An analysis of AI Decision under Risk: Prospect theory emerges in Large Language Models
作者: Kenneth Payne
分类: cs.AI, cs.CL, cs.CY
发布日期: 2025-07-28
备注: 26 pages, 2 figures, 9 tables, 2 appendices
💡 一句话要点
首次验证:大型语言模型在风险决策中表现出前景理论偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 风险决策 前景理论 认知偏差 框架效应
📋 核心要点
- 人类在风险决策中存在非理性偏差,即前景理论,现有研究缺乏对大型语言模型(LLM)是否也存在类似偏差的探索。
- 该研究的核心思想是测试LLM在不同风险场景下的决策行为,并分析其是否符合前景理论的预测,关注框架效应的影响。
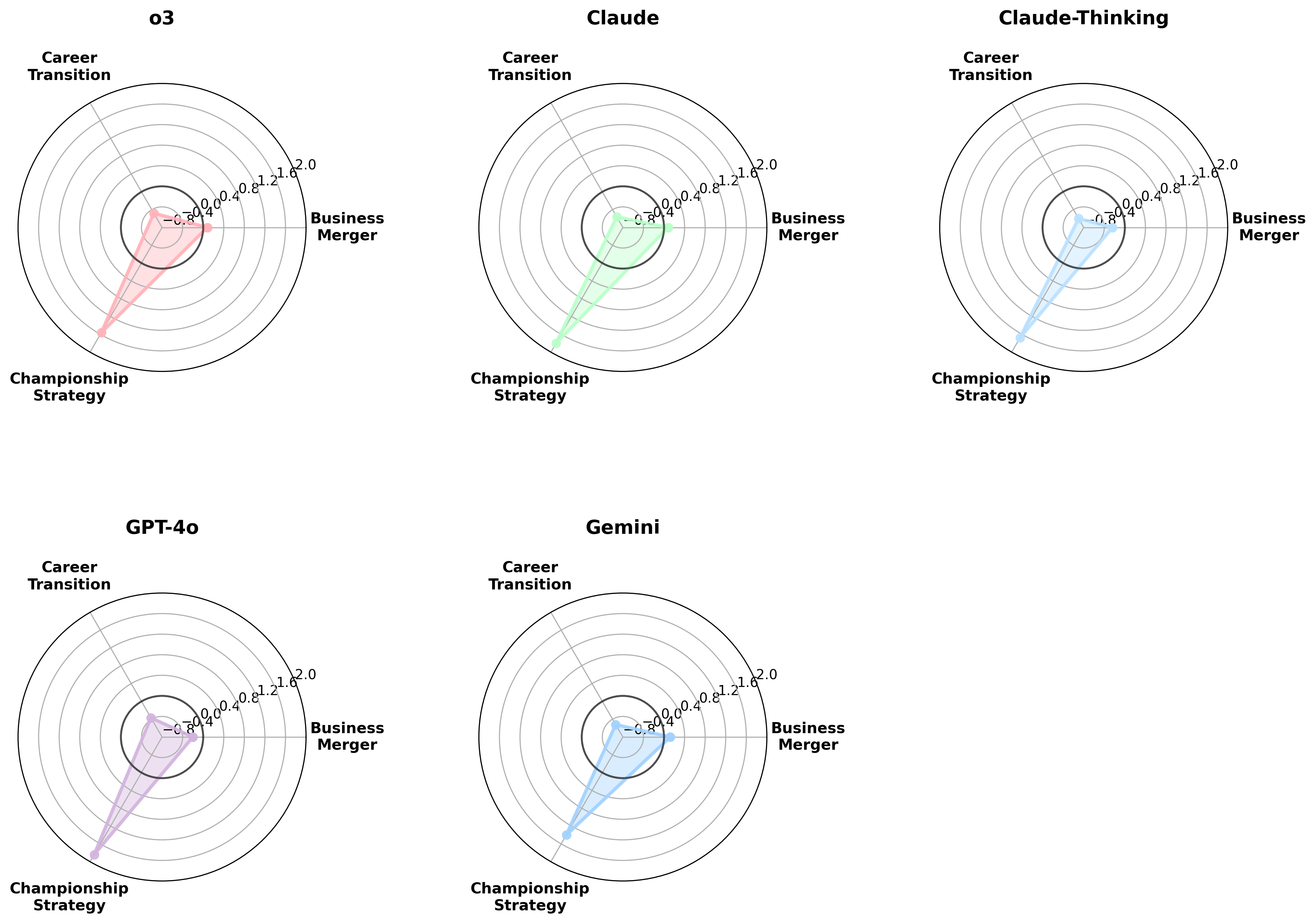
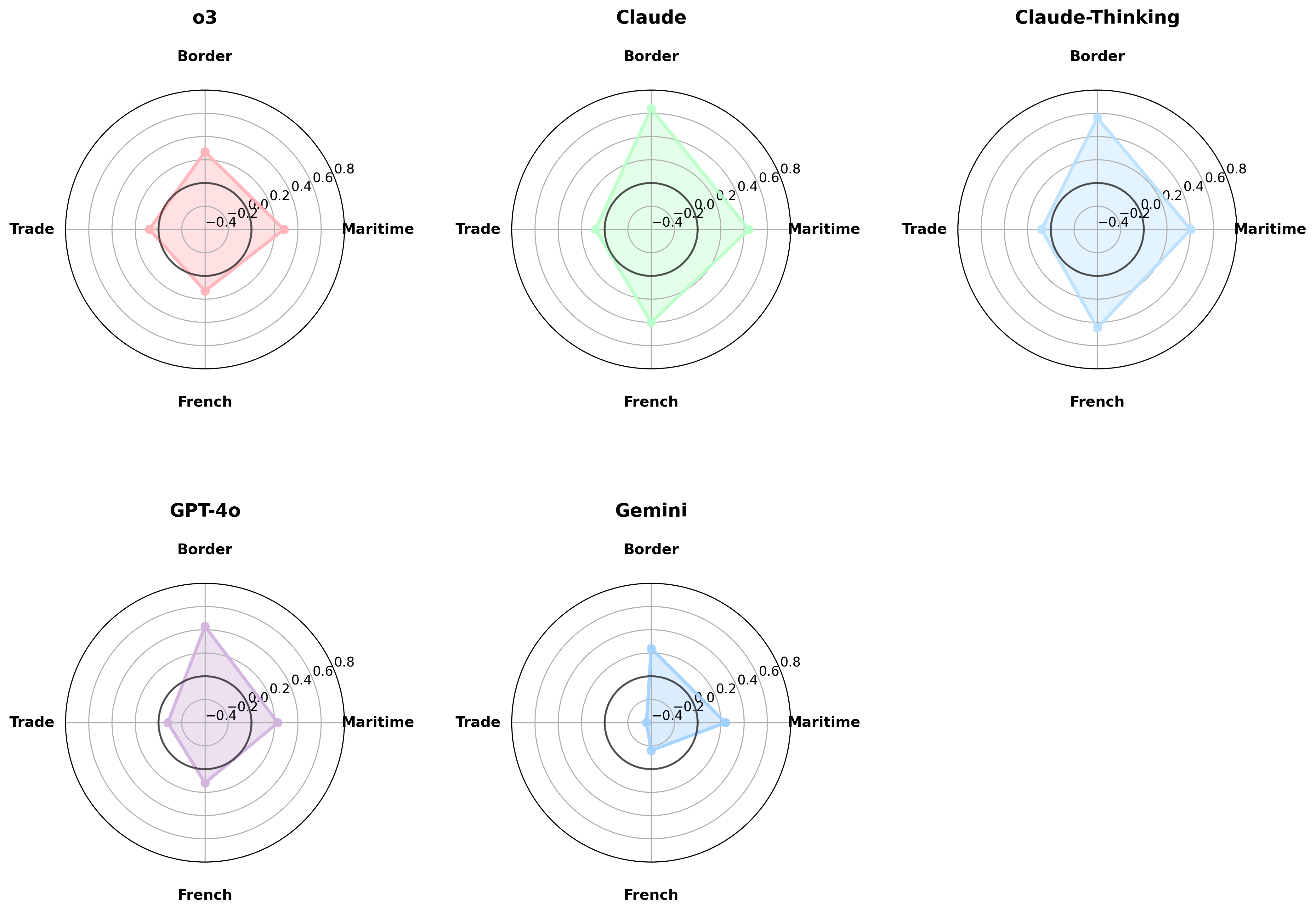
- 实验结果表明,LLM在风险决策中表现出与人类相似的前景理论偏差,且军事场景比民用场景产生更大的框架效应。
📝 摘要(中文)
风险判断是不确定性下决策的关键。正如Daniel Kahneman和Amos Tversky的著名发现,人类的风险判断方式与数学理性主义不同。具体来说,他们通过实验证明,当人们感到自己面临损失风险时,比可能获得收益时更能接受风险。本文报告了首次使用大型语言模型(包括当前最先进的思维链“推理器”)对Kahneman和Tversky的里程碑式“前景理论”进行的测试。与人类相似,我发现前景理论通常可以预测这些模型如何处理一系列场景中的风险决策。我还证明了上下文是解释风险偏好差异的关键。风险被理解的“框架”似乎嵌入在模型所处理的场景的语言中。具体来说,我发现军事场景比民用环境产生更大的“框架效应”。因此,我的研究表明,语言模型模拟了世界,捕捉了我们人类的启发式和偏见。但这些偏见是不均衡的——“框架”的概念比简单的收益和损失更丰富。维特根斯坦的“语言游戏”概念解释了由这些场景激活的偶然的、局部的偏见。最后,我用我的发现来重新构建关于LLM中推理和记忆的持续辩论。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在风险决策中是否表现出与人类相似的非理性偏差,即前景理论。现有方法缺乏对LLM风险决策行为的系统性分析,无法确定LLM是否受到人类认知偏差的影响。
核心思路:论文的核心思路是借鉴心理学中用于验证前景理论的实验范式,设计一系列风险决策场景,并观察LLM在这些场景下的选择行为。通过分析LLM的选择结果,判断其是否符合前景理论的预测,从而揭示LLM是否具有与人类相似的风险偏好偏差。
技术框架:该研究的技术框架主要包括以下几个步骤:1. 设计风险决策场景,包括收益和损失两种框架;2. 使用不同的LLM(包括思维链模型)对这些场景进行推理和决策;3. 分析LLM的决策结果,计算其风险偏好指标;4. 比较LLM在不同框架下的风险偏好,验证其是否符合前景理论的预测;5. 分析不同类型场景(如军事和民用)对框架效应的影响。
关键创新:该研究最重要的技术创新点在于首次将心理学中的前景理论应用于分析LLM的决策行为,揭示了LLM可能存在的认知偏差。与现有方法相比,该研究不仅关注LLM的推理能力,更关注其决策过程中的非理性因素。
关键设计:关键设计包括:1. 风险决策场景的设计,需要确保场景的真实性和可理解性,并能够有效区分不同的风险偏好;2. LLM的选择,需要考虑不同模型的架构和训练数据,以评估不同模型对风险的敏感程度;3. 风险偏好指标的计算,需要选择合适的指标来量化LLM的风险偏好,并进行统计分析。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在风险决策中表现出与人类相似的前景理论偏差,例如在损失框架下更倾向于冒险。此外,军事场景比民用场景产生更大的框架效应,表明LLM的风险偏好受到场景上下文的影响。这些发现为理解LLM的决策机制提供了新的视角。
🎯 应用场景
该研究的潜在应用领域包括:AI安全、AI伦理、人机协作等。理解LLM的认知偏差有助于开发更安全、更可靠的AI系统,避免AI在关键决策中受到非理性因素的影响。此外,该研究还可以为人机协作提供参考,帮助人类更好地理解和信任AI系统。
📄 摘要(原文)
Judgment of risk is key to decision-making under uncertainty. As Daniel Kahneman and Amos Tversky famously discovered, humans do so in a distinctive way that departs from mathematical rationalism. Specifically, they demonstrated experimentally that humans accept more risk when they feel themselves at risk of losing something than when they might gain. I report the first tests of Kahneman and Tversky's landmark 'prospect theory' with Large Language Models, including today's state of the art chain-of-thought 'reasoners'. In common with humans, I find that prospect theory often anticipates how these models approach risky decisions across a range of scenarios. I also demonstrate that context is key to explaining much of the variance in risk appetite. The 'frame' through which risk is apprehended appears to be embedded within the language of the scenarios tackled by the models. Specifically, I find that military scenarios generate far larger 'framing effects' than do civilian settings, ceteris paribus. My research suggests, therefore, that language models the world, capturing our human heuristics and biases. But also that these biases are uneven - the idea of a 'frame' is richer than simple gains and losses. Wittgenstein's notion of 'language games' explains the contingent, localised biases activated by these scenarios. Finally, I use my findings to reframe the ongoing debate about reasoning and memorisation in LLMs.