Data Readiness for Scientific AI at Scale
作者: Wesley Brewer, Patrick Widener, Valentine Anantharaj, Feiyi Wang, Tom Beck, Arjun Shankar, Sarp Oral
分类: cs.AI, cs.CE, cs.DC, cs.LG
发布日期: 2025-07-30
备注: 10 pages, 1 figure, 2 tables
💡 一句话要点
提出数据就绪度框架,加速领导级科学数据集上AI基础模型的训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据就绪度 科学AI 基础模型 高性能计算 数据预处理 数据治理 Transformer模型
📋 核心要点
- 现有科学数据预处理缺乏统一标准,阻碍了AI模型在不同领域的可复用性和可扩展性。
- 论文提出一个二维数据就绪度框架,包含数据就绪度级别和数据处理阶段,用于评估和指导科学数据的AI化。
- 该框架通过分析四个代表性领域,识别共性预处理模式和领域约束,旨在促进跨领域AI模型的训练。
📝 摘要(中文)
本文探讨了AI数据就绪度(DRAI)原则如何应用于领导级科学数据集,这些数据集用于训练基础模型。我们分析了气候、核聚变、生物/健康和材料四个代表性领域的典型工作流程,以识别常见的预处理模式和特定领域的约束。我们引入了一个二维就绪度框架,该框架由数据就绪度级别(从原始到AI就绪)和数据处理阶段(从摄取到分片)组成,两者都针对高性能计算(HPC)环境量身定制。该框架概述了将科学数据转换为可扩展AI训练的关键挑战,重点是基于Transformer的生成模型。总之,这些维度构成了一个概念成熟度矩阵,用于表征科学数据的就绪度,并指导基础设施开发,以实现对科学领域可扩展和可重复AI的标准化、跨领域支持。
🔬 方法详解
问题定义:论文旨在解决科学领域中,大规模数据集在用于AI训练时面临的数据准备问题。现有方法缺乏统一的标准和流程,导致数据预处理工作繁琐、耗时,并且难以在不同领域之间复用。这阻碍了AI技术在科学研究中的广泛应用,尤其是在需要训练大型基础模型时。
核心思路:论文的核心思路是建立一个数据就绪度框架,该框架能够系统地评估科学数据的质量和适用性,并指导数据预处理流程。通过将数据处理过程分解为不同的阶段,并定义每个阶段的目标和要求,该框架可以帮助研究人员更好地理解和管理数据,从而提高AI模型的训练效率和效果。
技术框架:该框架包含两个主要维度:数据就绪度级别(Data Readiness Levels, DRL)和数据处理阶段(Data Processing Stages, DPS)。DRL描述了数据从原始状态到AI就绪状态的演变过程,DPS则描述了数据处理的各个阶段,例如数据摄取、清洗、转换和分片。通过将这两个维度结合起来,可以形成一个概念成熟度矩阵,用于评估数据的整体就绪度。
关键创新:该框架的关键创新在于它提供了一个统一的、可扩展的、跨领域的科学数据AI化方法。它不仅关注数据的质量,还关注数据处理流程的效率和可重复性。此外,该框架还特别强调了对高性能计算(HPC)环境的支持,这对于处理大规模科学数据集至关重要。
关键设计:数据就绪度级别(DRL)定义了数据从原始状态到AI就绪状态的演变过程,例如,原始数据、清洗后的数据、特征工程后的数据、以及最终用于AI模型训练的数据。数据处理阶段(DPS)则定义了数据处理的各个阶段,例如,数据摄取、清洗、转换、增强和分片。框架还考虑了不同科学领域的特定约束和需求,例如,气候数据的时空相关性、核聚变数据的复杂物理模型等。框架目标是为transformer模型训练提供数据支持。
🖼️ 关键图片
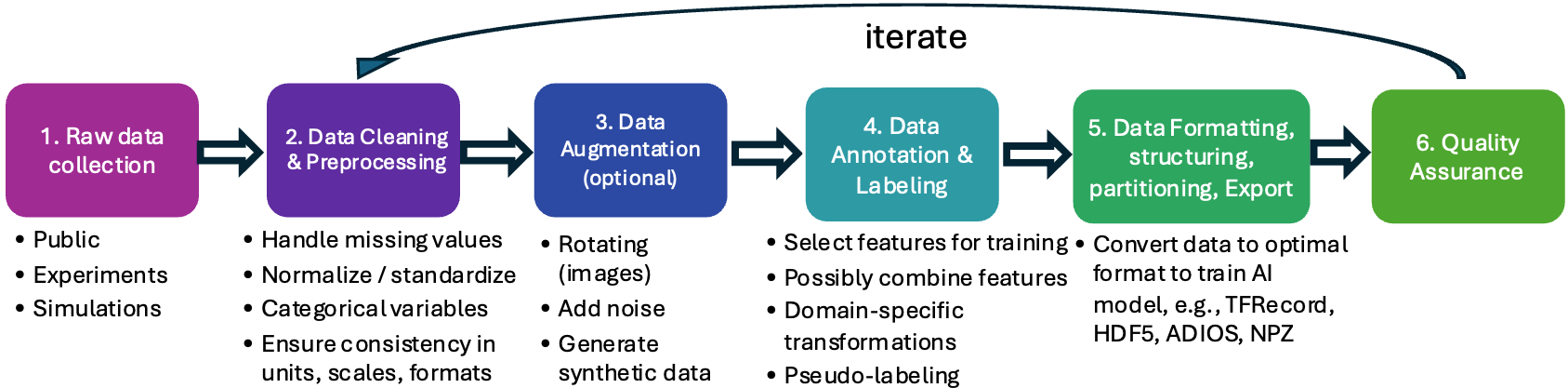
📊 实验亮点
论文通过分析四个代表性领域的实际案例,验证了该框架的有效性。虽然没有给出具体的性能数据,但论文强调了该框架能够帮助研究人员更好地理解和管理数据,从而提高AI模型的训练效率和效果。该框架为科学数据AI化提供了一个有价值的指导。
🎯 应用场景
该研究成果可广泛应用于气候科学、核聚变研究、生物医药和材料科学等领域。通过提高科学数据的AI就绪度,可以加速AI模型在这些领域的应用,例如气候变化预测、新材料发现、药物研发等,从而推动科学研究的进步。
📄 摘要(原文)
This paper examines how Data Readiness for AI (DRAI) principles apply to leadership-scale scientific datasets used to train foundation models. We analyze archetypal workflows across four representative domains - climate, nuclear fusion, bio/health, and materials - to identify common preprocessing patterns and domain-specific constraints. We introduce a two-dimensional readiness framework composed of Data Readiness Levels (raw to AI-ready) and Data Processing Stages (ingest to shard), both tailored to high performance computing (HPC) environments. This framework outlines key challenges in transforming scientific data for scalable AI training, emphasizing transformer-based generative models. Together, these dimensions form a conceptual maturity matrix that characterizes scientific data readiness and guides infrastructure development toward standardized, cross-domain support for scalable and reproducible AI for science.