Empirical Evaluation of Concept Drift in ML-Based Android Malware Detection
作者: Ahmed Sabbah, Radi Jarrar, Samer Zein, David Mohaisen
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-07-30
备注: 18 pages, 12 tables, 14 figures, paper under review
💡 一句话要点
评估机器学习Android恶意软件检测中概念漂移的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Android恶意软件检测 概念漂移 机器学习 深度学习 大型语言模型 实证研究 特征工程
📋 核心要点
- 现有基于机器学习的恶意软件检测模型在面对恶意软件快速演变时,性能会因概念漂移而下降。
- 本研究通过评估不同特征、算法和数据环境,深入分析概念漂移对Android恶意软件检测的影响。
- 实验结果表明概念漂移普遍存在且显著影响模型性能,并发现特征类型和数据环境是主要影响因素。
📝 摘要(中文)
基于机器学习的Android恶意软件检测模型虽然取得了显著成果,但仍面临概念漂移的挑战,即快速演变的恶意软件特征会降低模型的有效性。本研究考察了概念漂移对Android恶意软件检测的影响,评估了两个数据集和九种机器学习与深度学习算法,以及大型语言模型(LLM)。研究考虑了各种特征类型——静态、动态、混合、语义和基于图像的特征。结果表明,概念漂移普遍存在,并显著影响模型性能。影响漂移的因素包括特征类型、数据环境和检测方法。平衡算法有助于解决类别不平衡问题,但不能完全解决概念漂移,概念漂移主要源于恶意软件环境的动态性。算法类型与概念漂移之间没有发现很强的联系,与其他变量相比,其影响相对较小,因为超参数没有进行微调,并且使用了默认的算法配置。虽然使用少量样本学习的LLM表现出良好的检测性能,但它们并没有完全缓解概念漂移,这突出了进一步研究的必要性。
🔬 方法详解
问题定义:论文旨在解决Android恶意软件检测中,由于恶意软件的快速演化导致模型性能下降的问题,即概念漂移问题。现有方法难以适应恶意软件的动态变化,导致检测准确率降低。
核心思路:论文的核心思路是通过实证研究,评估不同类型的特征、机器学习/深度学习算法以及大型语言模型在面对概念漂移时的表现。通过分析不同因素对模型性能的影响,从而更好地理解和应对概念漂移。
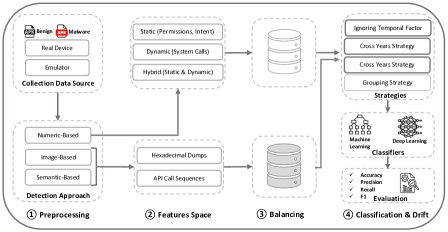
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集与预处理:收集Android恶意软件和良性应用的数据集,提取静态、动态、混合、语义和图像特征。2) 模型训练与评估:使用九种机器学习和深度学习算法以及大型语言模型进行训练,并在不同时间段的数据上进行评估。3) 概念漂移分析:分析模型在不同时间段的性能变化,评估概念漂移的影响程度。4) 因素分析:分析特征类型、数据环境和检测方法等因素对概念漂移的影响。
关键创新:该研究的关键创新在于对Android恶意软件检测中的概念漂移进行了全面的实证评估,并分析了多种因素的影响。此外,该研究还评估了大型语言模型在缓解概念漂移方面的潜力。
关键设计:研究中使用了多种特征类型,包括静态特征(如权限、API调用)、动态特征(如运行时行为)、混合特征、语义特征和图像特征。使用了九种机器学习和深度学习算法,包括传统算法(如SVM、决策树)和深度学习模型(如CNN、RNN)。大型语言模型使用了少量样本学习的方法。超参数使用了默认配置,没有进行微调。
🖼️ 关键图片
📊 实验亮点
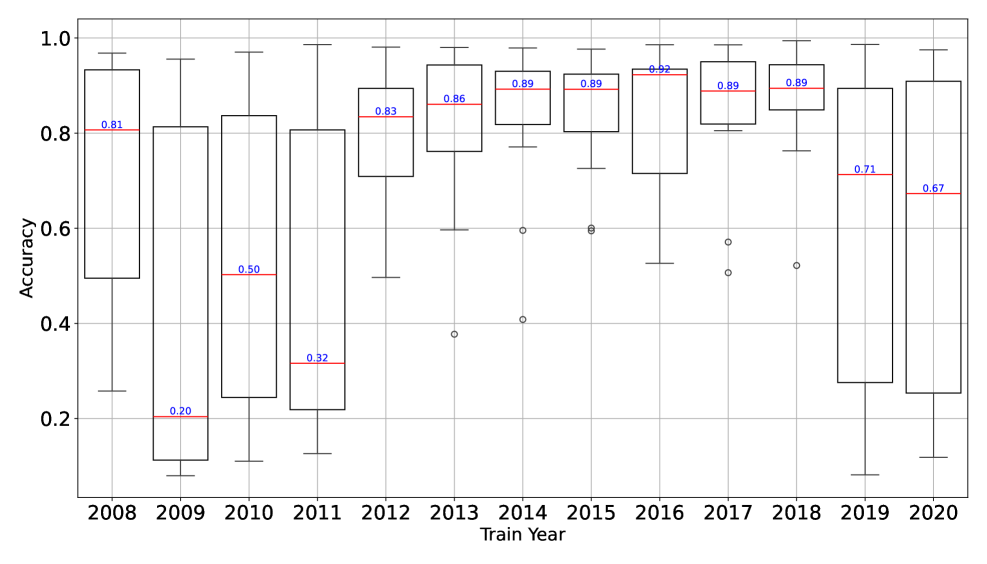
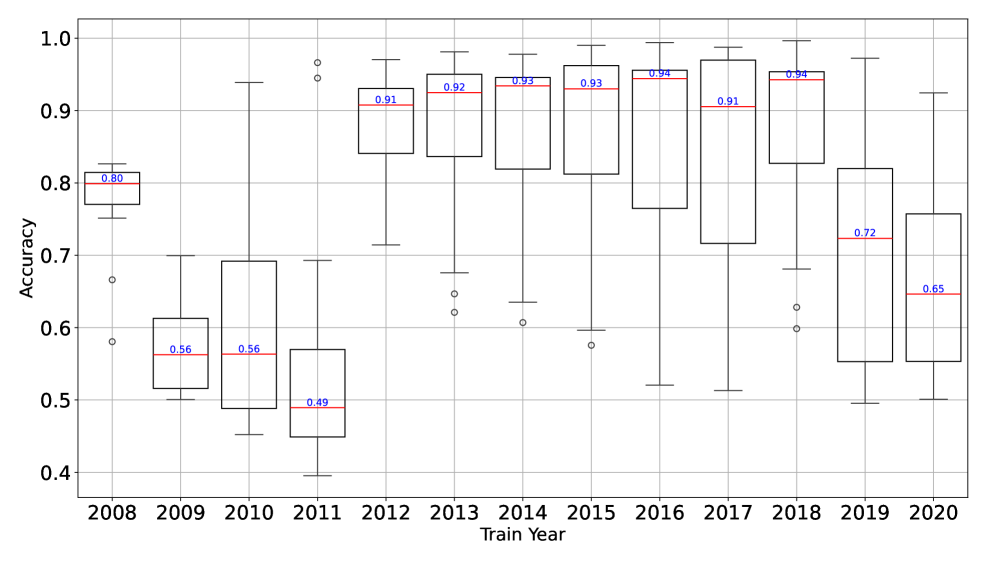
实验结果表明,概念漂移对Android恶意软件检测模型的性能有显著影响。不同的特征类型和数据环境对概念漂移的影响程度不同。平衡算法在一定程度上可以缓解类别不平衡问题,但无法完全解决概念漂移。大型语言模型在少量样本学习中表现出一定的检测能力,但仍无法完全缓解概念漂移。
🎯 应用场景
该研究成果可应用于提升Android恶意软件检测系统的鲁棒性和适应性。通过了解概念漂移的影响因素,可以设计更有效的模型更新策略和特征选择方法,从而提高恶意软件检测的准确率和召回率。此外,该研究还可以指导开发更智能的安全防护系统,能够自动适应恶意软件的演变。
📄 摘要(原文)
Despite outstanding results, machine learning-based Android malware detection models struggle with concept drift, where rapidly evolving malware characteristics degrade model effectiveness. This study examines the impact of concept drift on Android malware detection, evaluating two datasets and nine machine learning and deep learning algorithms, as well as Large Language Models (LLMs). Various feature types--static, dynamic, hybrid, semantic, and image-based--were considered. The results showed that concept drift is widespread and significantly affects model performance. Factors influencing the drift include feature types, data environments, and detection methods. Balancing algorithms helped with class imbalance but did not fully address concept drift, which primarily stems from the dynamic nature of the malware landscape. No strong link was found between the type of algorithm used and concept drift, the impact was relatively minor compared to other variables since hyperparameters were not fine-tuned, and the default algorithm configurations were used. While LLMs using few-shot learning demonstrated promising detection performance, they did not fully mitigate concept drift, highlighting the need for further investigation.