Towards Blind Bitstream-corrupted Video Recovery via a Visual Foundation Model-driven Framework
作者: Tianyi Liu, Kejun Wu, Chen Cai, Yi Wang, Kim-Hui Yap, Lap-Pui Chau
分类: eess.IV, cs.AI, cs.CV, cs.MM
发布日期: 2025-07-30
备注: 10 pages, 5 figures, accepted by ACMMM 2025
期刊: Proceedings of the 33rd ACM International Conference on Multimedia, 2025
💡 一句话要点
提出基于视觉基础模型的盲比特流损坏视频恢复框架,无需人工标注。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频恢复 比特流损坏 视觉基础模型 盲恢复 特征补全
📋 核心要点
- 现有比特流损坏视频恢复方法依赖于耗时且费力的人工标注损坏区域,工作量大。
- 该论文提出一个集成了视觉基础模型和恢复模型的盲恢复框架,无需人工标注,适应不同损坏。
- 实验结果表明,该方法在比特流损坏视频恢复方面表现出色,无需人工标注掩码序列。
📝 摘要(中文)
本文提出了一种盲比特流损坏视频恢复框架,该框架集成了视觉基础模型和一个恢复模型,能够适应不同类型的损坏和比特流级别的提示。框架内的Detect Any Corruption (DAC)模型利用视觉基础模型的丰富先验知识,并结合比特流和损坏知识,以增强损坏定位和盲恢复。此外,还引入了一种新颖的Corruption-aware Feature Completion (CFC)模块,该模块基于对损坏的高级理解自适应地处理残差贡献。通过VFM引导的分层特征增强和混合残差专家(MoRE)结构中的高级协调,该方法抑制了伪影并增强了信息丰富的残差。综合评估表明,该方法在比特流损坏视频恢复方面取得了出色的性能,且无需手动标记的掩码序列。
🔬 方法详解
问题定义:论文旨在解决比特流损坏视频的恢复问题。现有方法的主要痛点在于需要对每个损坏的视频帧进行耗时且费力的人工标注损坏区域,这在实际应用中造成了巨大的工作量。此外,由于损坏帧中的局部残差信息可能会误导特征补全和后续内容恢复,因此难以实现高质量的恢复。
核心思路:论文的核心思路是利用视觉基础模型(VFM)的强大先验知识,结合比特流和损坏的知识,来指导损坏区域的定位和视频内容的恢复。通过VFM提供的高级语义信息,可以更好地理解和处理损坏,从而避免局部残差信息的误导。
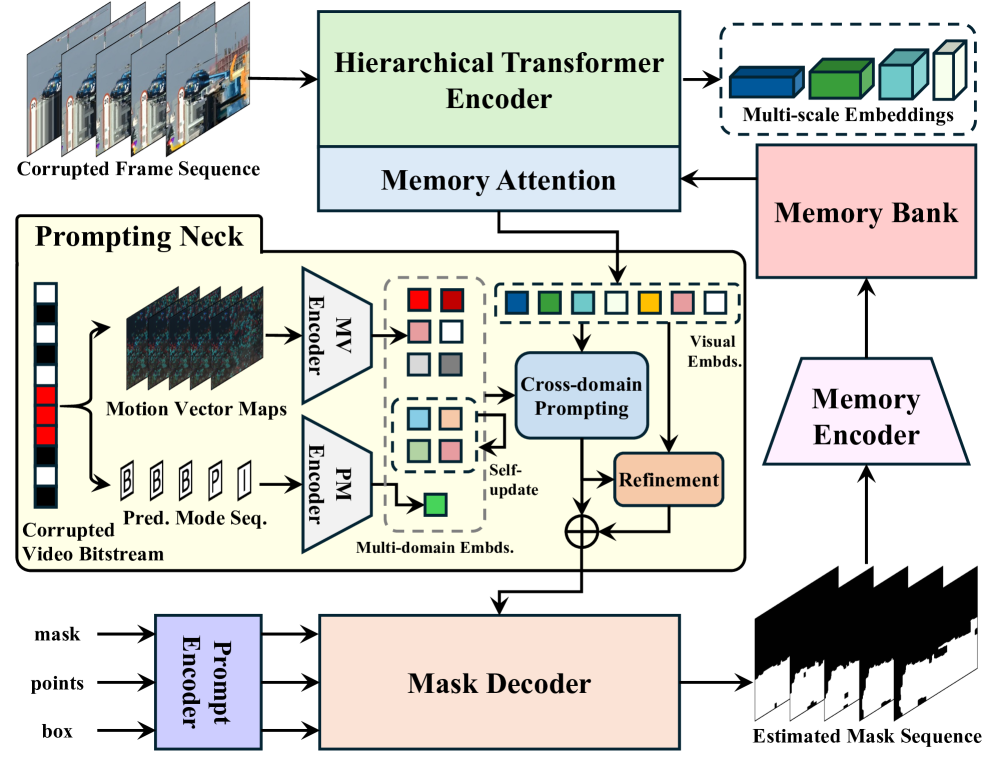
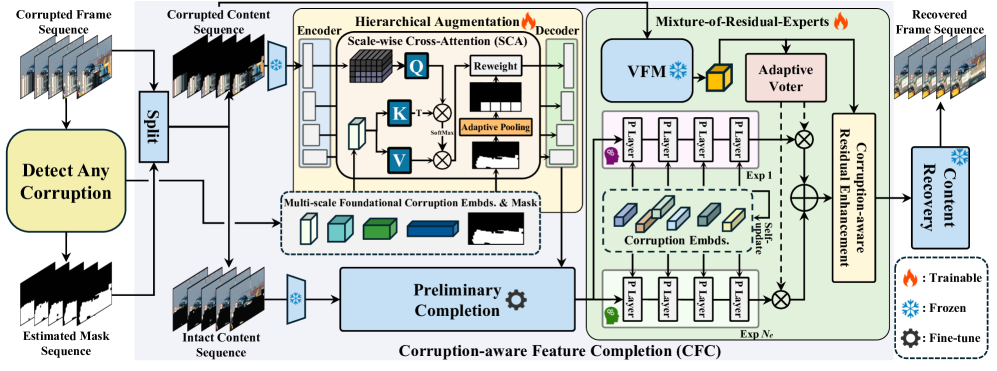
技术框架:该框架主要包含两个核心模块:Detect Any Corruption (DAC)模型和Corruption-aware Feature Completion (CFC)模块。DAC模型负责利用VFM的先验知识和比特流/损坏信息来定位损坏区域。CFC模块则基于对损坏的高级理解,自适应地处理残差贡献,以实现更准确的特征补全。此外,还采用了VFM引导的分层特征增强和混合残差专家(MoRE)结构,以抑制伪影并增强信息丰富的残差。
关键创新:该论文的关键创新在于提出了一个完全盲的比特流损坏视频恢复框架,无需人工标注的掩码序列。通过将视觉基础模型与恢复模型相结合,实现了对损坏区域的自动定位和高质量的内容恢复。此外,Corruption-aware Feature Completion (CFC)模块的设计也能够根据对损坏的高级理解自适应地处理残差贡献,从而提高了恢复的准确性。
关键设计:DAC模型利用VFM提取的特征,并结合比特流信息和损坏类型信息,通过一个分类器来预测损坏区域。CFC模块则使用一个注意力机制来根据损坏的程度自适应地调整残差信息的权重。MoRE结构则通过多个残差专家来处理不同类型的损坏,并使用一个门控机制来选择合适的专家。
🖼️ 关键图片

📊 实验亮点
该方法在比特流损坏视频恢复任务上取得了显著的性能提升,无需人工标注。实验结果表明,该方法能够有效地抑制伪影,并恢复出高质量的视频内容。具体的性能数据和对比基线信息在论文中进行了详细的展示,证明了该方法在盲恢复方面的优越性。
🎯 应用场景
该研究成果可应用于多媒体通信和存储系统中,提高视频传输和存储的可靠性。例如,在网络视频传输中,即使出现比特流损坏,也能恢复出高质量的视频内容,提升用户体验。此外,该技术还可用于修复老旧或损坏的视频档案,具有重要的实际应用价值和潜在的社会效益。
📄 摘要(原文)
Video signals are vulnerable in multimedia communication and storage systems, as even slight bitstream-domain corruption can lead to significant pixel-domain degradation. To recover faithful spatio-temporal content from corrupted inputs, bitstream-corrupted video recovery has recently emerged as a challenging and understudied task. However, existing methods require time-consuming and labor-intensive annotation of corrupted regions for each corrupted video frame, resulting in a large workload in practice. In addition, high-quality recovery remains difficult as part of the local residual information in corrupted frames may mislead feature completion and successive content recovery. In this paper, we propose the first blind bitstream-corrupted video recovery framework that integrates visual foundation models with a recovery model, which is adapted to different types of corruption and bitstream-level prompts. Within the framework, the proposed Detect Any Corruption (DAC) model leverages the rich priors of the visual foundation model while incorporating bitstream and corruption knowledge to enhance corruption localization and blind recovery. Additionally, we introduce a novel Corruption-aware Feature Completion (CFC) module, which adaptively processes residual contributions based on high-level corruption understanding. With VFM-guided hierarchical feature augmentation and high-level coordination in a mixture-of-residual-experts (MoRE) structure, our method suppresses artifacts and enhances informative residuals. Comprehensive evaluations show that the proposed method achieves outstanding performance in bitstream-corrupted video recovery without requiring a manually labeled mask sequence. The demonstrated effectiveness will help to realize improved user experience, wider application scenarios, and more reliable multimedia communication and storage systems.