League of LLMs: A Benchmark-Free Paradigm for Mutual Evaluation of Large Language Models
作者: Qianhong Guo, Wei Xie, Xiaofang Cai, Enze Wang, Shuoyoucheng Ma, Xiaobing Sun, Tian Xia, Kai Chen, Xiaofeng Wang, Baosheng Wang
分类: cs.AI, cs.CL
发布日期: 2025-07-30 (更新: 2026-01-07)
💡 一句话要点
提出League of LLMs以解决大型语言模型评估的可靠性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 评估方法 无基准评估 自我管理联盟 模型能力 透明性 客观性
📋 核心要点
- 现有的LLM评估方法面临数据污染、操作不透明和主观偏好等挑战,导致评估结果不可靠。
- 本文提出的LOL方法通过将多个LLM组织成自我管理的联盟,进行多轮相互评估,旨在提高评估的客观性和透明性。
- 实验结果表明,LOL能够有效区分不同LLM的能力,并保持高达70.7%的内部排名一致性,揭示了传统方法难以捕捉的行为特征。
📝 摘要(中文)
尽管大型语言模型(LLMs)在多种任务中展现了卓越的能力,但由于数据污染、操作不透明和主观偏好,可靠评估仍然是一个关键挑战。为了解决这些问题,本文提出了一种新颖的无基准评估范式——League of LLMs(LOL),将多个LLM组织成一个自我管理的联盟进行多轮相互评估。LOL整合了动态、透明、客观和专业四个核心标准,以减轻现有范式的主要局限性。对八种主流LLM在数学和编程任务上的实验表明,LOL能够有效区分LLM能力,同时保持高内部排名稳定性(Top-$k$一致性为70.7%)。此外,LOL揭示了一些传统范式难以捕捉的经验发现,例如某些模型表现出“记忆性回答”行为,以及在OpenAI家族中发现的统计显著的同质性偏差(Δ=9,p<0.05)。最后,我们将框架和代码公开,作为当前LLM评估生态系统的有价值补充。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLMs)评估中的可靠性问题,现有方法存在数据污染、操作不透明和主观偏好等痛点,导致评估结果不够客观和一致。
核心思路:LOL通过将多个LLM组织成一个自我管理的联盟,进行多轮相互评估,整合动态、透明、客观和专业四个核心标准,以提高评估的有效性和可靠性。
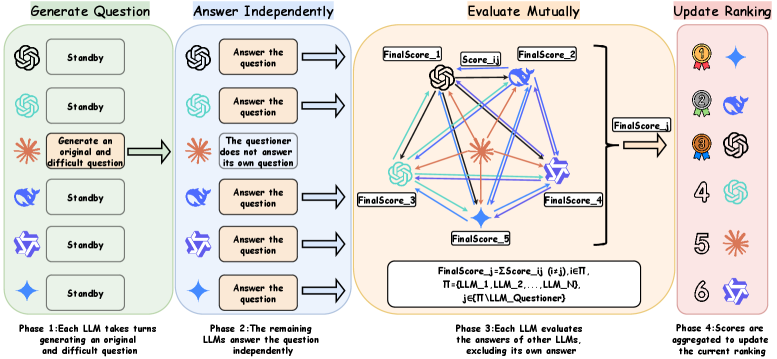
技术框架:LOL的整体架构包括多个LLM的组织、评估过程的设计和结果的分析。评估过程分为多个回合,每个模型在不同任务上相互评估,形成综合评分。
关键创新:LOL的主要创新在于其无基准的评估方式,通过自我管理的联盟结构,克服了传统评估方法的局限性,能够更全面地反映模型的能力和行为特征。
关键设计:在设计上,LOL采用了动态评估机制,允许模型在不同回合中根据表现调整评估策略,同时引入透明的评分标准和客观的评估指标,以确保评估过程的公正性。具体参数设置和损失函数的设计在论文中详细描述。
🖼️ 关键图片

📊 实验亮点
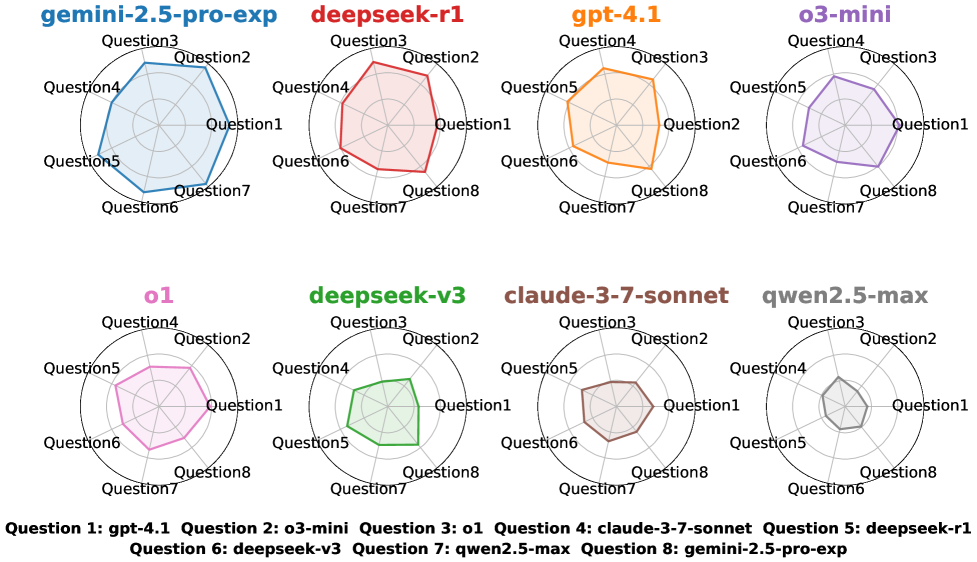
实验结果显示,LOL在对八种主流LLM的评估中,能够有效区分模型能力,内部排名一致性达到70.7%。此外,LOL还揭示了某些模型的“记忆性回答”行为和OpenAI家族中的同质性偏差(Δ=9,p<0.05),这些发现为理解LLM的行为提供了新的视角。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、编程辅助、教育技术等。通过提供一种更可靠的评估方法,LOL可以帮助研究人员和开发者更好地理解和优化大型语言模型的性能,推动相关技术的进步和应用。未来,LOL可能成为LLM评估的标准工具,促进模型的透明性和可解释性。
📄 摘要(原文)
Although large language models (LLMs) have shown exceptional capabilities across a wide range of tasks, reliable evaluation remains a critical challenge due to data contamination, opaque operation, and subjective preferences. To address these issues, we propose League of LLMs (LOL), a novel benchmark-free evaluation paradigm that organizes multiple LLMs into a self-governed league for multi-round mutual evaluation. LOL integrates four core criteria (dynamic, transparent, objective, and professional) to mitigate key limitations of existing paradigms. Experiments on eight mainstream LLMs in mathematics and programming demonstrate that LOL can effectively distinguish LLM capabilities while maintaining high internal ranking stability (Top-$k$ consistency $= 70.7\%$). Beyond ranking, LOL reveals empirical findings that are difficult for traditional paradigms to capture. For instance, ``memorization-based answering'' behaviors are observed in some models, and a statistically significant homophily bias is found within the OpenAI family ($Δ= 9$, $p < 0.05$). Finally, we make our framework and code publicly available as a valuable complement to the current LLM evaluation ecosystem.