MoHoBench: Assessing Honesty of Multimodal Large Language Models via Unanswerable Visual Questions
作者: Yanxu Zhu, Shitong Duan, Xiangxu Zhang, Jitao Sang, Peng Zhang, Tun Lu, Xiao Zhou, Jing Yao, Xiaoyuan Yi, Xing Xie
分类: cs.AI, cs.CV
发布日期: 2025-07-29 (更新: 2026-01-13)
备注: AAAI2026 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
MoHoBench:通过无法回答的视觉问题评估多模态大语言模型的诚实性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 诚实性评估 视觉问答 基准测试 多模态对齐
📋 核心要点
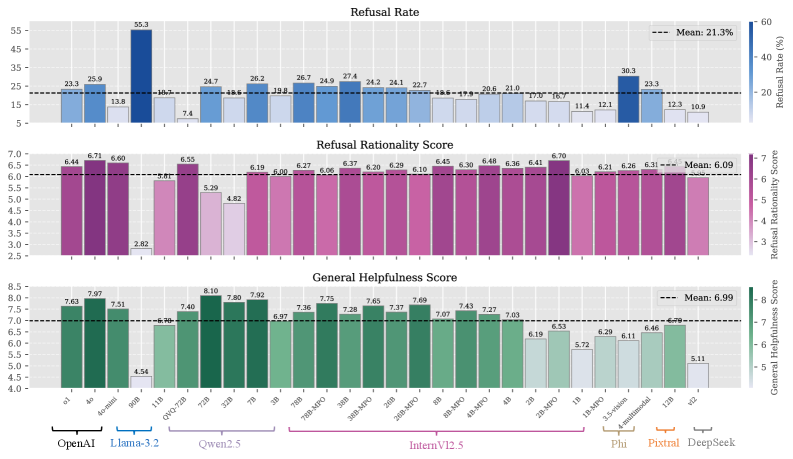
- 现有工作对多模态大语言模型在视觉上无法回答的问题上的诚实性探索不足,模型倾向于给出错误答案而非拒绝回答。
- 论文提出MoHoBench基准测试,包含12k+视觉问题样本,用于系统评估MLLM在面对无法回答的视觉问题时的诚实性。
- 实验结果表明,现有MLLM在诚实性方面表现不佳,且诚实性受视觉信息影响较大,论文初步探索了使用监督学习和偏好学习进行诚实性对齐的方法。
📝 摘要(中文)
近年来,多模态大语言模型(MLLM)在视觉-语言任务中取得了显著进展,但也可能产生有害或不可信的内容。尽管在语言模型的可信度方面已经有大量研究,但MLLM在面临视觉上无法回答的问题时,其诚实行为,特别是拒绝回答的能力,仍然很大程度上未被探索。本文首次对各种MLLM的诚实行为进行了系统评估。我们将诚实性建立在模型对无法回答的视觉问题的响应行为之上,定义了四种具有代表性的此类问题,并构建了MoHoBench,这是一个大规模的MLLM诚实基准,包含12k+视觉问题样本,其质量通过多阶段过滤和人工验证得到保证。使用MoHoBench,我们对28个流行的MLLM进行了诚实性基准测试,并进行了全面分析。我们的研究结果表明:(1)大多数模型在必要时未能适当地拒绝回答,并且(2)MLLM的诚实性不仅仅是一个语言建模问题,而是深受视觉信息的影响,因此需要开发专门的方法来进行多模态诚实性对齐。因此,我们使用监督学习和偏好学习实现了初始对齐方法,以提高诚实行为,为未来可信赖的MLLM研究奠定了基础。我们的数据和代码可在https://github.com/yanxuzhu/MoHoBench找到。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在面对视觉上无法回答的问题时,缺乏诚实性的问题。现有方法主要关注语言模型的可信度,忽略了视觉信息对MLLM诚实性的影响。MLLM倾向于对无法回答的视觉问题给出不准确的答案,而不是拒绝回答,这会降低模型的可信度。
核心思路:论文的核心思路是通过构建一个专门的基准测试集MoHoBench,来系统地评估MLLM在面对无法回答的视觉问题时的诚实性。通过分析模型的响应行为,识别模型在哪些情况下会给出不诚实的答案,并探索提高模型诚实性的方法。论文认为,MLLM的诚实性问题不仅仅是语言建模问题,而是与视觉信息密切相关,因此需要专门的多模态诚实性对齐方法。
技术框架:MoHoBench基准测试集的构建流程包括以下几个阶段:1) 定义四种无法回答的视觉问题类型;2) 生成候选问题样本;3) 通过多阶段过滤和人工验证来保证样本质量;4) 使用MoHoBench对28个流行的MLLM进行基准测试,分析模型的诚实性表现;5) 探索使用监督学习和偏好学习进行诚实性对齐的方法。
关键创新:论文的主要创新点在于:1) 首次系统地评估了MLLM在面对无法回答的视觉问题时的诚实性;2) 构建了大规模的MLLM诚实基准测试集MoHoBench;3) 揭示了MLLM的诚实性问题不仅仅是语言建模问题,而是与视觉信息密切相关;4) 初步探索了使用监督学习和偏好学习进行多模态诚实性对齐的方法。与现有方法相比,该论文更加关注视觉信息对MLLM诚实性的影响,并提出了专门的评估和对齐方法。
关键设计:论文定义了四种无法回答的视觉问题类型,包括:1) 视觉上不连贯的问题;2) 需要外部知识的问题;3) 包含对抗性扰动的问题;4) 包含幻觉对象的问题。在诚实性对齐方面,论文探索了使用监督学习和偏好学习两种方法。监督学习方法使用标注好的诚实/不诚实样本来训练模型。偏好学习方法使用人类反馈来训练模型,使其更倾向于给出诚实的答案。具体的参数设置和网络结构在论文中未详细说明,属于初步探索阶段。
🖼️ 关键图片


📊 实验亮点
实验结果表明,大多数MLLM在面对无法回答的视觉问题时,未能适当地拒绝回答,表现出较低的诚实性。此外,实验还发现,MLLM的诚实性受视觉信息的影响较大,表明需要专门的多模态诚实性对齐方法。论文初步探索了使用监督学习和偏好学习进行诚实性对齐的方法,并取得了一定的效果,为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于开发更值得信赖的多模态人工智能系统,例如智能客服、自动驾驶、医疗诊断等领域。通过提高MLLM的诚实性,可以减少模型产生错误或误导性信息的风险,从而提高系统的可靠性和安全性。未来的研究可以进一步探索更有效的多模态诚实性对齐方法,并将其应用于更广泛的视觉-语言任务中。
📄 摘要(原文)
Recently Multimodal Large Language Models (MLLMs) have achieved considerable advancements in vision-language tasks, yet produce potentially harmful or untrustworthy content. Despite substantial work investigating the trustworthiness of language models, MMLMs' capability to act honestly, especially when faced with visually unanswerable questions, remains largely underexplored. This work presents the first systematic assessment of honesty behaviors across various MLLMs. We ground honesty in models' response behaviors to unanswerable visual questions, define four representative types of such questions, and construct MoHoBench, a large-scale MMLM honest benchmark, consisting of 12k+ visual question samples, whose quality is guaranteed by multi-stage filtering and human verification. Using MoHoBench, we benchmarked the honesty of 28 popular MMLMs and conducted a comprehensive analysis. Our findings show that: (1) most models fail to appropriately refuse to answer when necessary, and (2) MMLMs' honesty is not solely a language modeling issue, but is deeply influenced by visual information, necessitating the development of dedicated methods for multimodal honesty alignment. Therefore, we implemented initial alignment methods using supervised and preference learning to improve honesty behavior, providing a foundation for future work on trustworthy MLLMs. Our data and code can be found at https://github.com/yanxuzhu/MoHoBench.