Systematic Evaluation of Knowledge Graph Repair with Large Language Models
作者: Tung-Wei Lin, Gabe Fierro, Han Li, Tianzhen Hong, Pierluigi Nuzzo, Alberto Sangiovanni-Vinentelli
分类: cs.DB, cs.AI
发布日期: 2025-07-30
💡 一句话要点
提出基于大语言模型的知识图谱修复系统评估框架,解决现有评估方法缺乏系统性的问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱修复 大语言模型 SHACL约束 评估框架 违反诱导操作
📋 核心要点
- 现有知识图谱修复评估依赖于特定数据集,缺乏通用性和系统性。
- 提出利用违反诱导操作(VIOs)系统生成约束违反,构建更全面的评估框架。
- 实验表明,包含SHACL约束和知识图谱上下文信息的简洁提示能提升大语言模型修复性能。
📝 摘要(中文)
本文提出了一种系统性的方法,用于评估知识图谱修复的质量,特别是针对形状约束语言(SHACL)中定义的约束违反。现有的评估方法依赖于ad hoc数据集,这限制了在更通用设置中对修复系统进行严格分析。本文的方法通过一种新颖的机制(称为违反诱导操作(VIOs))系统地生成违反来解决这一问题。我们使用提出的评估框架来评估一系列使用大型语言模型构建的修复系统。我们分析了这些系统在不同提示策略下的性能。结果表明,包含相关违反的SHACL约束和来自知识图谱的关键上下文信息的简洁提示可产生最佳性能。
🔬 方法详解
问题定义:知识图谱在构建和维护过程中容易出现错误,导致违反预定义的约束(如SHACL约束)。现有的知识图谱修复评估方法主要依赖于人工构建的特定数据集,这些数据集难以覆盖所有可能的约束违反情况,缺乏通用性和系统性,无法对修复系统的性能进行全面评估。
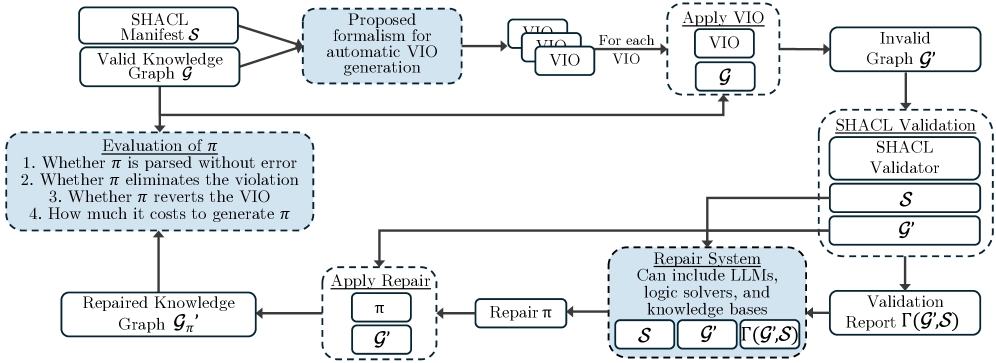
核心思路:本文的核心思路是通过设计一系列“违反诱导操作”(Violation-Inducing Operations, VIOs),自动地、系统性地在知识图谱中引入各种类型的约束违反。这样可以生成大量具有不同特征的违反实例,从而构建一个更全面、更具代表性的评估数据集。
技术框架:该评估框架主要包含以下几个阶段:1) 定义SHACL约束;2) 设计VIOs,用于在知识图谱中引入违反;3) 使用VIOs生成包含约束违反的知识图谱;4) 利用大语言模型构建知识图谱修复系统,并采用不同的prompt策略;5) 使用生成的知识图谱评估修复系统的性能。
关键创新:最重要的技术创新点在于提出了VIOs的概念和实现方法。VIOs能够系统地生成各种类型的约束违反,从而克服了现有评估方法依赖于特定数据集的局限性。这使得可以对知识图谱修复系统进行更全面、更严格的评估。
关键设计:VIOs的具体设计需要根据SHACL约束的类型进行定制。例如,对于类型约束,VIOs可以修改实体的类型;对于属性约束,VIOs可以修改属性的值或删除属性。此外,prompt的设计对大语言模型的修复性能至关重要。实验表明,包含相关违反的SHACL约束和来自知识图谱的关键上下文信息的简洁prompt效果最好。具体prompt的设计细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的评估框架能够有效评估基于大语言模型的知识图谱修复系统。通过对比不同的prompt策略,发现包含相关违反的SHACL约束和来自知识图谱的关键上下文信息的简洁prompt可产生最佳性能。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于知识图谱的质量控制、自动修复和持续维护。通过系统性的评估,可以更好地了解不同修复系统的优缺点,从而选择合适的修复方法,提高知识图谱的准确性和完整性。此外,该框架还可以用于评估和改进大语言模型在知识图谱处理方面的能力。
📄 摘要(原文)
We present a systematic approach for evaluating the quality of knowledge graph repairs with respect to constraint violations defined in shapes constraint language (SHACL). Current evaluation methods rely on \emph{ad hoc} datasets, which limits the rigorous analysis of repair systems in more general settings. Our method addresses this gap by systematically generating violations using a novel mechanism, termed violation-inducing operations (VIOs). We use the proposed evaluation framework to assess a range of repair systems which we build using large language models. We analyze the performance of these systems across different prompting strategies. Results indicate that concise prompts containing both the relevant violated SHACL constraints and key contextual information from the knowledge graph yield the best performance.