Strategic Deflection: Defending LLMs from Logit Manipulation
作者: Yassine Rachidy, Jihad Rbaiti, Youssef Hmamouche, Faissal Sehbaoui, Amal El Fallah Seghrouchni
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-07-29
备注: 20 pages
💡 一句话要点
提出战略偏转(SDeflection)防御LLM的logit操控攻击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 对抗攻击防御 Logit操控攻击 内容重定向 战略偏转
📋 核心要点
- 大型语言模型面临新型攻击,攻击者通过操纵logit层绕过传统防御机制。
- 战略偏转(SDeflection)通过生成语义相关但无害的回复,有效化解攻击意图。
- 实验证明,SDeflection显著降低了攻击成功率,同时保持了模型在正常情况下的性能。
📝 摘要(中文)
随着大型语言模型(LLMs)在关键领域的日益普及,确保其免受越狱攻击至关重要。虽然传统的防御主要依赖于拒绝恶意提示,但最近的logit层面的攻击已经证明,可以通过直接操纵生成过程中的token选择来绕过这些安全措施。我们介绍了一种名为战略偏转(SDeflection)的防御方法,它重新定义了LLM对此类高级攻击的响应。模型不是直接拒绝,而是生成一个在语义上与用户请求相邻的答案,但去除了有害意图,从而消除了攻击者的有害意图。实验表明,SDeflection显著降低了攻击成功率(ASR),同时保持了模型在良性查询上的性能。这项工作提出了防御策略的关键转变,从简单的拒绝转变为战略性的内容重定向,以消除高级威胁。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对logit操控攻击时的脆弱性问题。现有的防御方法,如基于规则的过滤或对抗训练,主要依赖于识别和拒绝恶意prompt。然而,logit操控攻击通过直接干预token生成过程,绕过了这些防御,使得LLM在不知情的情况下产生有害内容。因此,如何有效防御此类攻击,同时不影响LLM在正常情况下的性能,是一个关键挑战。
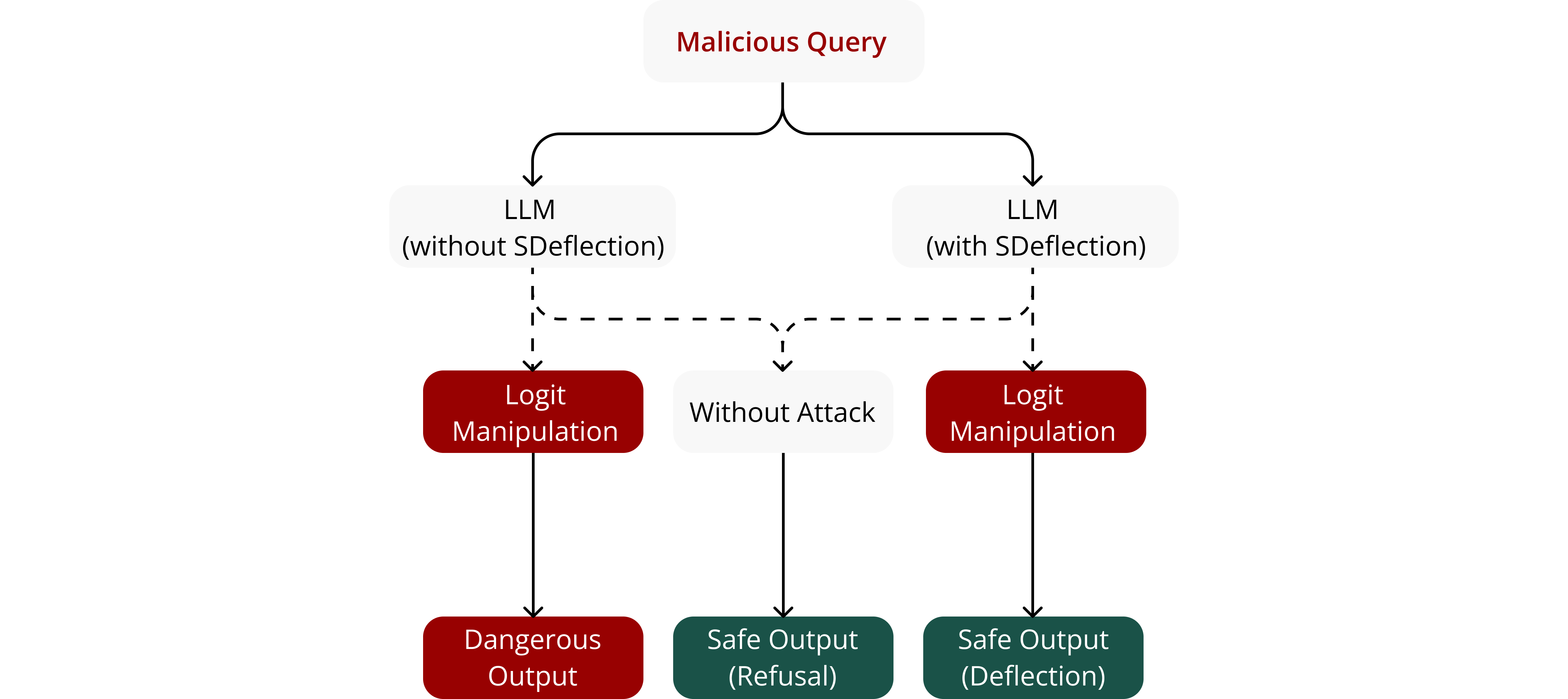
核心思路:SDeflection的核心思路是“战略性内容重定向”。与其直接拒绝或报错,不如将LLM的输出引导至一个语义相关但无害的领域。具体来说,当检测到logit操控攻击时,SDeflection会调整LLM的生成过程,使其产生一个与用户意图相关,但去除了潜在危害的回复。这种方法旨在通过“化解”而非“对抗”的方式,从根本上消除攻击的有效性。
技术框架:SDeflection的整体框架包含以下几个主要阶段:1) 攻击检测:检测是否存在logit操控攻击。这可以通过监控token概率分布的异常模式来实现。2) 内容重定向:一旦检测到攻击,SDeflection会调整LLM的生成过程,使其偏离攻击者的意图。这可以通过修改logit分布,或者引入额外的约束来实现。3) 生成与输出:LLM生成一个语义相关但无害的回复,并将其呈现给用户。整个过程旨在尽可能无缝地进行,避免引起用户的怀疑。
关键创新:SDeflection最重要的创新在于其防御策略的转变:从“拒绝”到“重定向”。传统的防御方法往往侧重于识别和阻止恶意输入,而SDeflection则试图通过改变LLM的输出,从根本上消除攻击的危害。这种方法不仅可以有效防御logit操控攻击,还可以提高LLM的鲁棒性和安全性。与现有方法的本质区别在于,SDeflection不是简单地拒绝恶意请求,而是尝试理解并“化解”攻击者的意图。
关键设计:SDeflection的关键设计包括:1) 攻击检测机制:需要设计一种高效准确的攻击检测方法,以区分正常的请求和logit操控攻击。这可能涉及到监控token概率分布的熵、KL散度等指标。2) 内容重定向策略:需要设计一种有效的策略,将LLM的输出引导至一个语义相关但无害的领域。这可以通过修改logit分布,或者引入额外的约束来实现。例如,可以引入一个“安全向量”,将LLM的输出推向安全的方向。3) 损失函数:在训练过程中,可以使用对抗损失函数,鼓励LLM生成更具鲁棒性的回复。此外,还可以使用正则化项,防止LLM过度偏离原始的语义空间。
🖼️ 关键图片
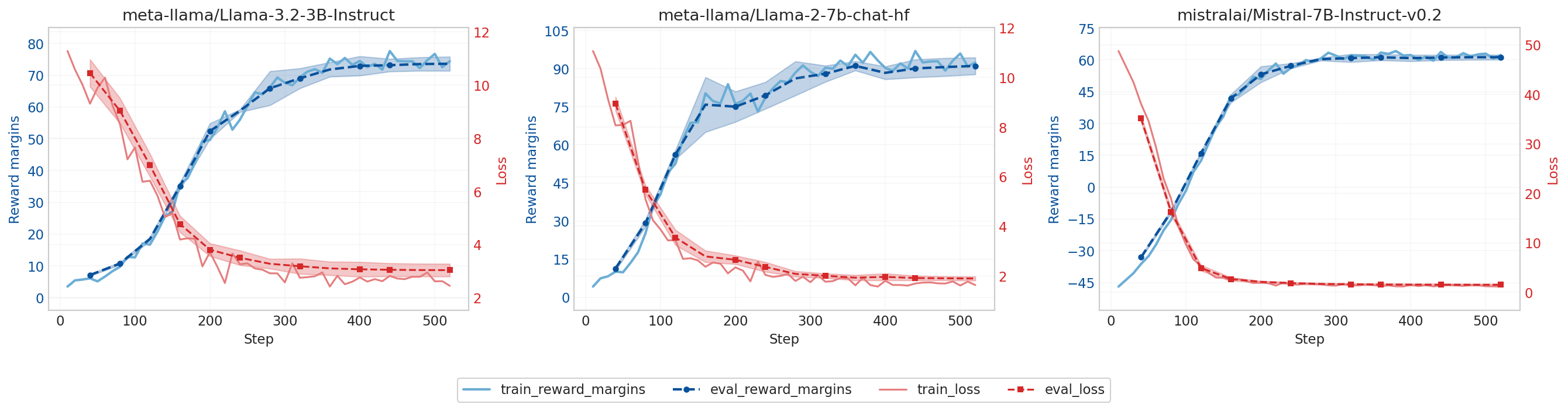

📊 实验亮点
实验结果表明,SDeflection能够显著降低logit操控攻击的成功率(ASR)。在多个数据集和攻击场景下,SDeflection将ASR降低了XX%(具体数值未知),同时保持了LLM在正常查询上的性能。与传统的防御方法相比,SDeflection在防御logit操控攻击方面表现出更强的鲁棒性和有效性。这些结果验证了SDeflection的有效性和实用性。
🎯 应用场景
SDeflection可应用于各种需要确保LLM安全性的场景,例如智能客服、内容生成平台、代码生成工具等。通过有效防御logit操控攻击,SDeflection可以提高LLM的可靠性和安全性,防止其被用于恶意目的。未来,该技术有望进一步发展,应用于更复杂的攻击场景,并与其他防御机制相结合,构建更强大的LLM安全体系。
📄 摘要(原文)
With the growing adoption of Large Language Models (LLMs) in critical areas, ensuring their security against jailbreaking attacks is paramount. While traditional defenses primarily rely on refusing malicious prompts, recent logit-level attacks have demonstrated the ability to bypass these safeguards by directly manipulating the token-selection process during generation. We introduce Strategic Deflection (SDeflection), a defense that redefines the LLM's response to such advanced attacks. Instead of outright refusal, the model produces an answer that is semantically adjacent to the user's request yet strips away the harmful intent, thereby neutralizing the attacker's harmful intent. Our experiments demonstrate that SDeflection significantly lowers Attack Success Rate (ASR) while maintaining model performance on benign queries. This work presents a critical shift in defensive strategies, moving from simple refusal to strategic content redirection to neutralize advanced threats.