Compression Strategies for Efficient Multimodal LLMs in Medical Contexts
作者: Tanvir A. Khan, Aranya Saha, Ismam N. Swapnil, Mohammad A. Haque
分类: cs.AI
发布日期: 2025-07-29 (更新: 2025-09-23)
备注: 16 pages, 7 figures
💡 一句话要点
针对医疗场景,提出高效压缩策略优化多模态LLM,降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 模型压缩 结构化剪枝 激活感知量化 医疗应用
📋 核心要点
- 医疗领域MLLM应用潜力巨大,但计算成本是主要瓶颈,需要有效的模型压缩方法。
- 提出一种新颖的层选择剪枝方法,并结合激活感知量化,优化模型压缩流程。
- 实验结果表明,该方法在显著降低内存占用的同时,还能提升模型性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)在医疗领域具有巨大的应用潜力,但其计算成本高昂,需要高效的压缩技术。本文评估了结构化剪枝和激活感知量化对微调后的LLAVA模型在医疗应用中的影响。我们提出了一种新颖的层选择剪枝方法,分析了不同的量化技术,并评估了在剪枝-SFT-量化流程中的性能权衡。我们提出的方法使具有70亿参数的MLLM能够在4 GB的VRAM中运行,与相同压缩比下的传统剪枝和量化技术相比,内存使用量减少了70%,同时模型性能提高了4%。
🔬 方法详解
问题定义:医疗领域的多模态大型语言模型(MLLM)由于参数量巨大,计算资源需求高,难以在资源受限的环境中部署。现有的模型压缩方法,如传统的剪枝和量化,在压缩率较高时往往会导致模型性能显著下降,无法满足医疗应用对模型准确性的要求。
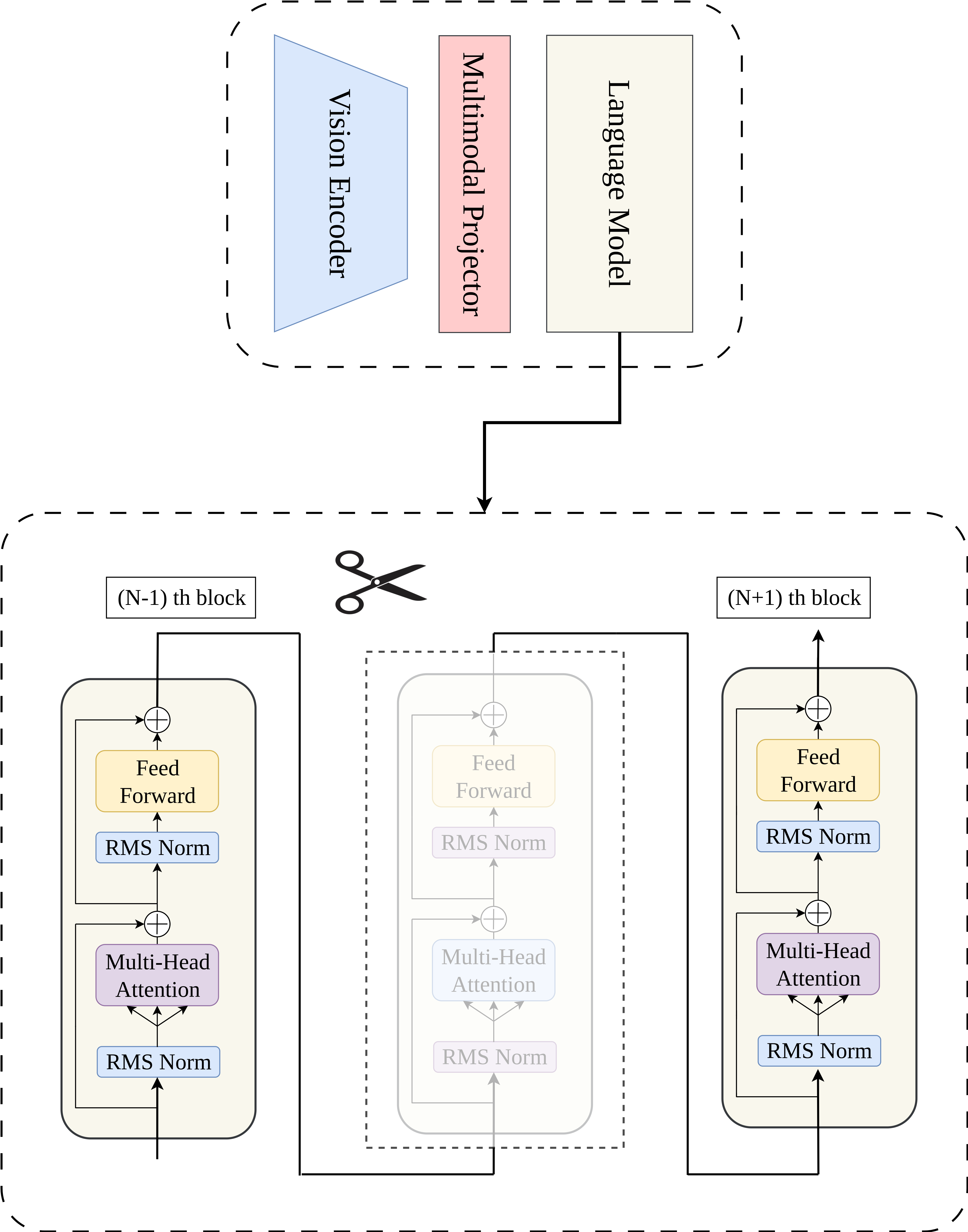
核心思路:本文的核心思路是通过结合结构化剪枝和激活感知量化,并在剪枝过程中采用一种新颖的层选择方法,以在模型压缩的同时尽可能地保留模型性能。这种方法旨在找到模型中冗余度最高的层进行剪枝,并利用激活感知量化进一步降低模型大小,从而实现高效的模型压缩。
技术框架:该方法采用一个三阶段的压缩流程:首先,使用提出的层选择方法进行结构化剪枝,移除模型中不重要的连接;然后,进行微调(SFT,Supervised Fine-Tuning),以恢复剪枝后模型的性能;最后,应用激活感知量化,将模型的权重和激活值量化到较低的精度,进一步压缩模型大小。
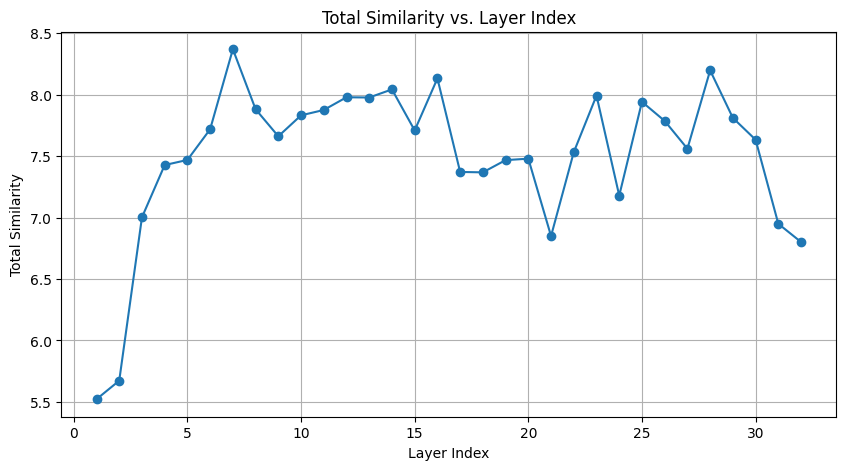
关键创新:该方法最重要的创新点在于提出了一种新颖的层选择剪枝方法。该方法通过分析每一层对模型性能的影响,选择对性能影响最小的层进行剪枝,从而在保证模型性能的前提下实现更高的压缩率。与传统的剪枝方法相比,该方法能够更有效地识别和移除模型中的冗余参数。
关键设计:在层选择剪枝中,论文提出了一种基于层重要性评分的策略,该评分考虑了每一层对模型输出的影响。具体来说,通过计算每一层输出的梯度范数来评估其重要性。在激活感知量化中,论文探索了不同的量化策略,包括对称量化和非对称量化,并选择能够最大程度地保留模型性能的量化方案。此外,论文还对剪枝率和量化比特数等关键参数进行了细致的调整和优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够将具有70亿参数的LLAVA模型压缩到4 GB的VRAM中运行,内存使用量减少了70%。同时,与传统的剪枝和量化技术相比,模型性能提高了4%。这些结果表明,该方法能够在显著降低计算成本的同时,保持甚至提升模型性能。
🎯 应用场景
该研究成果可应用于医疗影像诊断、辅助诊疗决策、医学知识问答等领域。通过降低MLLM的计算成本,使其能够在资源受限的医疗环境中部署,例如移动医疗设备、基层医疗机构等,从而提高医疗服务的可及性和效率。未来,该技术有望促进人工智能在医疗领域的更广泛应用。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) hold huge potential for usage in the medical domain, but their computational costs necessitate efficient compression techniques. This paper evaluates the impact of structural pruning and activation-aware quantization on a fine-tuned LLAVA model for medical applications. We propose a novel layer selection method for pruning, analyze different quantization techniques, and assess the performance trade-offs in a prune-SFT-quantize pipeline. Our proposed method enables MLLMs with 7B parameters to run within 4 GB of VRAM, reducing memory usage by 70% while achieving 4% higher model performance compared to traditional pruning and quantization techniques in the same compression ratio.