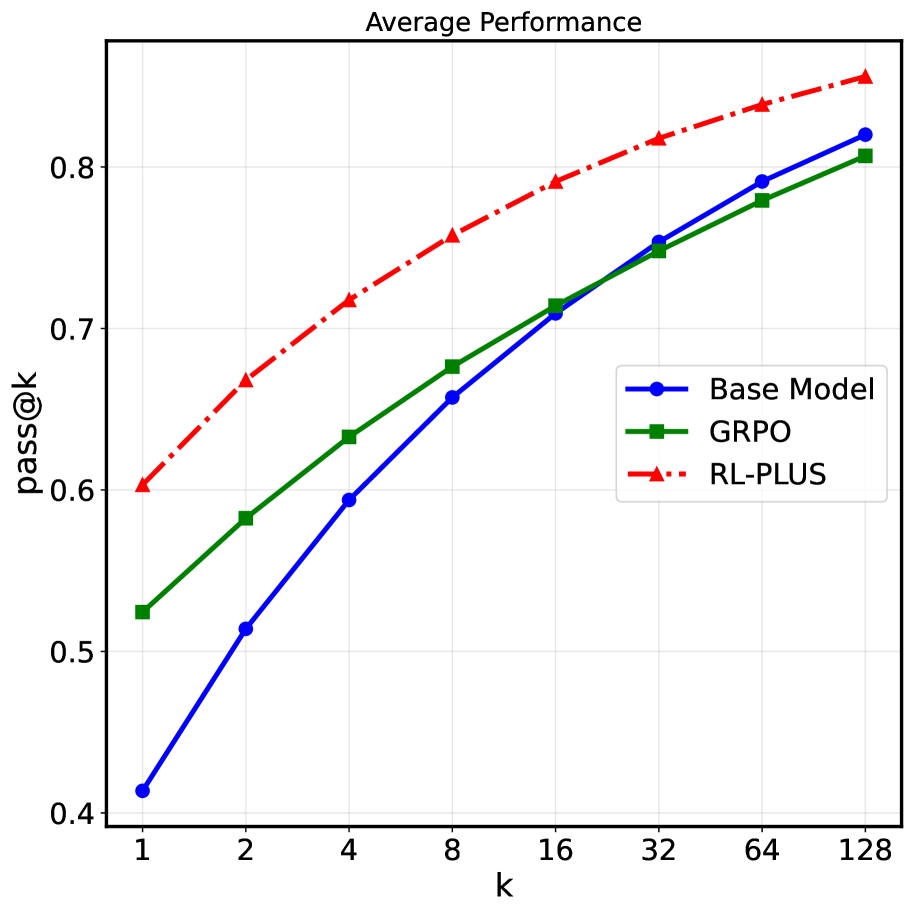
- 实验表明,RL-PLUS在多个数学推理和分布外推理任务上超越现有方法,并在不同模型上取得显著提升,有效缓解能力边界崩溃。
📝 摘要(中文)
本文提出RL-PLUS,一种针对LLM的混合策略优化方法,旨在解决基于可验证奖励的强化学习(RLVR)方法中LLM能力边界崩溃的问题。RLVR虽然提升了LLM的复杂推理能力,但由于其本质上的on-policy策略、LLM巨大的动作空间和稀疏奖励,难以突破LLM固有的能力边界,甚至导致能力边界崩溃,缩小LLM解决问题的范围。RL-PLUS通过结合内部探索和外部数据,实现更强的推理能力并超越基础模型的能力边界。它包含两个核心组件:多重重要性采样,用于解决来自外部数据分布不匹配的问题;以及基于探索的优势函数,引导模型探索高价值、未知的推理路径。理论分析和大量实验证明了该方法的优越性和泛化性。相比现有RLVR方法,RL-PLUS在六个数学推理基准上实现了最先进的性能,在六个分布外推理任务上表现出色,并在不同的模型系列中取得了持续且显著的收益,平均相对改进高达69.2%。Pass@k曲线分析表明,RL-PLUS有效解决了能力边界崩溃问题。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在强化学习(RL)中,特别是使用可验证奖励的强化学习(RLVR)时,出现的能力边界崩溃问题。现有RLVR方法虽然能提升LLM的推理能力,但由于其on-policy特性、巨大的动作空间和稀疏奖励,难以突破LLM本身的能力限制,反而可能使LLM的能力范围变得更窄。
核心思路:RL-PLUS的核心思路是结合内部探索和外部数据,通过混合策略优化来提升LLM的推理能力,并超越其初始能力边界。它认为,仅仅依赖LLM自身的策略进行探索是不够的,需要引入外部数据来扩展探索空间,同时需要有效的机制来平衡内部探索和外部数据的利用。
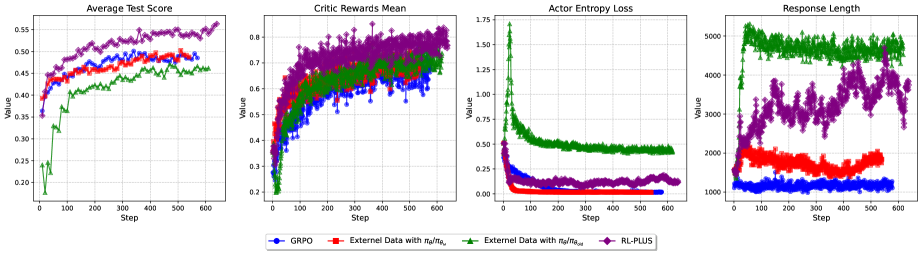
技术框架:RL-PLUS的技术框架主要包含两个核心组件:1) 多重重要性采样(Multiple Importance Sampling):用于解决外部数据与当前策略分布不匹配的问题,从而更有效地利用外部数据。2) 基于探索的优势函数(Exploration-Based Advantage Function):用于引导模型探索高价值但未知的推理路径,鼓励模型跳出局部最优,发现更优的解决方案。整体流程是,首先利用外部数据进行预训练或微调,然后使用RL-PLUS进行强化学习,不断优化策略。
关键创新:RL-PLUS的关键创新在于其混合策略优化方法,它将内部探索(通过优势函数引导)和外部数据利用(通过多重重要性采样)相结合,从而克服了传统RLVR方法的局限性。与现有方法相比,RL-PLUS能够更有效地利用外部数据,并引导模型探索更广阔的解空间。
关键设计:多重重要性采样通过计算不同数据源的重要性权重,来校正分布差异。基于探索的优势函数则在传统优势函数的基础上,引入了探索奖励,鼓励模型尝试新的动作。具体的优势函数形式可能包含一个与访问频率相关的项,例如,访问次数越少的动作,其优势值越高。损失函数通常是策略梯度损失,并结合重要性采样权重进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RL-PLUS在六个数学推理基准上取得了最先进的性能,并在六个分布外推理任务上表现出优越的泛化能力。与现有RLVR方法相比,RL-PLUS在不同模型系列中实现了持续且显著的性能提升,平均相对改进高达69.2%。Pass@k曲线分析进一步证实,RL-PLUS有效解决了能力边界崩溃问题,显著提升了LLM解决问题的成功率。
🎯 应用场景
RL-PLUS具有广泛的应用前景,可应用于各种需要复杂推理和决策的任务中,例如数学问题求解、代码生成、游戏AI等。该方法能够提升LLM在这些任务中的性能和泛化能力,使其能够解决更复杂、更具挑战性的问题。未来,RL-PLUS有望推动LLM在实际应用中的更广泛应用,例如智能客服、自动化编程、科学研究等。
📄 摘要(原文)
Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its essentially on-policy strategy coupled with LLM's immense action space and sparse reward. Critically, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel hybrid-policy optimization approach for LLMs that synergizes internal exploitation with external data to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components, i.e., Multiple Importance Sampling to address distributional mismatch from external data, and Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. Compared with existing RLVR methods, RL-PLUS achieves 1) state-of-the-art performance on six math reasoning benchmarks; 2) superior performance on six out-of-distribution reasoning tasks; 3) consistent and significant gains across diverse model families, with average relative improvements up to 69.2\%. Moreover, the analysis of Pass@k curves indicates that RL-PLUS effectively resolves the capability boundary collapse problem.