GPT-4.1 Sets the Standard in Automated Experiment Design Using Novel Python Libraries
作者: Nuno Fachada, Daniel Fernandes, Carlos M. Fernandes, Bruno D. Ferreira-Saraiva, João P. Matos-Carvalho
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-07-30 (更新: 2025-09-15)
备注: The peer-reviewed version of this paper is published in Future Internet at https://doi.org/10.3390/fi17090412. This version is typeset by the author and differs only in pagination and typographical detail
期刊: Future Internet. 2025; 17(9):412
DOI: 10.3390/fi17090412
💡 一句话要点
GPT-4.1在自动化实验设计中表现卓越,基于新型Python库实现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动化实验设计 代码生成 零样本学习 Python库 科学计算 GPT-4.1
📋 核心要点
- 现有大型语言模型在科学计算自动化中应用受限,难以有效利用不熟悉的Python库API。
- 该研究通过零样本提示,评估LLM在会话数据分析和合成数据生成聚类任务中的代码生成能力。
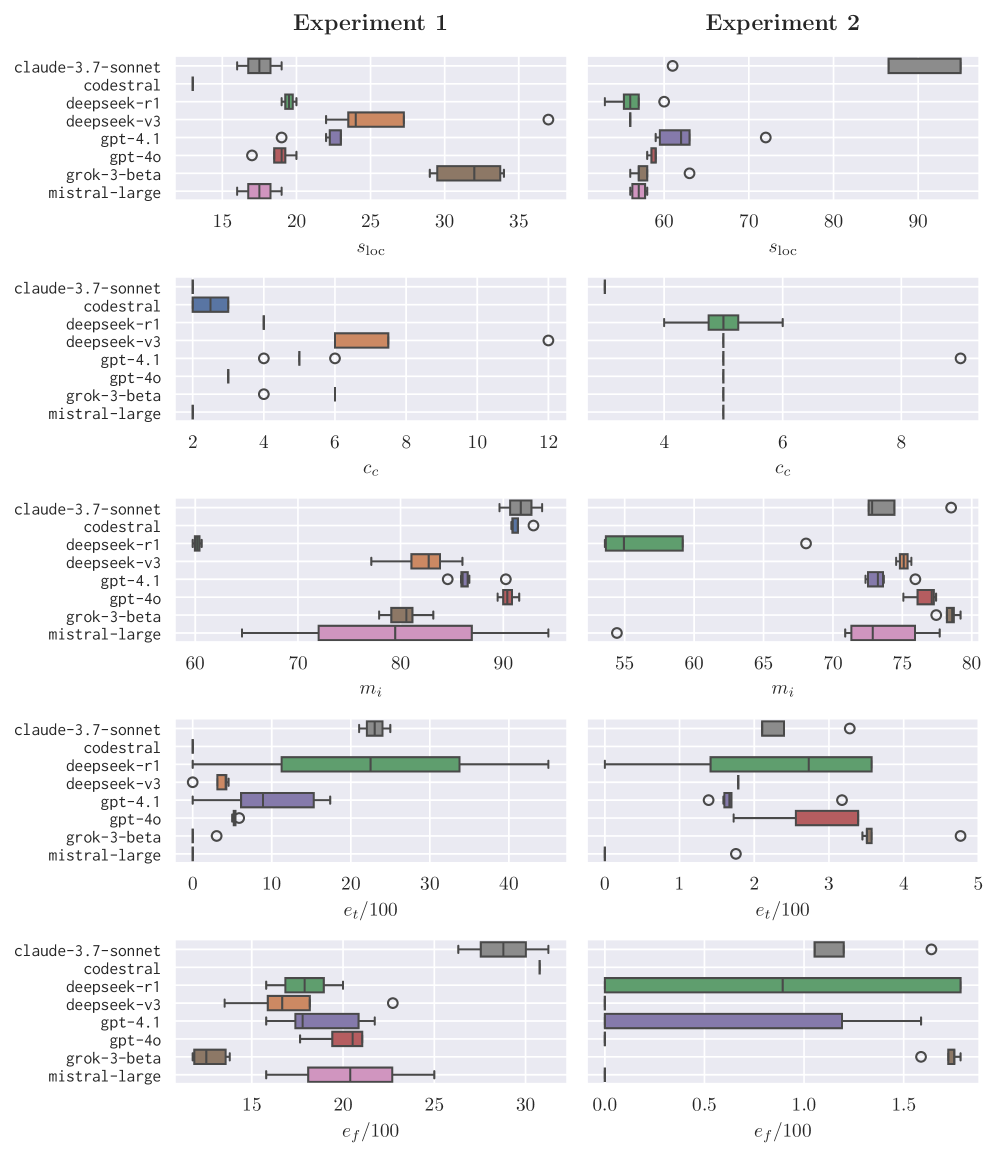
- 实验表明,GPT-4.1在所有测试中均达到100%成功率,显著优于其他模型,并揭示了第三方库的潜在问题。
📝 摘要(中文)
大型语言模型(LLMs)作为科学研究中自动化代码生成的工具发展迅速,但它们解释和使用不熟悉的Python API进行复杂计算实验的能力仍然缺乏充分的表征。本研究系统地评估了一系列最先进的LLM在生成功能性Python代码方面的能力,针对两个难度递增的场景:使用 extit{ParShift}库进行会话数据分析,以及使用 extit{pyclugen}和 extit{scikit-learn}进行合成数据生成和聚类。两个实验都使用了结构化的、零样本提示,指定了详细的要求,但省略了上下文示例。通过多次运行,对模型输出的功能正确性和提示依从性进行定量评估,并通过分析代码执行失败时产生的错误进行定性评估。结果表明,只有一小部分模型能够持续生成正确、可执行的代码。GPT-4.1在所有实验任务的所有运行中都达到了100%的成功率,而大多数其他模型的成功率低于一半,只有Grok-3和Mistral-Large接近可比的性能。除了评估LLM的性能之外,这种方法还有助于识别第三方库中的缺点,例如不清晰的文档或晦涩的实现错误。总的来说,这些发现突出了LLM在端到端科学自动化方面的当前局限性,并强调了仔细的提示设计、全面的库文档以及语言模型能力的持续进步的必要性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在自动化科学实验设计中的能力,特别是它们能否理解并使用不熟悉的Python库API生成可执行的代码。现有方法依赖人工编写代码,效率低下且容易出错。LLMs虽然在代码生成方面取得了进展,但其在复杂科学计算任务中的表现仍需深入研究。现有LLMs在处理需要特定领域知识和复杂API调用的任务时,往往难以保证代码的正确性和可靠性。
核心思路:论文的核心思路是通过设计结构化的零样本提示,引导LLMs生成用于特定科学计算任务的Python代码。通过省略上下文示例,测试LLMs独立理解和应用API文档的能力。同时,通过定量评估代码的正确性和提示依从性,以及定性分析错误类型,全面评估LLMs的性能。这种方法旨在揭示LLMs在科学自动化方面的优势和局限性,并为未来的研究提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择两个具有代表性的科学计算任务:会话数据分析(使用ParShift库)和合成数据生成与聚类(使用pyclugen和scikit-learn库)。2) 为每个任务设计结构化的零样本提示,详细描述任务要求和API调用方式。3) 使用多个最先进的LLMs(包括GPT-4.1、Grok-3、Mistral-Large等)生成Python代码。4) 对生成的代码进行功能正确性和提示依从性的定量评估,以及错误类型的定性分析。5) 对实验结果进行统计分析和比较,评估不同LLMs的性能,并识别第三方库的潜在问题。
关键创新:该研究的关键创新在于:1) 系统地评估了LLMs在自动化科学实验设计中的能力,填补了该领域的研究空白。2) 采用结构化的零样本提示,有效测试了LLMs独立理解和应用API文档的能力。3) 通过定量和定性分析相结合的方法,全面评估了LLMs的性能,并识别了第三方库的潜在问题。4) 揭示了GPT-4.1在科学自动化方面的卓越性能,为未来的研究提供了有价值的参考。
关键设计:实验的关键设计包括:1) 任务选择:选择具有代表性的科学计算任务,涵盖数据分析和机器学习领域。2) 提示设计:设计结构化的零样本提示,详细描述任务要求和API调用方式,避免歧义。3) 模型选择:选择多个最先进的LLMs,进行性能比较。4) 评估指标:采用功能正确性和提示依从性作为定量评估指标,以及错误类型分析作为定性评估方法。5) 多次运行:对每个任务进行多次运行,以确保结果的可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-4.1在所有实验任务的所有运行中都达到了100%的成功率,显著优于其他模型。Grok-3和Mistral-Large的性能接近GPT-4.1,但仍有差距。大多数其他模型的成功率低于一半。此外,该研究还识别了第三方库ParShift、pyclugen和scikit-learn中存在的潜在问题,例如不清晰的文档或晦涩的实现错误。
🎯 应用场景
该研究成果可应用于自动化科学实验设计、代码生成、数据分析和机器学习等领域。通过利用LLMs自动生成代码,可以显著提高科研效率,降低人工成本。此外,该研究还有助于发现第三方库的潜在问题,促进软件质量的提升。未来,该研究可进一步扩展到更复杂的科学计算任务,推动科学研究的自动化和智能化。
📄 摘要(原文)
Large Language Models (LLMs) have advanced rapidly as tools for automating code generation in scientific research, yet their ability to interpret and use unfamiliar Python APIs for complex computational experiments remains poorly characterized. This study systematically benchmarks a selection of state-of-the-art LLMs in generating functional Python code for two increasingly challenging scenarios: conversational data analysis with the \textit{ParShift} library, and synthetic data generation and clustering using \textit{pyclugen} and \textit{scikit-learn}. Both experiments use structured, zero-shot prompts specifying detailed requirements but omitting in-context examples. Model outputs are evaluated quantitatively for functional correctness and prompt compliance over multiple runs, and qualitatively by analyzing the errors produced when code execution fails. Results show that only a small subset of models consistently generate correct, executable code. GPT-4.1 achieved a 100\% success rate across all runs in both experimental tasks, whereas most other models succeeded in fewer than half of the runs, with only Grok-3 and Mistral-Large approaching comparable performance. In addition to benchmarking LLM performance, this approach helps identify shortcomings in third-party libraries, such as unclear documentation or obscure implementation bugs. Overall, these findings highlight current limitations of LLMs for end-to-end scientific automation and emphasize the need for careful prompt design, comprehensive library documentation, and continued advances in language model capabilities.