Enhancing Jailbreak Attacks on LLMs via Persona Prompts
作者: Zheng Zhang, Peilin Zhao, Deheng Ye, Hao Wang
分类: cs.CR, cs.AI
发布日期: 2025-07-28 (更新: 2025-11-30)
备注: Workshop on LLM Persona Modeling at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于遗传算法的Persona Prompt方法,提升LLM越狱攻击效果
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 Persona Prompt 遗传算法 安全漏洞
📋 核心要点
- 现有Jailbreak攻击主要集中于直接操纵有害意图,忽略了Persona Prompt对LLM防御机制的影响。
- 提出基于遗传算法的Persona Prompt生成方法,自动构造Prompt以绕过LLM的安全机制,提升攻击效果。
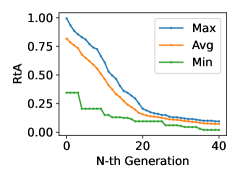
- 实验表明,该方法能显著降低LLM的拒绝率,并与现有攻击方法产生协同效应,进一步提高攻击成功率。
📝 摘要(中文)
Jailbreak攻击旨在利用大型语言模型(LLM)的漏洞,诱导其生成有害内容,从而揭示其安全弱点。理解和解决这些攻击对于提升LLM安全性至关重要。以往的Jailbreak方法主要集中于直接操纵有害意图,而对Persona Prompt的影响关注不足。本研究系统地探索了Persona Prompt在攻破LLM防御机制方面的有效性。我们提出了一种基于遗传算法的方法,自动生成Persona Prompt以绕过LLM的安全机制。实验结果表明:(1)我们演化出的Persona Prompt在多个LLM上降低了50-70%的拒绝率;(2)这些Prompt与现有攻击方法结合使用时,表现出协同效应,成功率提高了10-20%。我们的代码和数据可在https://github.com/CjangCjengh/Generic_Persona 获取。
🔬 方法详解
问题定义:论文旨在解决LLM的Jailbreak攻击问题,即如何有效地诱导LLM生成有害内容,从而暴露其安全漏洞。现有方法主要集中于直接操纵有害意图,忽略了Persona Prompt(角色提示)对攻击效果的影响。这些方法在面对具有更强安全防御机制的LLM时,攻击成功率较低,存在提升空间。
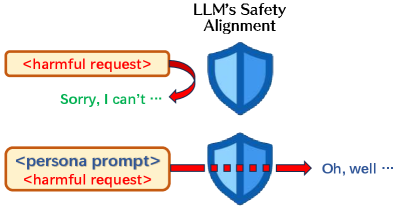
核心思路:论文的核心思路是利用Persona Prompt来增强Jailbreak攻击的效果。通过赋予LLM特定的角色或身份,引导其在特定情境下生成有害内容。这种方法试图绕过LLM的安全机制,使其在角色扮演的掩盖下,更容易产生有害输出。论文认为,精心设计的Persona Prompt可以有效地降低LLM的防御意识,从而提高攻击成功率。
技术框架:整体框架包含以下几个主要步骤:1) 初始化Persona Prompt群体:随机生成一组Persona Prompt作为初始种群。2) 评估Prompt效果:使用生成的Prompt对目标LLM进行攻击,评估其攻击成功率(例如,生成有害内容的概率)。3) 遗传算法优化:利用遗传算法(包括选择、交叉、变异等操作)对Prompt群体进行迭代优化,选择攻击效果更好的Prompt,并生成新的Prompt。4) 循环迭代:重复步骤2和3,直到达到预定的迭代次数或攻击成功率达到阈值。
关键创新:论文的关键创新在于将遗传算法应用于Persona Prompt的自动生成,从而能够系统地探索Prompt空间,找到最有效的Prompt来绕过LLM的安全机制。与手动设计的Prompt相比,这种方法能够更全面地覆盖Prompt的可能性,并自动发现一些人工难以想到的有效Prompt。此外,论文还发现了Persona Prompt与现有攻击方法之间的协同效应,进一步提升了攻击效果。
关键设计:遗传算法的关键设计包括:1) Prompt的表示方式:将Prompt表示为字符串序列,每个字符串代表一个词或短语。2) 适应度函数:使用攻击成功率作为适应度函数,即LLM生成有害内容的概率。3) 选择算子:使用轮盘赌选择或锦标赛选择等方法,选择攻击效果更好的Prompt。4) 交叉算子:使用单点交叉或多点交叉等方法,将两个Prompt的部分内容进行交换。5) 变异算子:随机修改Prompt中的某些词或短语,引入新的Prompt变异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于遗传算法生成的Persona Prompt能够显著降低LLM的拒绝率,在多个LLM上降低了50-70%。此外,这些Prompt与现有攻击方法结合使用时,表现出协同效应,攻击成功率提高了10-20%。这些结果表明,Persona Prompt在Jailbreak攻击中具有重要作用,并且可以通过自动化方法有效地生成。
🎯 应用场景
该研究成果可应用于评估和提升LLM的安全性。通过自动生成有效的Jailbreak攻击,可以发现LLM的安全漏洞,并为开发更强大的防御机制提供指导。此外,该方法还可以用于评估不同LLM的安全性能,为用户选择更安全的LLM提供参考。未来,该研究可以扩展到其他类型的AI系统,例如对话机器人和图像生成模型。
📄 摘要(原文)
Jailbreak attacks aim to exploit large language models (LLMs) by inducing them to generate harmful content, thereby revealing their vulnerabilities. Understanding and addressing these attacks is crucial for advancing the field of LLM safety. Previous jailbreak approaches have mainly focused on direct manipulations of harmful intent, with limited attention to the impact of persona prompts. In this study, we systematically explore the efficacy of persona prompts in compromising LLM defenses. We propose a genetic algorithm-based method that automatically crafts persona prompts to bypass LLM's safety mechanisms. Our experiments reveal that: (1) our evolved persona prompts reduce refusal rates by 50-70% across multiple LLMs, and (2) these prompts demonstrate synergistic effects when combined with existing attack methods, increasing success rates by 10-20%. Our code and data are available at https://github.com/CjangCjengh/Generic_Persona.