Open-Source Agentic Hybrid RAG Framework for Scientific Literature Review
作者: Aditya Nagori, Ricardo Accorsi Casonatto, Ayush Gautam, Abhinav Manikantha Sai Cheruvu, Rishikesan Kamaleswaran
分类: cs.IR, cs.AI
发布日期: 2025-07-30
💡 一句话要点
提出Agentic混合RAG框架,用于动态、可信的科学文献综述
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Agentic RAG 科学文献综述 知识图谱 向量检索 指令调优
📋 核心要点
- 传统科学文献综述方法难以应对海量文献,缺乏有效整合元数据和全文分析的工具。
- 提出Agentic混合RAG框架,通过自主agent动态选择GraphRAG或VectorRAG,并实时调整生成策略。
- 在合成基准测试中,该框架显著提升了上下文召回率、精确度和忠实度,验证了其有效性。
📝 摘要(中文)
科学出版物的激增对传统综述方法提出了挑战,需要能够整合结构化元数据与全文分析的工具。混合检索增强生成(RAG)系统,结合图查询与向量搜索,展现了潜力,但通常是静态的,依赖专有工具,并且缺乏不确定性估计。本文提出了一种agentic方法,将混合RAG流程封装在一个自主agent中,该agent能够:(1)为每个查询动态选择GraphRAG和VectorRAG;(2)实时调整指令调优生成以满足研究人员的需求;(3)量化推理过程中的不确定性。这种动态编排提高了相关性,减少了幻觉,并促进了可重复性。
🔬 方法详解
问题定义:现有科学文献综述方法面临信息过载的挑战,难以有效整合结构化元数据(如引用关系)和非结构化全文信息。传统的RAG系统通常是静态的,无法根据查询动态选择合适的检索策略,并且缺乏对生成结果不确定性的评估,容易产生幻觉。
核心思路:本文的核心思路是构建一个自主agent,该agent能够根据用户查询的特点,动态选择GraphRAG(基于知识图谱的检索)或VectorRAG(基于向量相似度的检索),并利用指令调优技术实时调整生成策略,同时量化生成结果的不确定性。这种动态选择和实时调整的机制旨在提高检索的相关性、减少幻觉,并提升结果的可信度。
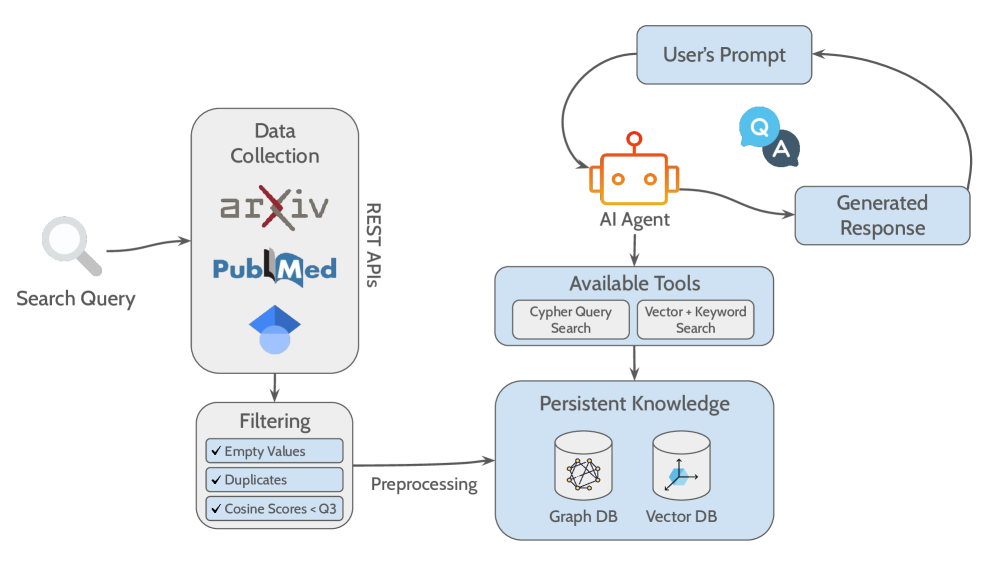
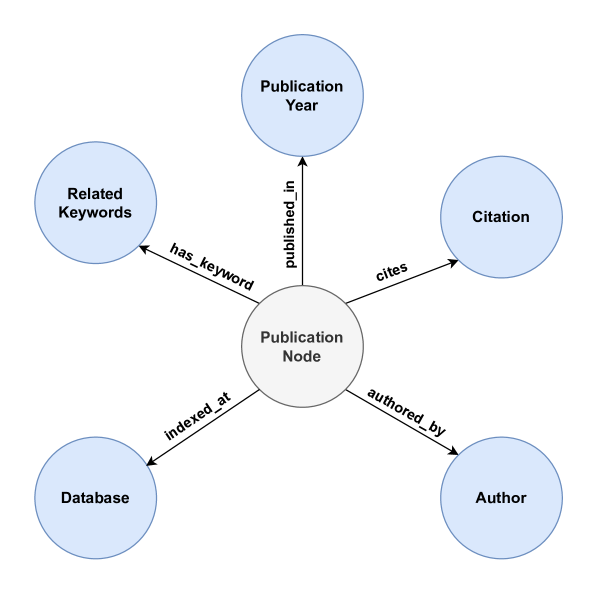
技术框架:该框架包含以下主要模块:1) 数据摄取模块:从PubMed、arXiv和Google Scholar API获取开放获取的文献数据。2) 知识图谱构建模块:利用Neo4j构建基于引用关系的知识图谱。3) 向量存储模块:使用all-MiniLM-L6-v2模型将全文PDF嵌入到FAISS向量存储中。4) Agent模块:基于Llama-3.3-70B,负责动态选择GraphRAG或VectorRAG,并进行指令调优生成。5) 评估模块:通过bootstrap方法量化评估指标的标准差,提供不确定性估计。
关键创新:最重要的技术创新点在于将混合RAG流程封装在一个自主agent中,该agent能够动态选择检索策略并实时调整生成策略。与传统的静态RAG系统相比,该方法能够更好地适应不同类型的查询,并提供更准确、更可信的答案。
关键设计:Agent模块使用Llama-3.3-70B模型,并通过指令调优(Instruction Tuning)来优化其在科学文献综述任务中的表现。使用直接偏好优化(Direct Preference Optimization, DPO)来进一步提升生成质量。评估模块采用bootstrap方法,通过多次重采样来估计评估指标的标准差,从而量化结果的不确定性。
🖼️ 关键图片

📊 实验亮点
在合成基准测试中,经过指令调优的Agent在向量搜索上下文召回率上提升了0.63,整体上下文精确度提升了0.56。此外,在向量搜索忠实度、精确度以及知识图谱答案相关性等方面均有显著提升,表明该系统在异构数据源上的推理能力得到了有效增强。
🎯 应用场景
该研究成果可应用于自动化科学文献综述、科研辅助、智能问答系统等领域。通过提高文献检索的效率和准确性,可以帮助研究人员更快地发现相关信息,促进科学研究的进展。该框架具有可扩展性,可以应用于其他领域的知识发现和信息检索。
📄 摘要(原文)
The surge in scientific publications challenges traditional review methods, demanding tools that integrate structured metadata with full-text analysis. Hybrid Retrieval Augmented Generation (RAG) systems, combining graph queries with vector search offer promise but are typically static, rely on proprietary tools, and lack uncertainty estimates. We present an agentic approach that encapsulates the hybrid RAG pipeline within an autonomous agent capable of (1) dynamically selecting between GraphRAG and VectorRAG for each query, (2) adapting instruction-tuned generation in real time to researcher needs, and (3) quantifying uncertainty during inference. This dynamic orchestration improves relevance, reduces hallucinations, and promotes reproducibility. Our pipeline ingests bibliometric open-access data from PubMed, arXiv, and Google Scholar APIs, builds a Neo4j citation-based knowledge graph (KG), and embeds full-text PDFs into a FAISS vector store (VS) using the all-MiniLM-L6-v2 model. A Llama-3.3-70B agent selects GraphRAG (translating queries to Cypher for KG) or VectorRAG (combining sparse and dense retrieval with re-ranking). Instruction tuning refines domain-specific generation, and bootstrapped evaluation yields standard deviation for evaluation metrics. On synthetic benchmarks mimicking real-world queries, the Instruction-Tuned Agent with Direct Preference Optimization (DPO) outperforms the baseline, achieving a gain of 0.63 in VS Context Recall and a 0.56 gain in overall Context Precision. Additional gains include 0.24 in VS Faithfulness, 0.12 in both VS Precision and KG Answer Relevance, 0.11 in overall Faithfulness score, 0.05 in KG Context Recall, and 0.04 in both VS Answer Relevance and overall Precision. These results highlight the system's improved reasoning over heterogeneous sources and establish a scalable framework for autonomous, agentic scientific discovery.