UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
作者: Shuquan Lian, Yuhang Wu, Jia Ma, Yifan Ding, Zihan Song, Bingqi Chen, Xiawu Zheng, Hui Li
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-07-29 (更新: 2025-08-09)
🔗 代码/项目: GITHUB
💡 一句话要点
UI-AGILE:通过强化学习和精确推理时定位提升GUI智能体性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI智能体 强化学习 定位精度 多模态学习 用户界面 视觉定位 奖励函数
📋 核心要点
- 现有GUI智能体在推理设计、奖励机制和视觉噪声方面存在不足,限制了其性能。
- UI-AGILE通过改进训练过程(连续奖励、简单思考奖励、裁剪重采样)和推理过程(分解定位与选择)来增强GUI智能体。
- 实验表明,UI-AGILE在定位精度上取得了显著提升,并在ScreenSpot-Pro上超越最佳基线23%。
📝 摘要(中文)
多模态大型语言模型(MLLMs)的出现极大地推动了图形用户界面(GUI)智能体能力的发展。然而,现有的GUI智能体训练和推理技术仍然面临推理设计、无效奖励和视觉噪声的困境。为了解决这些问题,我们提出了UI-AGILE,旨在训练和推理两个阶段增强GUI智能体。在训练方面,我们对监督微调(SFT)过程进行了一系列改进:1)连续奖励函数,以激励高精度定位;2)“简单思考”奖励,以平衡规划速度和定位精度;3)基于裁剪的重采样策略,以缓解稀疏奖励问题并改进复杂任务的学习。在推理方面,我们提出了分解定位与选择,通过将图像分解为更小、更易于管理的部分,显著提高高分辨率显示器上的定位精度。实验表明,UI-AGILE在ScreenSpot-Pro和ScreenSpot-v2两个基准测试中实现了最先进的定位性能,同时也表现出强大的通用智能体能力。例如,使用我们的训练和推理增强方法,在ScreenSpot-Pro上比最佳基线提高了23%的定位精度。我们提供了代码在https://github.com/KDEGroup/UI-AGILE。
🔬 方法详解
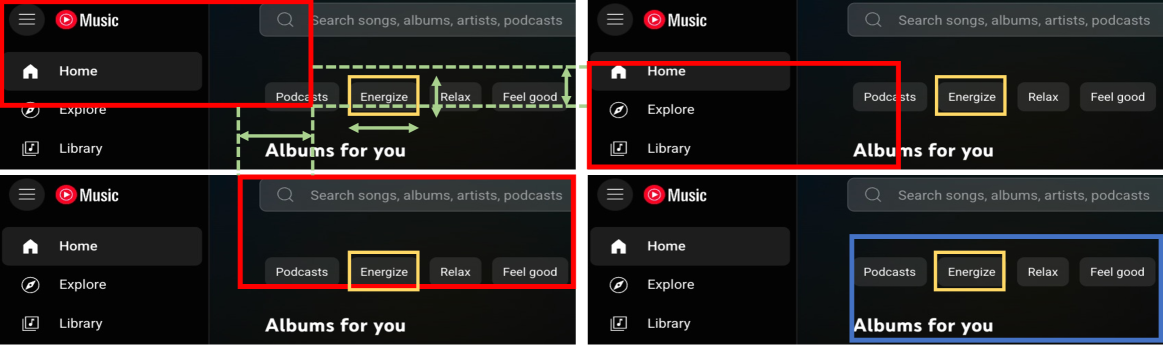
问题定义:现有GUI智能体在复杂GUI界面中的定位精度不足,尤其是在高分辨率显示器上。主要痛点包括:推理设计不合理导致定位不准确,稀疏奖励导致训练困难,以及视觉噪声干扰定位。
核心思路:UI-AGILE的核心思路是通过改进训练和推理两个阶段来提升GUI智能体的定位精度。在训练阶段,通过更有效的奖励机制和重采样策略来优化模型学习。在推理阶段,通过分解图像来降低定位难度。
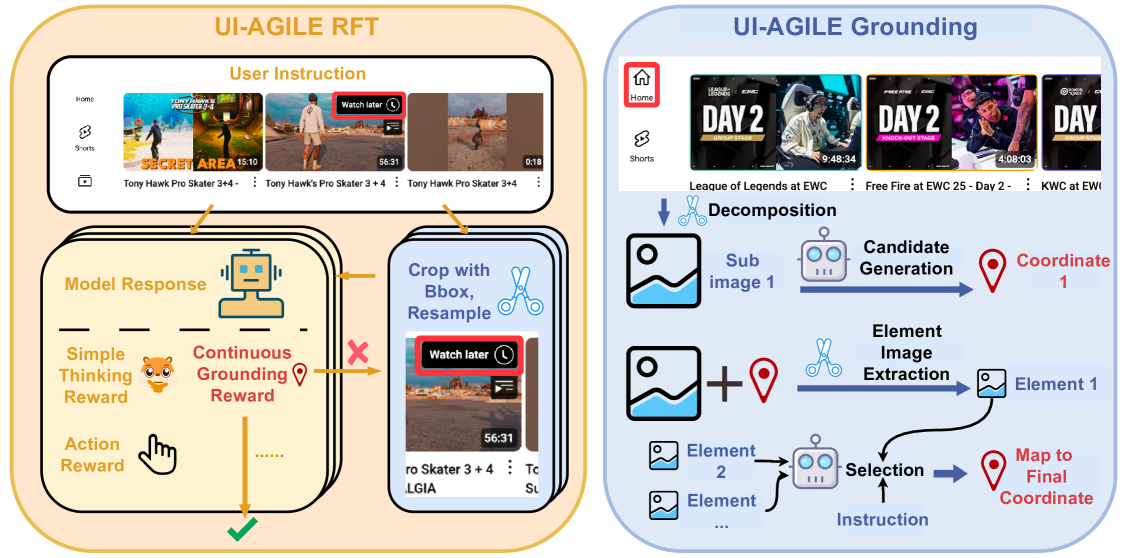
技术框架:UI-AGILE包含训练和推理两个主要阶段。训练阶段基于监督微调(SFT),并引入了连续奖励函数、简单思考奖励和裁剪重采样策略。推理阶段采用分解定位与选择策略,将高分辨率图像分解为小块进行处理。
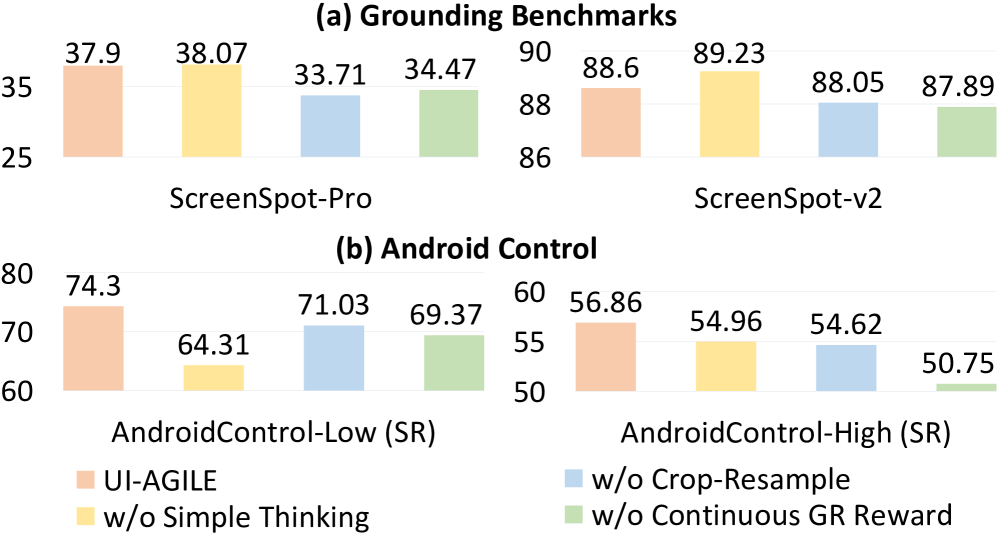
关键创新:UI-AGILE的关键创新在于:1)提出了连续奖励函数和简单思考奖励,更有效地指导模型学习;2)引入了裁剪重采样策略,缓解了稀疏奖励问题;3)提出了分解定位与选择策略,显著提高了高分辨率图像上的定位精度。
关键设计:连续奖励函数根据定位精度给出奖励,简单思考奖励平衡规划速度和定位精度,裁剪重采样策略通过裁剪图像来增加训练样本,分解定位与选择策略将图像分解为多个小块,分别进行定位,然后选择最可能的区域。
🖼️ 关键图片
📊 实验亮点
UI-AGILE在ScreenSpot-Pro和ScreenSpot-v2两个基准测试中取得了最先进的定位性能。在ScreenSpot-Pro上,UI-AGILE比最佳基线提高了23%的定位精度,证明了其在提升GUI智能体性能方面的有效性。
🎯 应用场景
UI-AGILE可应用于自动化测试、用户界面自动化、辅助技术等领域。通过提高GUI智能体的定位精度,可以实现更智能、更高效的人机交互,并为残障人士提供更好的辅助工具。未来,该技术有望应用于更复杂的GUI环境和任务中。
📄 摘要(原文)
The emergence of Multimodal Large Language Models (MLLMs) has driven significant advances in Graphical User Interface (GUI) agent capabilities. Nevertheless, existing GUI agent training and inference techniques still suffer from a dilemma for reasoning designs, ineffective reward, and visual noise. To address these issues, we introduce UI-AGILE for enhancing GUI agents at both training and inference. For training, we propose a suite of improvements to the Supervised Fine-Tuning (SFT) process: 1) a continuous reward function to incentivize high-precision grounding; 2) a ``Simple Thinking'' reward to balance planning with speed and grounding accuracy; and 3) a cropping-based resampling strategy to mitigate the sparse reward problem and improve learning on complex tasks. For inference, we present decomposed grounding with selection to dramatically improve grounding accuracy on high-resolution displays by breaking the image into smaller, manageable parts. Experiments show that UI-AGILE achieves the state-of-the-art grounding performance on two benchmarks ScreenSpot-Pro and ScreenSpot-v2 while it also exhibits strong general agent capabilities. For instance, using both our training and inference enhancement methods brings 23\% grounding accuracy improvement over the best baseline on ScreenSpot-Pro. We provide the code in https://github.com/KDEGroup/UI-AGILE.