UserBench: An Interactive Gym Environment for User-Centric Agents
作者: Cheng Qian, Zuxin Liu, Akshara Prabhakar, Zhiwei Liu, Jianguo Zhang, Haolin Chen, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, Huan Wang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-07-29
备注: 25 Pages, 17 Figures, 6 Tables
💡 一句话要点
UserBench:一个以用户为中心的交互式环境,用于评估用户导向型Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 大型语言模型 用户意图理解 交互式Agent 基准测试
📋 核心要点
- 现有Agent在与用户进行复杂、动态目标交互时,缺乏主动性和用户意图理解能力,导致协作效率低下。
- UserBench通过模拟具有不明确目标和渐进偏好的用户,构建多轮交互环境,促使Agent主动澄清意图并做出决策。
- 实验表明,现有LLM在UserBench上任务完成度和用户对齐度较低,突显了提升Agent协作能力的重要性。
📝 摘要(中文)
基于大型语言模型(LLM)的Agent在推理和工具使用方面取得了显著进展,能够解决复杂的任务。然而,它们与用户主动协作的能力,尤其是在目标模糊、演变或间接表达时,仍未得到充分探索。为了弥补这一差距,我们推出了UserBench,这是一个以用户为中心的基准,旨在评估Agent在多轮、偏好驱动的交互中的表现。UserBench包含模拟用户,他们从不明确的目标开始,并逐步揭示偏好,要求Agent主动澄清意图并利用工具做出有依据的决策。我们对领先的开源和闭源LLM的评估表明,任务完成和用户对齐之间存在显著脱节。例如,模型平均只有20%的时间提供与所有用户意图完全一致的答案,即使是最先进的模型也通过主动交互发现不到30%的用户偏好。这些结果突出了构建不仅能执行任务,而且是真正的协作伙伴的Agent所面临的挑战。UserBench提供了一个交互式环境来衡量和提升这一关键能力。
🔬 方法详解
问题定义:现有基于LLM的Agent在解决复杂任务方面表现出色,但与用户的协作能力仍有不足,尤其是在用户目标不明确或动态变化的情况下。现有方法难以主动理解用户意图,导致Agent无法有效地提供帮助,用户体验不佳。
核心思路:UserBench的核心思路是创建一个模拟用户环境,该环境中的用户具有不明确的初始目标,并在交互过程中逐步揭示其偏好。Agent需要通过主动提问和探索,理解用户的真实意图,并利用工具来满足用户的需求。这种设计旨在模拟真实世界中人与人之间的协作场景,从而更好地评估和提升Agent的协作能力。
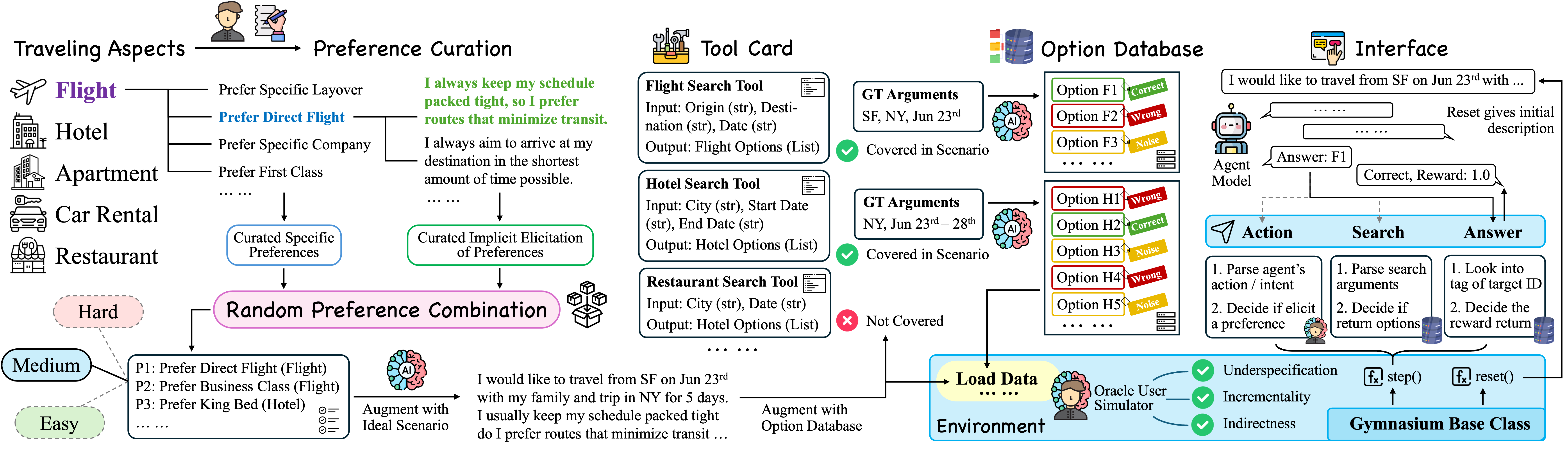
技术框架:UserBench包含以下主要模块:1) 模拟用户:模拟用户具有预设的隐藏目标和偏好,并根据Agent的提问和行为逐步揭示这些信息。2) Agent:Agent负责与模拟用户进行交互,理解用户意图,并利用工具来完成任务。3) 评估指标:评估指标用于衡量Agent的任务完成度和用户对齐度,例如,Agent是否成功完成了用户设定的目标,以及Agent的行为是否符合用户的偏好。
关键创新:UserBench的关键创新在于其以用户为中心的设计理念。与以往的基准测试不同,UserBench更加关注Agent与用户的交互过程,以及Agent理解和满足用户需求的能力。这种设计使得UserBench能够更好地评估Agent的协作能力,并为未来的研究提供新的方向。
关键设计:UserBench的关键设计包括:1) 模拟用户的目标和偏好设置:模拟用户的目标和偏好需要具有一定的复杂性和多样性,以模拟真实世界中的用户行为。2) Agent的提问和探索策略:Agent需要设计有效的提问和探索策略,以便更好地理解用户的意图。3) 评估指标的设计:评估指标需要能够准确地衡量Agent的任务完成度和用户对齐度。
🖼️ 关键图片
📊 实验亮点
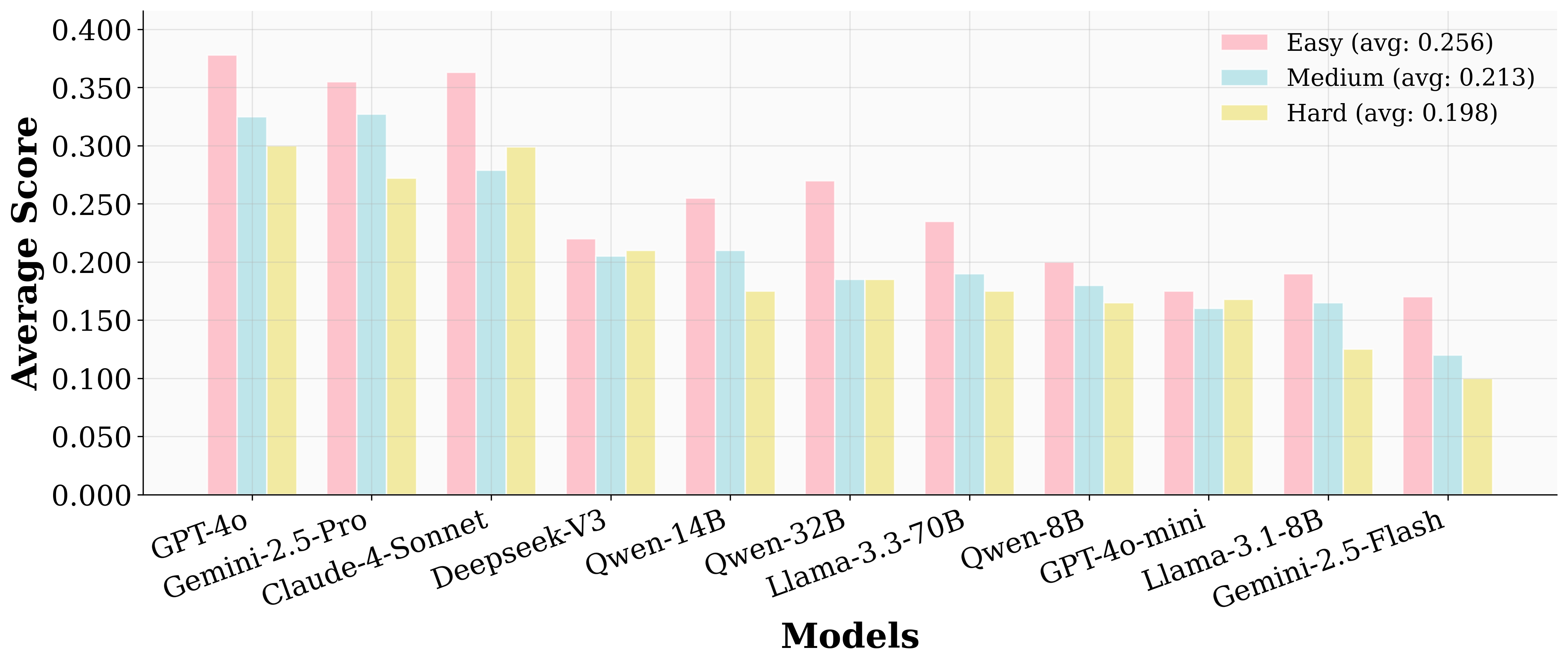
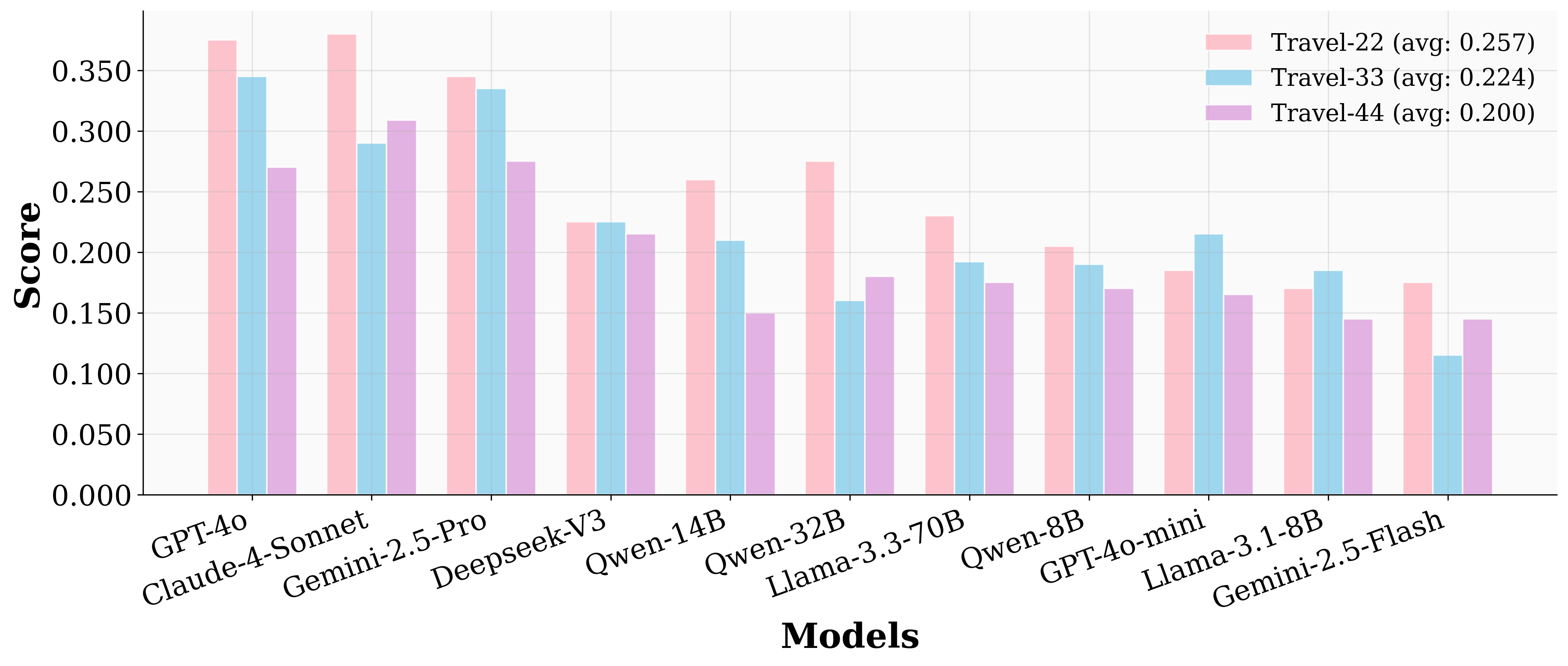
实验结果表明,即使是最先进的LLM在UserBench上的表现也远未达到理想水平。模型平均只有20%的时间提供与所有用户意图完全一致的答案,并且通过主动交互发现的用户偏好不到30%。这表明,现有Agent在理解用户意图和进行有效协作方面仍有很大的提升空间。
🎯 应用场景
UserBench的研究成果可应用于开发更智能、更用户友好的AI助手,例如智能客服、虚拟助手和个性化推荐系统。通过提升Agent与用户之间的协作能力,可以提高用户满意度,并实现更高效的人机交互。未来,UserBench可以扩展到更复杂的任务和场景,例如医疗诊断、金融咨询等。
📄 摘要(原文)
Large Language Models (LLMs)-based agents have made impressive progress in reasoning and tool use, enabling them to solve complex tasks. However, their ability to proactively collaborate with users, especially when goals are vague, evolving, or indirectly expressed, remains underexplored. To address this gap, we introduce UserBench, a user-centric benchmark designed to evaluate agents in multi-turn, preference-driven interactions. UserBench features simulated users who start with underspecified goals and reveal preferences incrementally, requiring agents to proactively clarify intent and make grounded decisions with tools. Our evaluation of leading open- and closed-source LLMs reveals a significant disconnect between task completion and user alignment. For instance, models provide answers that fully align with all user intents only 20% of the time on average, and even the most advanced models uncover fewer than 30% of all user preferences through active interaction. These results highlight the challenges of building agents that are not just capable task executors, but true collaborative partners. UserBench offers an interactive environment to measure and advance this critical capability.