A Systematic Literature Review on Detecting Software Vulnerabilities with Large Language Models
作者: Sabrina Kaniewski, Fabian Schmidt, Markus Enzweiler, Michael Menth, Tobias Heer
分类: cs.SE, cs.AI
发布日期: 2025-07-30 (更新: 2025-12-19)
备注: 43 pages + 20 pages references, 7 tables, 13 figures
🔗 代码/项目: GITHUB
💡 一句话要点
对基于大型语言模型(LLM)的软件漏洞检测方法进行系统性文献综述
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件漏洞检测 系统性文献综述 软件安全 代码分析 自然语言处理 深度学习 程序分析
📋 核心要点
- 现有基于LLM的软件漏洞检测研究分散,系统设计和数据集使用差异大,缺乏可比性,难以评估技术现状。
- 本文通过系统性文献综述,对相关研究进行分类和分析,构建细粒度分类体系,识别关键限制和未来研究方向。
- 分析了263篇相关论文,涵盖任务形式、输入表示、系统架构和技术,并对数据集的特征、漏洞覆盖率和多样性进行了分析。
📝 摘要(中文)
大型语言模型(LLM)在软件工程领域的日益普及,激发了人们对其在软件漏洞检测中应用的兴趣。然而,该领域的快速发展导致研究格局分散,不同研究在系统设计和数据集使用等方面存在差异,难以比较。这种碎片化使得难以获得对现有技术的清晰概览,也难以对研究进行有意义的比较和分类。本文对基于LLM的软件漏洞检测进行了全面的系统性文献综述(SLR)。我们分析了2020年1月至2025年11月期间发表的263项研究,并按任务公式、输入表示、系统架构和技术对其进行分类。此外,我们还分析了所使用的数据集,包括其特征、漏洞覆盖范围和多样性。我们提出了漏洞检测方法的细粒度分类,确定了关键限制,并概述了可操作的未来研究机会。通过提供该领域的结构化概述,本次综述提高了透明度,并为旨在进行更具可比性和可重复性的研究的研究人员和从业人员提供了实用指南。我们公开发布所有工件,并在https://github.com/hs-esslingen-it-security/Awesome-LLM4SVD维护一个基于LLM的软件漏洞检测研究的动态存储库。
🔬 方法详解
问题定义:现有基于大型语言模型的软件漏洞检测研究领域发展迅速,但呈现出碎片化的状态。不同研究在系统设计、数据集选择等方面存在显著差异,导致研究结果难以直接比较和评估。缺乏一个统一的框架来组织和理解这些研究,阻碍了该领域的进一步发展。现有方法缺乏透明度和可重复性,难以指导未来的研究方向。
核心思路:本文的核心思路是通过系统性的文献综述,对现有研究进行梳理、分类和分析,从而构建一个结构化的知识体系。通过对研究方法、数据集、评估指标等方面的深入分析,揭示该领域的关键挑战和未来发展方向。旨在提高研究的透明度,促进可比性和可重复性,并为研究人员和从业者提供指导。
技术框架:本文采用系统性文献综述(SLR)的方法,主要包括以下几个阶段: 1. 文献检索:确定检索范围和关键词,从学术数据库中检索相关文献。 2. 文献筛选:根据预定的标准,筛选出符合研究主题的文献。 3. 数据提取:从筛选出的文献中提取关键信息,如任务形式、输入表示、系统架构、数据集等。 4. 分类与分析:根据提取的信息,对文献进行分类,并进行深入的分析和比较。 5. 结果总结与展望:总结现有研究的成果和不足,提出未来研究方向的建议。
关键创新:本文的创新之处在于: 1. 全面的文献覆盖:对2020年至2025年期间发表的263篇相关论文进行了分析,覆盖范围广泛。 2. 细粒度的分类体系:构建了基于任务形式、输入表示、系统架构和技术的细粒度分类体系,有助于更深入地理解不同研究之间的差异。 3. 关键限制的识别:识别了现有研究的关键限制,为未来的研究提供了明确的方向。 4. 可操作的建议:提出了可操作的未来研究方向建议,有助于推动该领域的发展。
关键设计:本文的关键设计在于: 1. 严格的文献筛选标准:确保纳入研究的文献具有高质量和相关性。 2. 标准化的数据提取方法:确保提取的信息准确、一致和可比。 3. 多维度的分类体系:从多个维度对文献进行分类,有助于更全面地理解研究的特点和差异。 4. 客观的分析方法:采用客观的分析方法,避免主观偏见,确保研究结果的可靠性。
🖼️ 关键图片
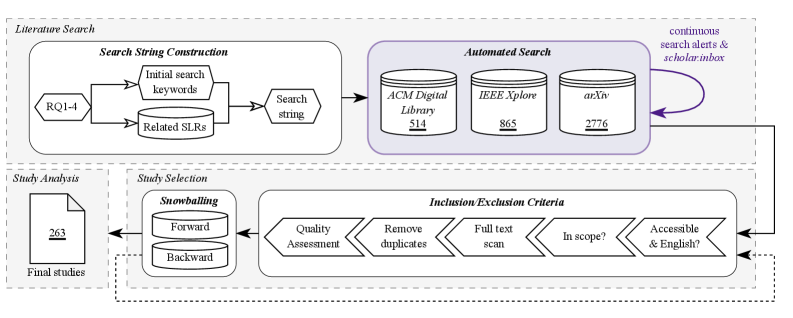
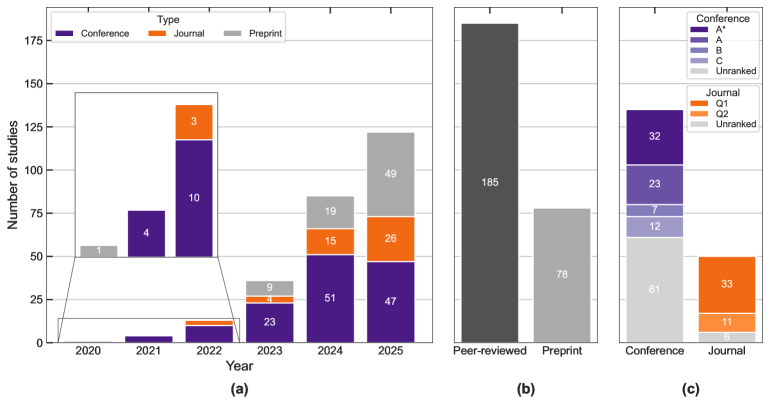

📊 实验亮点
该综述分析了263篇相关论文,构建了细粒度的分类体系,并识别了现有研究的关键限制。通过对数据集的特征、漏洞覆盖率和多样性进行分析,为未来的研究提供了有价值的参考。该综述还公开发布了所有工件,并维护了一个动态存储库,方便研究人员获取相关资源。
🎯 应用场景
该研究成果可应用于软件安全领域,帮助开发人员和安全工程师更好地理解和利用LLM进行软件漏洞检测。通过提供结构化的知识体系和未来研究方向,可以促进相关技术的进步,提高软件系统的安全性。该综述也可作为教学资源,帮助学生和研究人员快速了解该领域的研究现状。
📄 摘要(原文)
The increasing adoption of Large Language Models (LLMs) in software engineering has sparked interest in their use for software vulnerability detection. However, the rapid development of this field has resulted in a fragmented research landscape, with diverse studies that are difficult to compare due to differences in, e.g., system designs and dataset usage. This fragmentation makes it difficult to obtain a clear overview of the state-of-the-art or compare and categorize studies meaningfully. In this work, we present a comprehensive systematic literature review (SLR) of LLM-based software vulnerability detection. We analyze 263 studies published between January 2020 and November 2025, categorizing them by task formulation, input representation, system architecture, and techniques. Further, we analyze the datasets used, including their characteristics, vulnerability coverage, and diversity. We present a fine-grained taxonomy of vulnerability detection approaches, identify key limitations, and outline actionable future research opportunities. By providing a structured overview of the field, this review improves transparency and serves as a practical guide for researchers and practitioners aiming to conduct more comparable and reproducible research. We publicly release all artifacts and maintain a living repository of LLM-based software vulnerability detection studies at https://github.com/hs-esslingen-it-security/Awesome-LLM4SVD.